[解決済み] 多層パーセプトロン(MLP)アーキテクチャ:隠れ層の数とサイズを選択する基準?[クローズド]
質問
しかし,MLPの隠れ層の数を選択する基準は何でしょうか?
どのように解決するのですか?
どのように多くの隠された層 ?
を持つモデルで ゼロ を解決します。 線形分離可能 というデータを解決します。ですから、データが線形分離可能でないことが分かっているのでなければ、これを検証することは問題ではありません。もし線形分離可能であれば、より単純な手法でうまくいきますが、パーセプトロンでも同じようにうまくいくでしょう。
あなたのデータが非線形の手法で分離する必要があると仮定すると、次のようになります。 常に1つの隠れ層から始める . ほぼ間違いなく,それが必要となるすべてです.もしデータがMLPを使って分離可能であれば,そのMLPはおそらく1つの隠れ層しか必要としないでしょう。これには理論的な正当性がありますが,私の理由は純粋に経験的なものです. 多くの難しい分類/回帰問題が単層MLPを使って解決されていますが,ML掲示板やML教科書,学術論文などで,多層隠れ層MLPを使ってうまくデータをモデリングしているのを見た記憶がありません.確かに存在するのですが、その使用を正当化する状況は経験的に非常に稀なのです。
隠れ層のノードはいくつですか?
MLPの学術的な文献や私自身の経験などから,私はいくつかの経験則を集めましたし,しばしばそれに頼っています( RoT )を集めており、それらは信頼できるガイドであることもわかっています(つまり、ガイダンスが正確であり、そうでない場合でも次に何をすべきかはたいてい明確である)。
日本語版 コンバージェンスの改善に基づいて
<ブロッククオートモデル構築を開始するときは、以下の点に注意してください。 より ノード の側を選んでください。
なぜでしょうか?まず,隠れ層のノードが多少増えても,MLPが収束することはないでしょう.一方,隠れ層のノードが少なすぎる場合は,収束を妨げることになります。このように考えると,ノードを追加することで,反復(トレーニング,またはモデル構築)中にネットワークに信号を保存したり解放したりするための,追加の重みが提供され,ある程度の余剰容量となります.第二に、隠れ層にノードを追加した場合、後で(イテレーションの進行中に)ノードを刈り込むのは簡単です。これは一般的なことであり、あなたを支援する診断テクニックがあります(例えば、Hintonダイアグラム、これは単に重みマトリックスの視覚的描写であり、重み値の「ヒートマップ」です)。
RoTs 入力層のサイズと出力層のサイズに基づく。
<ブロッククオート経験則では、この[隠れ]層のサイズは、入力層のサイズ...と出力層のサイズ...の間のどこかになるはずです。 入力層のサイズと出力層のサイズの間のどこかであることです....
隠れ節の数を計算するために、一般的な法則を使います。 (入力数 + 出力数) x 2/3
RoT を主成分とする。
<ブロッククオート通常、入力データの分散の70~90%を捉えるのに必要な次元[主成分]と同じ数の隠れノードを指定します。 入力データの分散の70-90%を捉えるために必要な次元[主成分]の数だけ隠れノードを指定します。 セット .
それなのに、その NN FAQ の著者は、これらのルールを (文字通り) ナンセンスと呼んでいます。なぜなら、学習インスタンスの数、ターゲット (応答変数の値) のノイズ、および特徴空間の複雑さを無視しているからです。
彼の見解では (そしてそれは常に、彼が何を言っているのかを知っているように私には思えました)。
MLP に何らかの正則化、または早期停止が含まれているかどうかに基づいて、隠れ層のニューロン数を選択する。
.
