[解決済み] サポートベクター数、学習データ数と分類器の性能の関係は?[クローズド]
質問
LibSVMを使って、いくつかのドキュメントを分類しています。最終的な結果が示すように、ドキュメントは分類するのが少し難しいようです。しかし、モデルを学習している間に気づいたことがあります。例えば学習セットが1000個だとすると、そのうち約800個がサポートベクターとして選択されているのです。 これが良いことなのか悪いことなのか、いろいろと調べてみました。つまり,サポートベクトルの数と分類器の性能の間には関係があるのでしょうか? 私はこれを読みました 前の記事 を読みましたが、私はパラメータ選択を行っており、また、特徴ベクトルの属性はすべて順序付けされていることを確認しています。 私はちょうど関係を知る必要があります。 ありがとうございます。 p.s: 私は線形カーネルを使用しています。
どのように解決するのですか?
サポートベクターマシンとは、最適化問題の一つです。2つのクラスを最大のマージンで分割する超平面を見つけようとします。 サポートベクターとは、このマージンの範囲内にある点のことです。 単純なものから複雑なものへと積み上げていくと、最も理解しやすいと思います。
ハードマージン型リニアSVM
データが線形分離可能な学習セットで、ハードマージン(緩みは許されない)を使用している場合、サポートベクトルはサポート超平面(マージンの端にある分割超平面に平行な超平面)に沿った点であると言えます。
すべてのサポートベクトルはマージン上に正確に位置しています。 次元数やデータセットの大きさに関係なく、サポートベクトルの数は2個程度になる可能性があります。
ソフトマージンリニアSVM
しかし、データセットが線形分離可能でない場合はどうでしょうか?そこで、ソフトマージンSVMを導入します。データポイントがマージンの外にあることを要求するのではなく、マージンの中にある線からはみ出ることをある程度許容するのです。この制御にはスラックパラメータCを用います。(これにより、マージンが広くなり、学習データセットでの誤差が大きくなりますが、汎化が向上し、線形分離できないデータの線形分離を見つけることができるようになります。
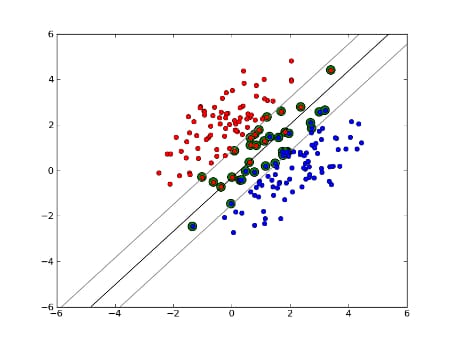
さて、サポートベクトルの数は、どれだけの弛みを許容するか、データの分布に依存します。もし、大きな弛みを許せば、多くのサポートベクトルを持つことになります。 一方、弛みをほとんど許さない場合は、サポートベクトルの数は非常に少なくなります。精度は、分析するデータに対して適切な緩みを見つけることに依存する。データによっては、高い精度を得ることができないので、単純にできる限り最適なものを見つける必要があります。
非線型SVM
ここで、非線形SVMを紹介します。私たちはまだデータを線形に分割しようとしていますが、今度はより高い次元の空間でそれを行おうとしているのです。 これはカーネル関数によって行われ、カーネル関数はもちろんそれ自身のパラメータのセットを持っています。これを元の特徴空間に戻すと、結果は非線型になります。
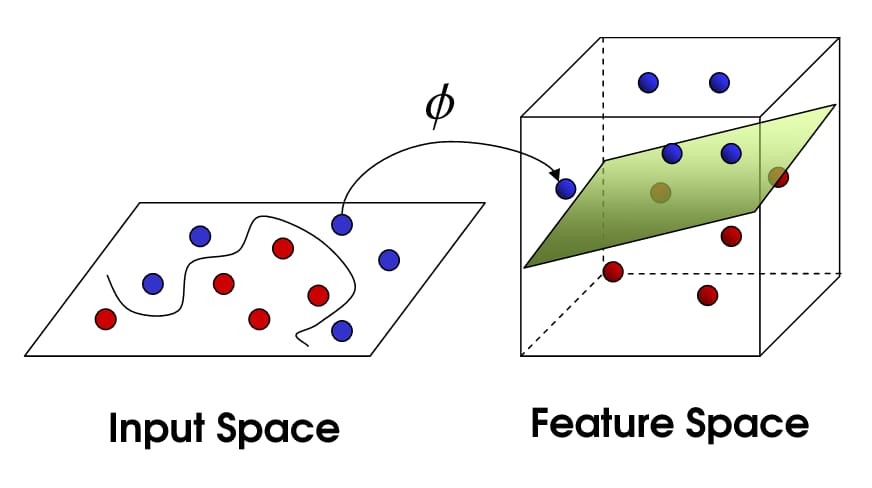
