Python「lxmlを使ったxpathのパース - コナちゃんをクローリングする
今日、私はlxmlを使ってxpathドキュメントをパースしようとしたが、実はこれはhtmlドキュメントであった。
I: lxml と xpath
lxmlライブラリは、主にXML、HTMLデータの解析と抽出に使用されるXML、HTMLパーサーです。lxmlライブラリはまずHTML文書を解析し、次にXPathを使ってHTML文書内のノードを検索またはトラバースすることが可能です。
まず、lxmlをプリインストールする必要があります。conda install lxmlです。
XPathは、XML文書内の情報を検索するための言語です。XPath は XML ドキュメント内の要素や属性をたどるために使用することができ、XPath は HTML ドキュメントを XML ドキュメントに変換した後に HTML のノードや要素を見つけるために使用することができます。
詳しい使い方や導入方法については、https://www.jianshu.com/p/a7633dd72a3f または Baidu を参照してください。
ここでは、学習テストの簡単な例を紹介します。
from lxml import etree
# HTML string
text = '''
Harry Potter
J K. Rowling
Jack Rowling
aaa
bbb
2005
29.99
II: サイトをクロールする https://konachan.com/post
https://konachan.com/post、多くのYAを含む多くのアニメ画像があります。
そんなことより、今日はちょっとクローラーを作って這わせ、lxmlの機能を使ってみようということです。
早速ですが、サイトのトップページを見てみましょう。デザイン内容が悪いかもしれないので、パソコンを使ってあーだこーだとごまかしました、ご自分の目で確かめてください。
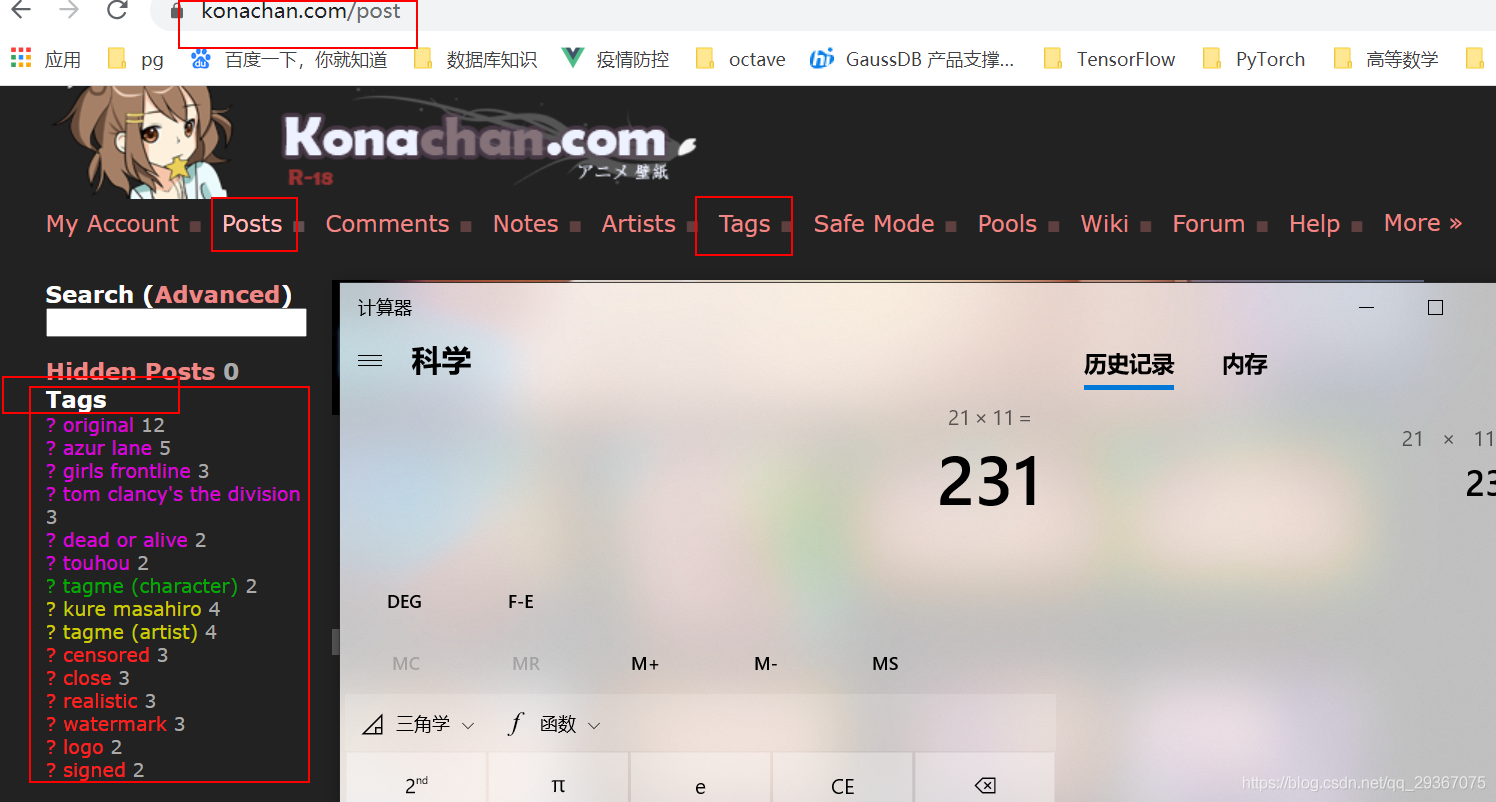
もう一度、urlにどんな機能があるのか見てみましょう。
https://konachan.com/post?page=3&tags=azur_lane
はページ番号とタグの2つの部分で構成されているので、まずタグが何であるかを調べる必要があります。
まずタブに移動して、すべてのタブをジャックダウンしてみましょう。ここはページネーションになっているので、一つ一つを訪問する必要があります。