Hidden Layer のニューロン数を最適化するための唯一の有効な手法です。
テストは、「不適切な」ネットワークアーキテクチャの特徴を明らかにします。例えば、少数のノードで構成される隠れ層を持つMLPから始める場合(テスト結果に基づいて、必要に応じて徐々に増やします)、偏りとアンダーフィッティングによって、学習と汎化の誤差が大きくなります。
次に隠れ層のノード数を1つずつ増やし、今度はオーバーフィットと高分散が原因で汎化誤差が大きくなり始めるまで増やします。
実際には、私はこの方法でやっています。
入力レイヤ : データベクタのサイズ(モデルの特徴量) + バイアスノードに1、もちろん応答変数は含まない。
出力層 回帰(1ノード)か分類(クラスの数に相当するノード数、ソフトマックスと仮定)かによって決まります。
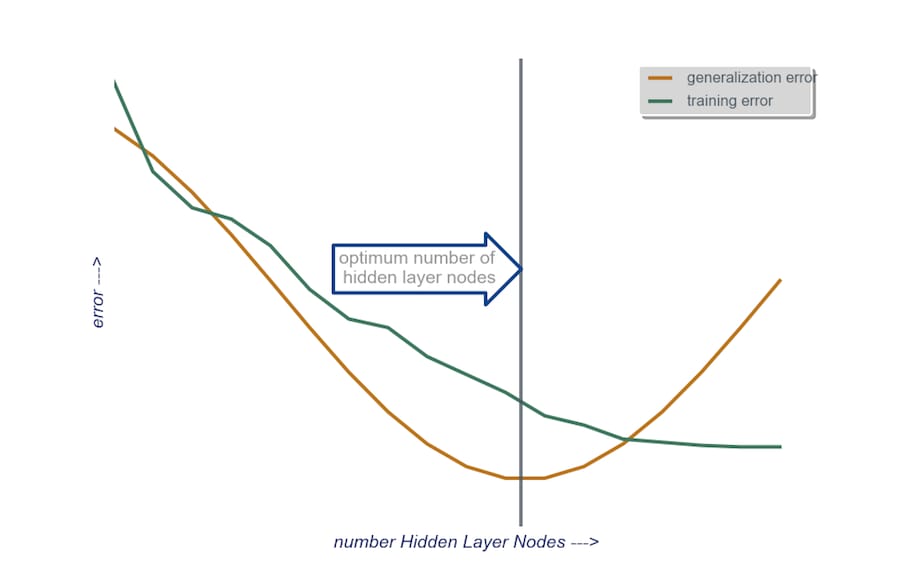
隠れ層 : を開始する , 1つの隠れ層 で、ノード数は入力層のサイズと等しくなります。理想的なサイズは、大きくなるよりも小さくなる可能性が高いです(つまり、入力層のノード数と出力層のノード数の間にある数)。もしプロジェクトが追加時間を必要とするものであれば、私は少数のノードからなる1つの隠れ層から始めて、(先ほど説明したように)汎化誤差、学習誤差、バイアス、分散を計算しながら、一度に1つずつ隠れ層にノードを追加していくのです。汎化誤差が減少し、再び増加し始める直前に、その時点でのノードの数を選択するのです。下図参照。
関連
-
[解決済み] Kerasにおける "Flatten "の役割とは?
-
[解決済み] RuntimeError: 次元が範囲外([-1, 0]の範囲にあると期待されたが、1が得られた)
-
[解決済み] エアフローとKubeflowパイプラインの違いは何ですか?
-
[解決済み] tf.reset_default_graph() の使用方法
-
[解決済み] Kerasの入力説明:input_shape, units, batch_size, dim, etc.
-
[解決済み] Kerasにおける多対一および多対多のLSTMの例
-
[解決済み] 期待値最大化手法の直感的な説明とは?[クローズド]
-
[解決済み] フィーチャーとラベルの違いは何ですか?[クローズド]
-
[解決済み] なぜFメジャーはPrecisionとRecallの算術平均ではなく調和平均なのですか?
-
[解決済み] クロスエントロピーとは?[クローズド]
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] PyTorchのバックワード関数
-
[解決済み] サポートベクターマシンに対する人工ニューラルネットワークの優位性は何ですか?[終了しました]
-
[解決済み】ニューラルネットワークにおけるバイアスの役割とは?[クローズド]
-
[解決済み】線形回帰とロジスティック回帰の違いは何ですか?[クローズド]
-
[解決済み】同じ問題で binary_crossentropy と categorical_crossentropy が異なる性能を示すのはなぜか?
-
[解決済み】教師あり学習と教師なし学習の違いは何ですか?[終了しました]
-
[解決済み] Diablo 2をプレイするための人工ニューラルネットワークを視覚的に学習させる方法とは?
-
[解決済み] なぜFメジャーはPrecisionとRecallの算術平均ではなく調和平均なのですか?
-
[解決済み] word2vec: ネガティブサンプリング(平たく言うと)?
-
[解決済み] トレーニング中のナンの原因