[解決済み] なぜFメジャーはPrecisionとRecallの算術平均ではなく調和平均なのですか?
質問
PrecisionとRecallの両方を考慮したF-Measureを計算する場合、単純な算術平均ではなく、2つの尺度の調和平均をとります。
単純な平均ではなく、調和平均を取ることの直感的な理由は何ですか?
どのように解決するのですか?
ここでは、すでにいくつかの詳細な回答がありますが、私はそれについてのいくつかのより多くの情報は、深く掘り下げたい人のために役立つだろうと思った(特になぜFメジャー)。
測定の理論によると、複合尺は以下の6つの定義を満たす必要があります。
- 連結性(2つの組が順序付けられる)および推移性(もしe1 >= e2およびe2 >= e3なら、e1 >= e3)
- 独立性:2つの成分が独立して効果に寄与する。
- トムセン条件。一定のリコール(精度)において、2つの値の精度(リコール)に対して有効性に差があるとすると、この差は一定の値を変えることによって取り除いたり、元に戻したりすることはできない。
- 制限された解決可能性。
- 各コンポーネントは必須です。他を一定にしたまま、一方を変化させることで、効果に変化を与える。
- 各コンポーネントのアルキメデス的性質。これは単に、コンポーネント上の間隔が同等であることを保証するものです。
次に、私たちは
を導出し
の関数を得ることができる。
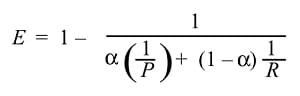
また、通常は有効性ではなく、より単純なFスコアを使用します。
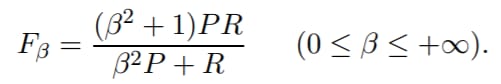
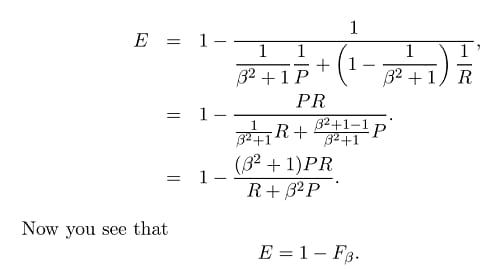
さて、ここでF測定の一般式をとります。
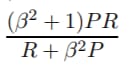
ここで、βを設定することで再現性や精度をより重視することができますが、βは以下のように定義されるからです。

もし私たちが精度よりもリコールを重要視するならば(すべての関連するものが選択される)、ベータを2として設定することができ、F2メジャーを得ることができます。また、逆にして、精度を想起よりも高く評価する場合 (たとえば、次のような文法エラー修正シナリオでは、選択された要素ができるだけ多く関連します)、ベータを 2 に設定することができます。 CoNLL のような文法エラー修正シナリオのように)ベータを0.5として設定し、F0.5指標を得ます。そして、明らかに、最も使用されるF1指標(精度とリコールの調和平均)を得るために、ベータを1に設定することができます。