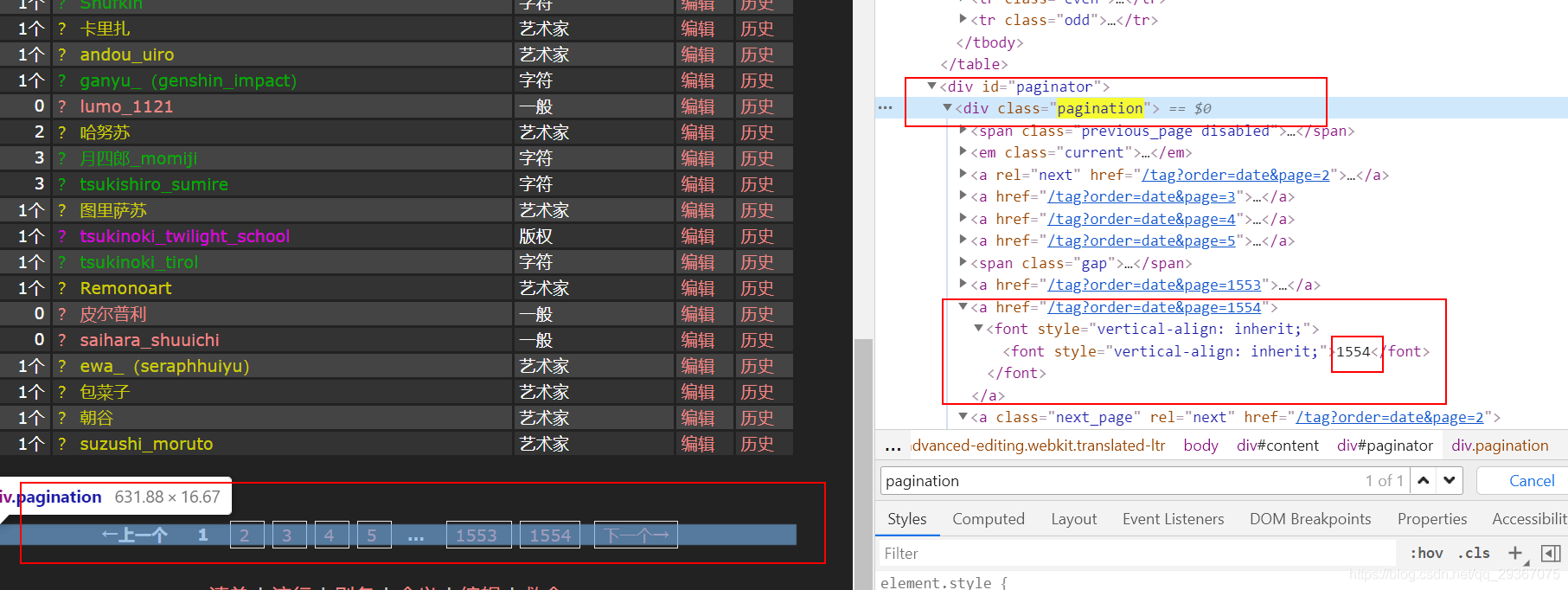
各タブについて、次にデータが記録されているタブのみを保存します。
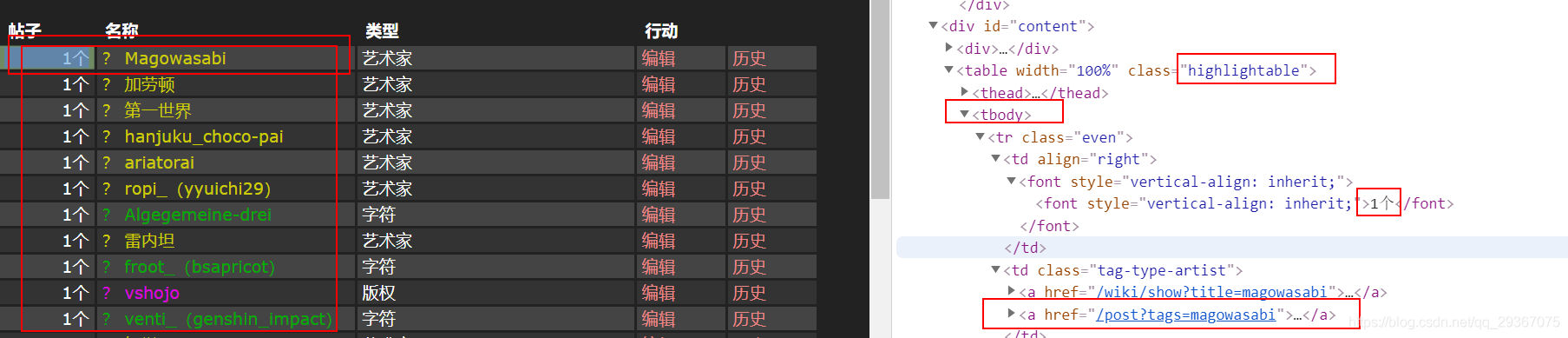
タグで、そのタグのページに移動する
https://konachan.com/post? tags=azur_lane は https://konachan.com/post?tags=azur_lane &page=1 と同じです。
つまり、あるタグのサブページにアクセスするために、ページを組み立てるだけでよいのです。
具体的なページにたどり着いたときはどうでしょう。超クリアな画像が表示されていることがわかったので、超クリアな画像へのリンクを直接取得する。
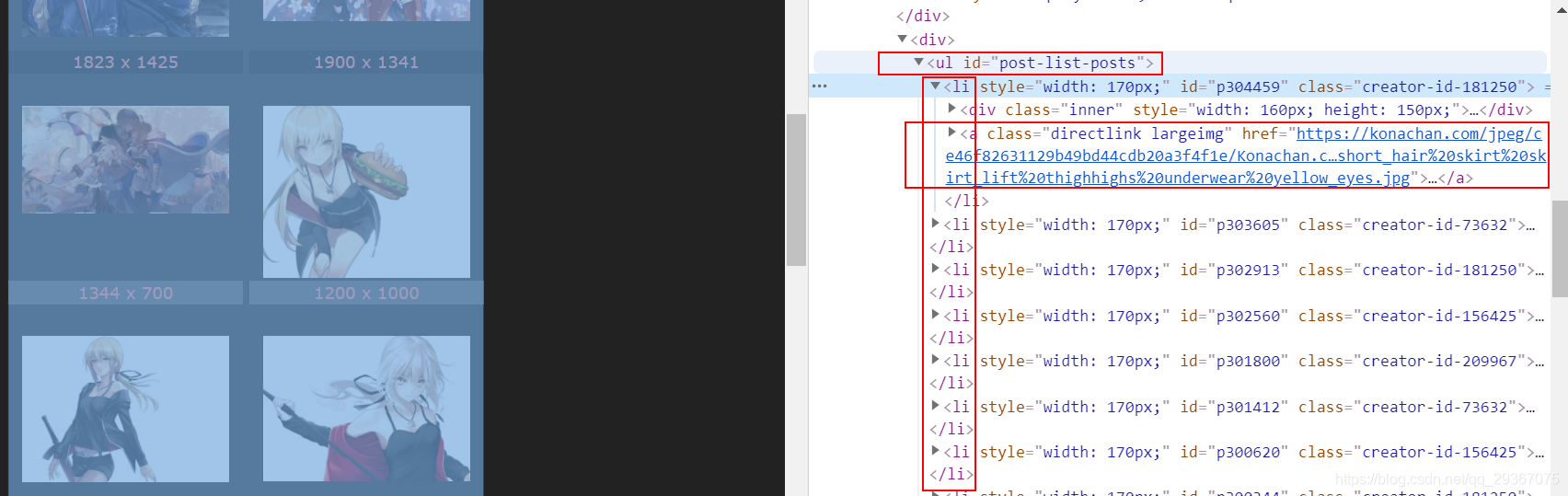
恒例のように、1つダウンロードして見てみましょう。
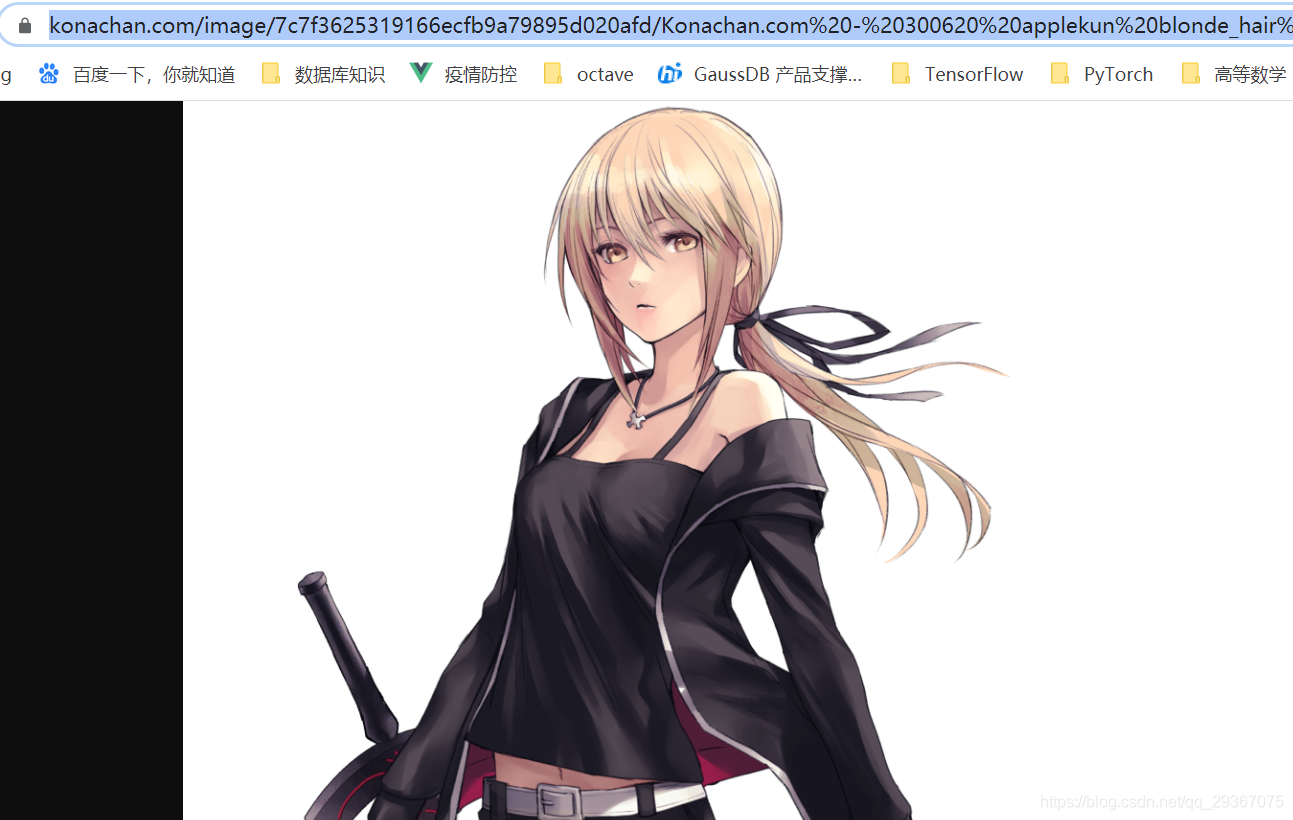
テストコードは以下の通りです。
import requests
def run8():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/ 537.36",
"Referer": "https://konachan.com/"
}
with open("D:/estimages/mn.jpg", "wb") as f :
f.write(requests.get("https://konachan.com/image/7c7f3625319166ecfb9a79895d020afd/Konachan.com%20-%20300620%20applekun% 20blonde_hair%20fate_grand_order%20fate_%28series%29%20long_hair%20navel%20necklace%20ponytail%20ribbons%20saber%20saber_alter% 20shorts%20sword%20weapon%20white%20yellow_eyes.jpg", headers=headers).content)
f.close
もし
名前
== "
メイン
"です。# メインプログラムのエントリ
run8() # 上記の run メソッドを呼び出す。
テストは成功しました!