さて、サポートベクトルの数は、まだ、どれだけの緩みを許容するかに依存しますが、それはまた、私たちのモデルの複雑さにも依存します。入力空間における最終的なモデルのそれぞれのねじれや曲がりは、定義するために 1 つ以上のサポート ベクトルを必要とします。 最終的に、SVMの出力はサポートベクトルとアルファであり、これは要するに、特定のサポートベクトルが最終的な判断にどれだけ影響を与えるかを定義しているのです。
ここで,精度はデータに過剰適合する可能性のある高複雑モデルと,より良い汎化のために学習データの一部を誤って分類することになる大きなマージンとの間のトレードオフに依存します. サポートベクトルの数は非常に少ないものから、データを完全にオーバーフィットさせる場合にはすべてのデータポイントに及ぶ可能性があります。 このトレードオフはC言語とカーネルおよびカーネルパラメータの選択によって制御されます。
あなたがパフォーマンスと言ったとき、あなたは精度に言及していると思いますが、私は計算の複雑さの点でもパフォーマンスについて話すと思いました。 SVM モデルを使用してデータ点をテストするために、各サポート ベクトルとテスト点の内積を計算する必要があります。したがって、モデルの計算複雑度はサポートベクトルの数に比例します。 サポートベクトルが少なければ、テストポイントの分類も早くなります。
良い資料です。 パターン認識のためのサポートベクターマシンに関するチュートリアル
関連
-
[解決済み] RuntimeError: 次元が範囲外([-1, 0]の範囲にあると期待されたが、1が得られた)
-
[解決済み] コスト関数、線形回帰、シータをハードコーディングしないようにする。オクターブ
-
[解決済み] ロジットとは何ですか?softmaxとsoftmax_cross_entropy_with_logitsの違いは何ですか?
-
[解決済み】機械学習モデルの損失と精度の解釈の仕方【終了しました
-
[解決済み] フィーチャーとラベルの違いは何ですか?[クローズド]
-
[解決済み] なぜFメジャーはPrecisionとRecallの算術平均ではなく調和平均なのですか?
-
[解決済み] word2vec: ネガティブサンプリング(平たく言うと)?
-
[解決済み] トレーニング中のナンの原因
-
[解決済み] Keras カーネル・レギュラライザーとアクティビティ・レギュラライザーの違い
-
[解決済み] 機械学習とは?[終了しました]
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】Keras - KerasRegressorを使用して予測を実行する方法は?
-
[解決済み] Kerasにおける "Flatten "の役割とは?
-
[解決済み] kerasのtrain_on_batch()の使い道は?
-
[解決済み】機械学習モデルの損失と精度の解釈の仕方【終了しました
-
[解決済み] なぜ人工ニューラルネットワークの入力を正規化する必要があるのですか?[クローズド]
-
[解決済み] Diablo 2をプレイするための人工ニューラルネットワークを視覚的に学習させる方法とは?
-
[解決済み] Appleはどのように電子メールの日付、時間、アドレスを見つけるのですか?
-
[解決済み] 期待値最大化手法の直感的な説明とは?[クローズド]
-
[解決済み] クロスエントロピーとは?[クローズド]
-
[解決済み] 多層パーセプトロン(MLP)アーキテクチャ:隠れ層の数とサイズを選択する基準?[クローズド]