0から1へのバックエンドアーキテクチャ構築の進化(MVC、サービス分割、マイクロサービス、ドメインドリブン)
製品は人事のSaaSオンラインサービスで、人事Web Android/iOSアプレット用の複数のクライアントを持つ
バックエンドはRESTfulスタイルのAPIを使用してサービスを提供します。主にPython言語を使用し、高速なイテレーションを容易にします。
アーキテクチャは、大きく分けて4つのフェーズを経て進化してきました。
I. MVC
プロジェクト開始当初は、バックエンドの同僚は5人もおらず、この段階では、アーキテクチャをあまり考慮せずに製品のプロトタイプを実装することが主な仕事であった
Django を使って素早く機能を実装し、DB のテーブル構造を設計し、機能的な View を抽象化しました。
製品設計も不完全なため、製品ロジックの変更によりテーブル構造全体が変更されないよう、バックエンドには多くの事前設計が必要です
このフェーズで最も重要なことは、チームに合ったコード仕様とコードチェックルールを決めることです。
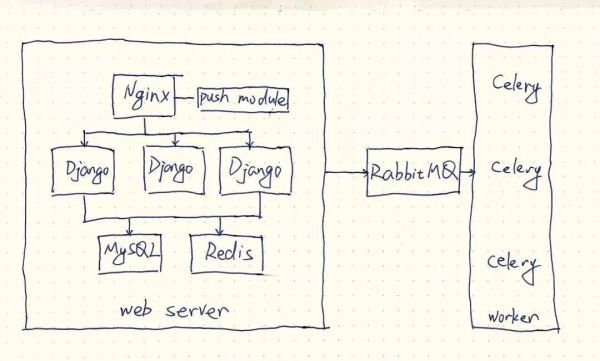
全体的なアーキテクチャは上記のとおりです。
- Nginx はロードバランシングと複数の Django サービスへのトラフィック分散を担当します。
- Djangoの処理ロジック
- 非同期タスクはCeleryに任せる
- データ量が多い場合はキャッシュにRedisを使用する
- リアルタイムメッセージ通知にはNginx Push Moduleも使用されている
問題点と最適化
- Django の並行処理性能の低さ
- uWSGI Master+Workerとgevent Ctripを使用すると、多数の高同時Redis接続がサポートされます。
- redis-pyを使用すると、MySQL接続を多重化するためのコネクションプールが付属しています。
- djorm-ext-poolを使用する( https://github.com/djangonauts/djorm-ext-pool ) 接続プールの再利用 接続 Celery を使用して、gevent が並行タスクをサポートするように設定します。
機能がどんどん開発されるにつれて、Django の下にあるアプリはどんどん増えていき、パブリッシングに不便をもたらすようになります。リリースのたびにすべての Django サービスを再起動する必要があり、リリースで問題が発生すると、それを解決するために残業する必要があります。そして、1つの Django プロジェクトの下にあるコードの量はどんどん大きくなり、メンテナンスが行き届かなくなります。
II. サービスの分割
バックエンドのチームが大きくなるにつれて、各同僚に分割される要件はどんどん細かくなっていく
1つのプロジェクトですべてのコードを開発し続けると、メンテナンスにコストがかかりすぎる
以前のアーキテクチャでは、すでにDjangoのモジュール単位のアプリがありました
アプリ内のクラスタリングが高く、アプリ間のカップリングが低いため、サービスの分割が容易です。
分割作業ではあまり問題が発生せず、最初の分割はコードの分離だけでした
共通のコードは抜き出して共通のPythonライブラリを実装し、データベースであるRedisはこれまで通り共有し、負荷の増加に合わせてデータベースのインスタンスを複数作成しました。