コードの全文は以下の通りです。
タグを取得するスレッドと、タグに基づいて画像をダウンロードするスレッドの2つを作成します。
import os
import requests
from bs4 import BeautifulSoup
from lxml import etree
import time
import threading
rootrurl = 'https://konachan.com/'
save_dir = 'D:/estimages/'
no_more_pages = 'END'
max_pages = 10
# This is a tag collection, tags cannot be duplicated
tag_cache = set()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/ 537.36",
"Referer": "https://konachan.com/"
}
def getTotalPages(url):
# penultimate
below
is the text of
total_page_nums = 1
html = BeautifulSoup(requests.get(url, headers=headers).text, features="html.parser")
div = html.find('div', attrs={'class': 'pagination'})
if div is not None:
# Use the HTML() method to parse strings
# HTML() uses the HTML parser by default, and will auto-complement if it encounters irregular HTML code.
html_element = etree.HTML(str(div))
total_page_nums = int(html_element.xpath('//div/a/text()')[-2])
return total_page_nums
def getOneTagPage(url):
html = BeautifulSoup(requests.get(url, headers=headers).text, features="html.parser")
trs = html.find('table', attrs={'class': 'highlightable'}).find('tbody').find_all('tr')
for tr in trs:
html_element = etree.HTML(str(tr))
num = int(html_element.xpath('//tr/td/text()')[0])
if num == 0:
continue
tag = html_element.xpath('//tr/td/a/@href')[1]
if tag not in tag_cache:
tag_cache.add(tag)
def getAllTags():
url = rootrurl + 'tag?order=date'
# Step 1: Get the total number of pages
total_page_nums = getTotalPages(url)
# Step 2: Construct your own page to crawl all the tags
for i in range(1, (total_page_nums + 1)):
# for i in range(1550, (total_page_nums + 1)): # For testing convenience, we start directly from page 1550. The user can change it back to start from page 1.
print("tag page num : %d." % i)
url = rootrurl + ('tag?order=date&page=%d' % i)
getOneTagPage(url)
def saveOnePage(tag, idx, saveDir):
url = rootrurl + tag[1:] + '&page=%d' % idx
html = BeautifulSoup(requests.get(url, headers=headers).text, features="html.parser")
a_s = html.find('ul', attrs={'id': 'post-list-posts'})
if a_s is None:
return
a_s = a_s.find_all('a', attrs={'class': 'directlink largeimg'})
i = 1
for a in a_s:
img_url = a.get('href')
img = requests.get(img_url) # the actual URL of the requested image
with open(
'{}/{}_{}. {}'.format(saveDir, idx, i, img_url.split(". ")[-1]), 'wb') as jpg: # Request the image and write it in to a local file
jpg.write(img.content)
i = i+1
def saveOneTag(tag):
dir = '{}{}'.format(save_dir, tag.split("=")[-1])
if not os.path.exists(dir):
os.mkdir(dir)
print(tag)
url = rootrurl + tag[1:]
tag_cache.remove(tag) # Avoid repeated operations on the tag
# Step 1: Get the total number of pages
total_page_nums = getTotalPages(url)
# Step 2: Facilitate the download of each page
for i in range(1, (total_page_nums + 1)):
if i > 6: # This is purely to facilitate the test, otherwise there are too many pages ah
break
saveOnePage(tag, i, dir)
def saveAllTagImgs():
# Temporarily get a batch of tags
l = list(tag_cache)
# Access each tag
for tag in l:
saveOneTag(tag)
class myThread1 (threading.Thread): # Inherit from parent class threading.
