エンコード問題:UnicodeDecodeError: 'utf-8' コーデックは、位置のバイト 0xb3 をデコードできません。
2022-02-21 05:12:40
あるケースでは、次のようなエラーが報告されました。
UnicodeDecodeError: 'utf-8' コーデックは、位置 0 のバイト 0xb3 をデコードできません: 不正な開始バイトです。
Encoding problem: f = open(txtPath,'r',encoding='utf-8')
Change it to: f = open(txtPath,'r',encoding='gbk')
print(f.read())
CSVファイル読み込み時に別のエラーが発生しました。
import pandas as pd
content = pd.read_csv('news.csv',encoding='utf-8')
print(content.head())
エラーの内容は以下の通りです。UnicodeDecodeError: 'utf-8' コーデックは、位置 0 のバイト 0xba をデコードできません: 開始バイトが無効です。
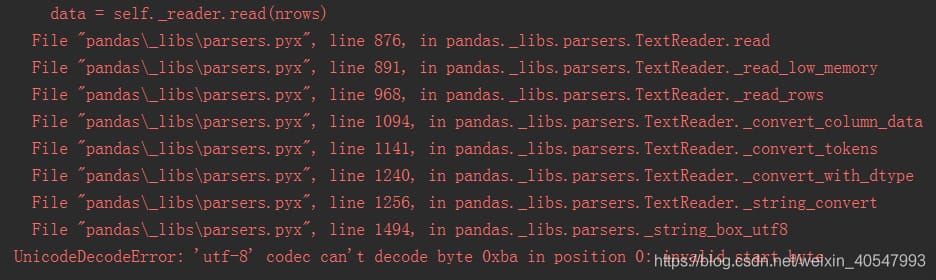
ここで、エンコーディングの問題をutf-8からgbkに変更しましたが、まだエラーが報告されます。
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 93: illegal multibyte sequence(93のバイトをデコードできません。
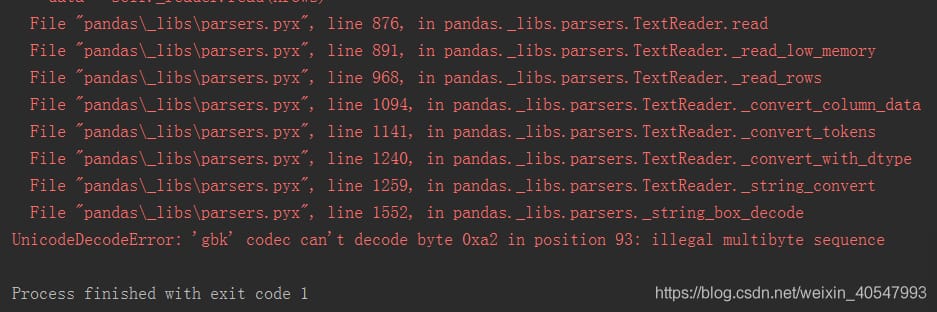
プログラムを変更したときにようやく
import pandas as pd
content = pd.read_csv('news.csv',encoding='gb18030')
print(content.head())
つまり、読み込みに成功したのは
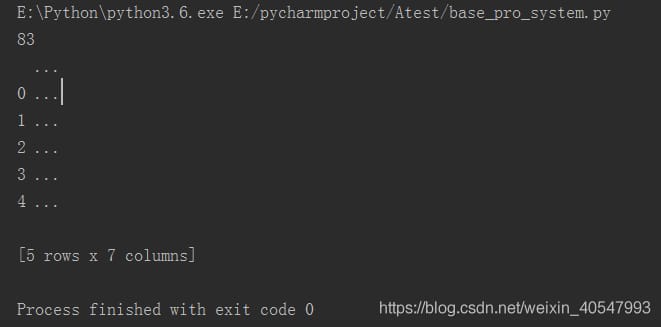
これらの種類の問題は、ファイルのエンコーディングの問題であり、ファイルのエンコーディングの種類は、最終的には、誰も知らないように、唯一の試しに最も一般的に使用されるエンコーディングフォーマット1を使用することができます。ここでは、ファイルのエンコード形式をgb18030に変更しましたが、この形式はたまに見かけるので試してみてください。
関連
-
チェックされていないruntime.lastError: 接続を確立できませんでした。受信側が存在しません。
-
PythonがNameError: name '_name_' is not definedのようなエラーを発生させる。
-
PyQt5演習:matplotlibでプロットする
-
Python max()関数
-
python 3.3.2 エラー。urllib2' という名前のモジュールがない ソリューション
-
Python による pyserial 経由でのシリアルポートの読み取りと書き込み
-
Anaconda 詳細インストールおよび使用チュートリアル(画像付き)
-
Selenium issue IOError: [Errno 2] そのようなファイルまたはディレクトリがありません: 'nul'
-
numpyのconcatenate関数
-
[解決済み] です。TypeError: read() missing 1 required positional argument: 'filename'.
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Python「lxmlを使ったxpathのパース - コナちゃんをクローリングする
-
Python は '' で '__main__' モジュールを見つけることができません。
-
ORMにおけるトランザクションとロック、Ajaxによる非同期リクエストと部分リフレッシュ、Ajaxによるファイルアップロード、日時指定Json、マルチテーブルクエリブックのシステム
-
Python3 xlsxwriterモジュールのインストール
-
Pythonでナンバープレート自動認識システムを作ろう!楽しくて実用的です。
-
Python OSError: [Errno 22] 無効な引数: solution
-
Python djangoプログラミングエラーのコツ、自作プログラミングで遭遇したエラーのまとめ 2018年11月8日更新
-
python error TypeError: 'range' object does not support item assignment, solution
-
パイソン-ユニコード
-
tkinter モジュールを使った Python 倉庫番ゲーム