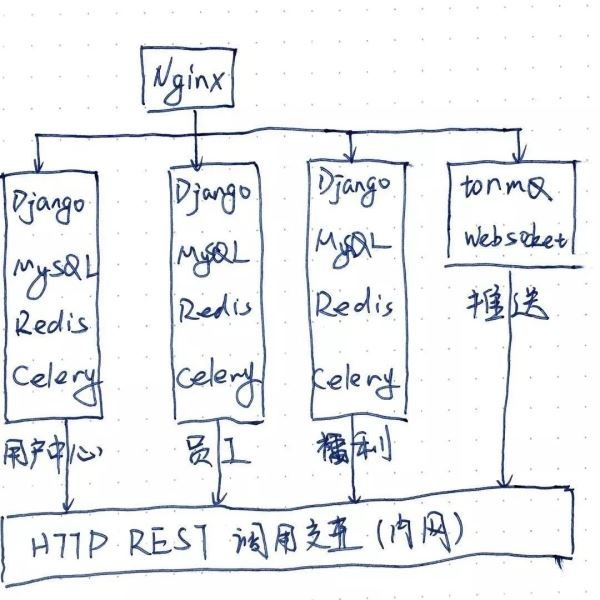
上に示したように、サービスは互いに呼び合うことを避け、対話が必要な場所ではhttpリクエストを使用し、イントラネットの呼び出しにはイントラネットのアドレスを指すホストを使用するようにしています。
問題と最適化のアプローチ
- Nginx Push Moduleは、長期間メンテナンスを行っていないため、長時間接続の最大数がありません。
- Tornado + ZeroMQでtormqを実装( https://github.com/zhu327/tormq ) サービスでメッセージ通知をサポート
- サービス間の呼び出しはhttpで行われ、依存するサービスのホストには、呼び出されるアドレスを指すように設定する必要があり、メンテナンスの面で不便をもたらす。
- で、コールチェーン中の再試行、エラー処理、フロー制限などの戦略がないため、サービスの可用性が低い。 ビジネス・アンバンドリングでは、Nginxを使い続けて設定を維持することは面倒であり、Nginxの設定変更による呼び出しエラーを誘発することが多い。
- 各サービスは完全な認証プロセスを持ち、その認証プロセスはユーザー中心のデータベースに依存しているため、認証を変更した場合、複数のサービスを再公開する必要がある。
III. マイクロサービス・アーキテクチャ
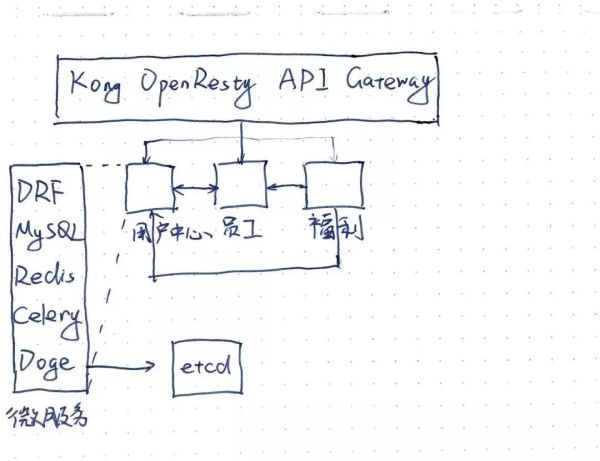
- 1つ目は、アクセス層にOpenRestyベースの「Kong API Gateway」を導入し、認証やフロー制限などのプラグインをカスタムで実装することです。
- アクセス層は、アプリケーション層の公開認証やフロー制限などの機能を引き継ぎ、ストリッピングしています。
- 新しいサービスを公開する際、公開スクリプトはKong admin apiを呼び出してKongにサービスアドレスを登録し、apiの読み込みにはプラグインを使用する必要があります。
相互呼び出しの問題を解決するために、gevent+msgpackをベースにRPCサービスフレームワークdodgeを整備し、etcdの助けを借りてサービスガバナンスを行い、rpcクライアントにフロー制限、高可用性、負荷分散などの機能を実装します。
- 現段階で最も難しい技術選定は、オープンソースのAPIゲートウェイで、主にGolangとOpenResty(lua)で実装されており、我々のビジネスニーズに合わせてカスタマイズする必要があることです。
- 1ヶ月かけてOpenRestyとGolangを学習し、OpenRestyを使って業務用のショートカールサービスを実装しました。
- 最終的にKongを選んだのは、Luaでの公開のしやすさ、Kongをそのまま使えること、プラグイン開発のしやすさなどが決め手となりました。
- 性能は最も重要な検討事項ではありません。より多くの同時実行をサポートするために、クラウドプラットフォームが提供するLBサービスを利用して、2台のKongサーバーのクラスタにトラフィックを分散させることも行っています。
- クラスタ間の設定自動同期
Hungryはthriftプロトコルフレームワークの純粋なPython実装であるthriftpyを保守し、多くのサポートツールを提供しています。チームが十分に大きければ、このRPCソリューションは実際に適切なのですが、私たちのチームは人員不足でレベルもバラバラなので、この学習コストのかかるソリューション全体をスケールアップするのは困難です。