なぜ算術平均を使用しないか、ある程度はすでに答えられたと思います。
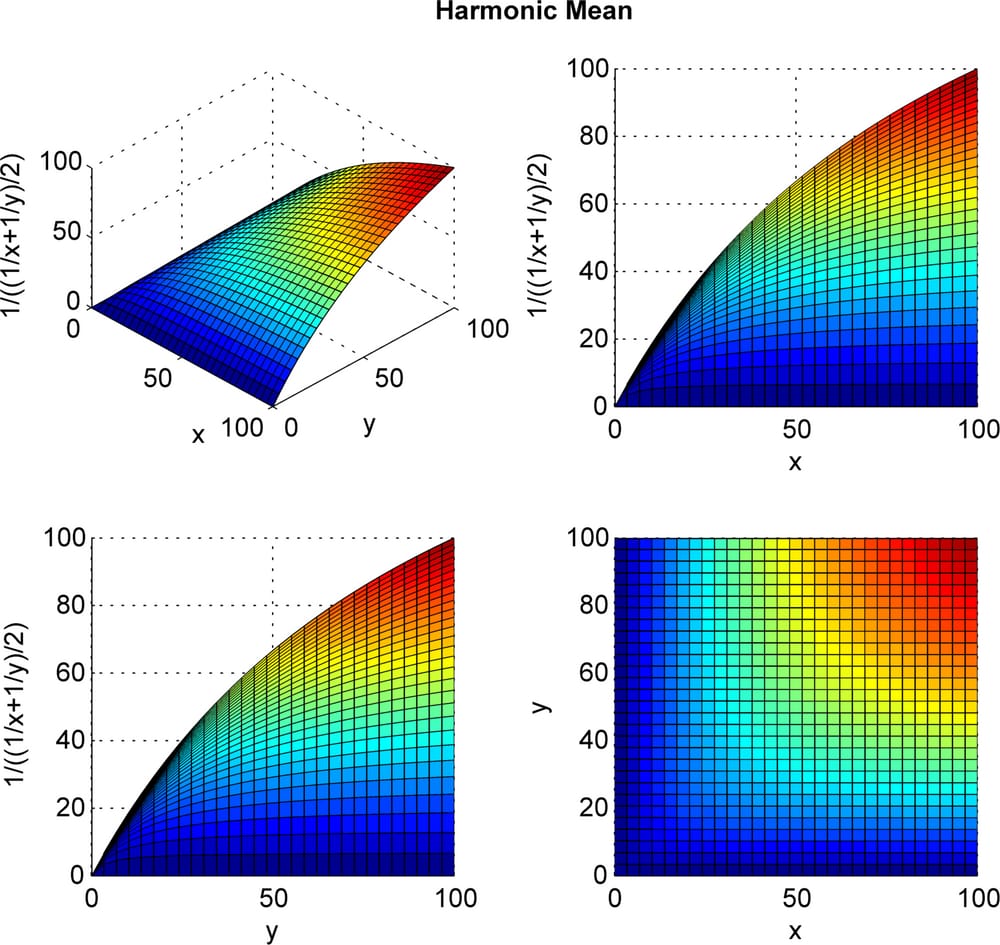
調和平均の3Dプロットを見てみましょう。調和平均は最低値に対して敏感であることがわかります。特に調和平均は少なくとも1つが0であれば0となり、単純な算術平均では成り立たないことがわかります。
このトピックの可視化については、こちらの記事を参照してください。 F1スコアの説明 .
参考文献を紹介します。
関連
-
[解決済み] RuntimeError: 次元が範囲外([-1, 0]の範囲にあると期待されたが、1が得られた)
-
[解決済み] エアフローとKubeflowパイプラインの違いは何ですか?
-
[解決済み] コスト関数、線形回帰、シータをハードコーディングしないようにする。オクターブ
-
[解決済み] kerasのtrain_on_batch()の使い道は?
-
[解決済み】線形回帰とロジスティック回帰の違いは何ですか?[クローズド]
-
[解決済み】同じ問題で binary_crossentropy と categorical_crossentropy が異なる性能を示すのはなぜか?
-
[解決済み】教師あり学習と教師なし学習の違いは何ですか?[終了しました]
-
[解決済み】機械学習モデルの損失と精度の解釈の仕方【終了しました
-
[解決済み] Appleはどのように電子メールの日付、時間、アドレスを見つけるのですか?
-
[解決済み] なぜFメジャーはPrecisionとRecallの算術平均ではなく調和平均なのですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】Keras - KerasRegressorを使用して予測を実行する方法は?
-
[解決済み] RuntimeError: 次元が範囲外([-1, 0]の範囲にあると期待されたが、1が得られた)
-
[解決済み] イプシロン貪欲q学習におけるイプシロンと学習率の減衰について
-
[解決済み] エアフローとKubeflowパイプラインの違いは何ですか?
-
[解決済み] コスト関数、線形回帰、シータをハードコーディングしないようにする。オクターブ
-
[解決済み】教師あり学習と教師なし学習の違いは何ですか?[終了しました]
-
[解決済み】機械学習モデルの損失と精度の解釈の仕方【終了しました
-
[解決済み] なぜ人工ニューラルネットワークの入力を正規化する必要があるのですか?[クローズド]
-
[解決済み] Kerasにおける多対一および多対多のLSTMの例
-
[解決済み] 期待値最大化手法の直感的な説明とは?[クローズド]