結局、dogeというDubooライクなRPCフレームワークを開発し、コードは主にweiboのオープンソースであるmotanを参考にしました。
IV. ドメイン駆動型設計
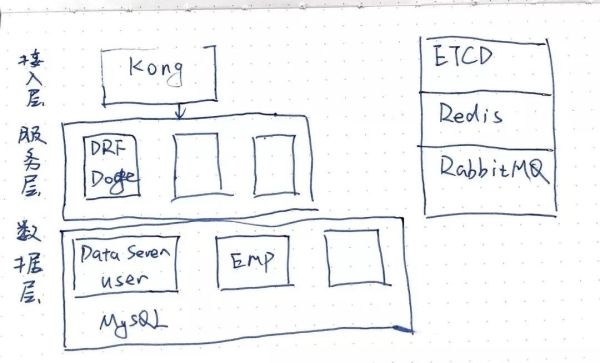
- このアーキテクチャでは、アプリケーションサービスからデータサービス層を抽象化しようとしています。
- 各データサービスには1つ以上のバウンディングコンテキストが含まれ、バウンディングコンテキストクラスはRPC呼び出し用のメソッドを公開するための1つのアグリゲーションルートのみを持つ。
- データサービスはアプリケーションサービスには依存せず、アプリケーションサービスは複数のデータサービスに依存することができます。
- データサービス層では、アプリケーションは互いに切り離され、高レベルのサービスは基礎となるサービスだけに依存します。
私が退社した時点では、ドメイン駆動設計はまだ学習設計の段階で、実装されていませんでしたが、私の前職の会社のバックエンドアーキテクチャは、今後もこの方向で進化していくことでしょう。
Service Meshのような次世代のマイクロサービスアーキテクチャが主流になりつつあり、私の仕事はもうマイクロサービスとは関係ありませんが、今後もマイクロサービスの勉強には力を入れていきたいと思います。
アーキテクチャの設計や技術の選定は、流行りの技術に追随することはできず、最終的には製品や顧客のニーズに応えるものです。設計の過程では、チームや人の構造上、妥協することが多く、その中で最適解を見つけることが最大の課題です。
関連
-
WordPressのヘッダーとフッターにコードを追加する方法
-
ゲーム開発Unity2D画像任意の形状壊れたローブ効果ショー
-
ブレンドシェイプスイッチによるUnityの表情変化 アニメーションチュートリアル
-
Unity開発VRプロジェクト問題概要分析
-
Scratch3.0 sb3ファイル読み込み時のページ初期化 操作コード
-
VSCodeでsshキー不要のサーバーへのリモートログインを行う方法
-
MACシステムIDEAフェイスプラグイン「MaterialThemeUI
-
WordPressのワンクリックで他のユーザーIDに切り替わるログイン機能方法
-
HTTP3の解析
-
vscodeの左エクステンションのアクティビティバーが消える問題とその解決方法
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
CookieのSameSiteプロパティの概要
-
MACシステムアップグレード後、仮想マシンがブラックスクリーンになる問題の解決
-
UnityでVR Storm Magic Mirror Bluetoothジョイスティックを使用する方法
-
パフォーマンステスト QPS+TPS+トランザクションの基本分析
-
Scratch 3.0二次開発。スクラッチブロックのブロックの種類、定義、使い方
-
VS Nugetの実践的な使い方
-
Unityプロジェクトの最適化に関するヒント
-
フィンドラーの携帯電話パケットキャプチャープロセスを実装するためのソフトウェアテスト
-
Unityアニメーションについて ステートマシン アニメーター活用術 チュートリアル
-
シェア ソフトウェアテストに必須のテストツール一覧のまとめ