def __init__(self, threadID):
threading.Thread.__init__(self)
self.threadID = threadID
def run(self): # Write the code to be executed in the run function The thread will run the run function directly after it is created
print("Thread %d is running... " % self.threadID)
getAllTags(
その効果は次の通りです。
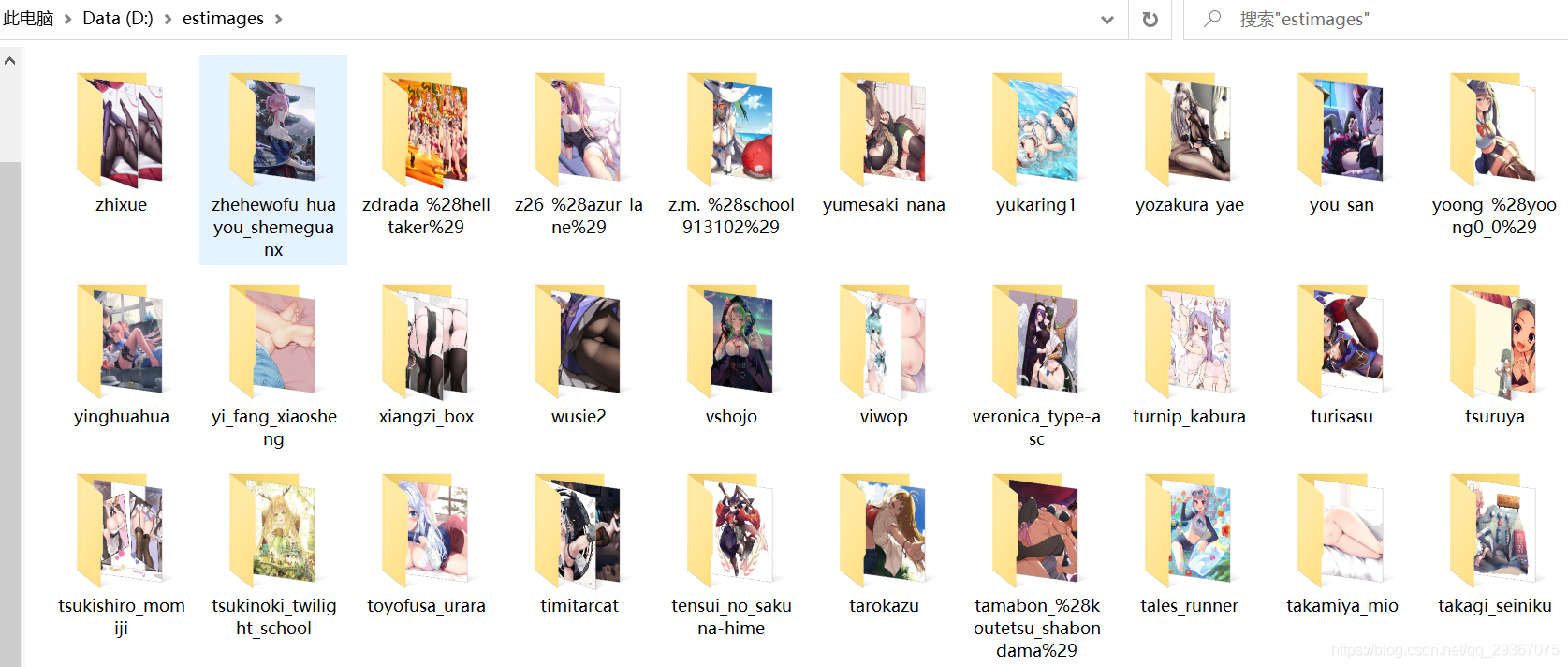
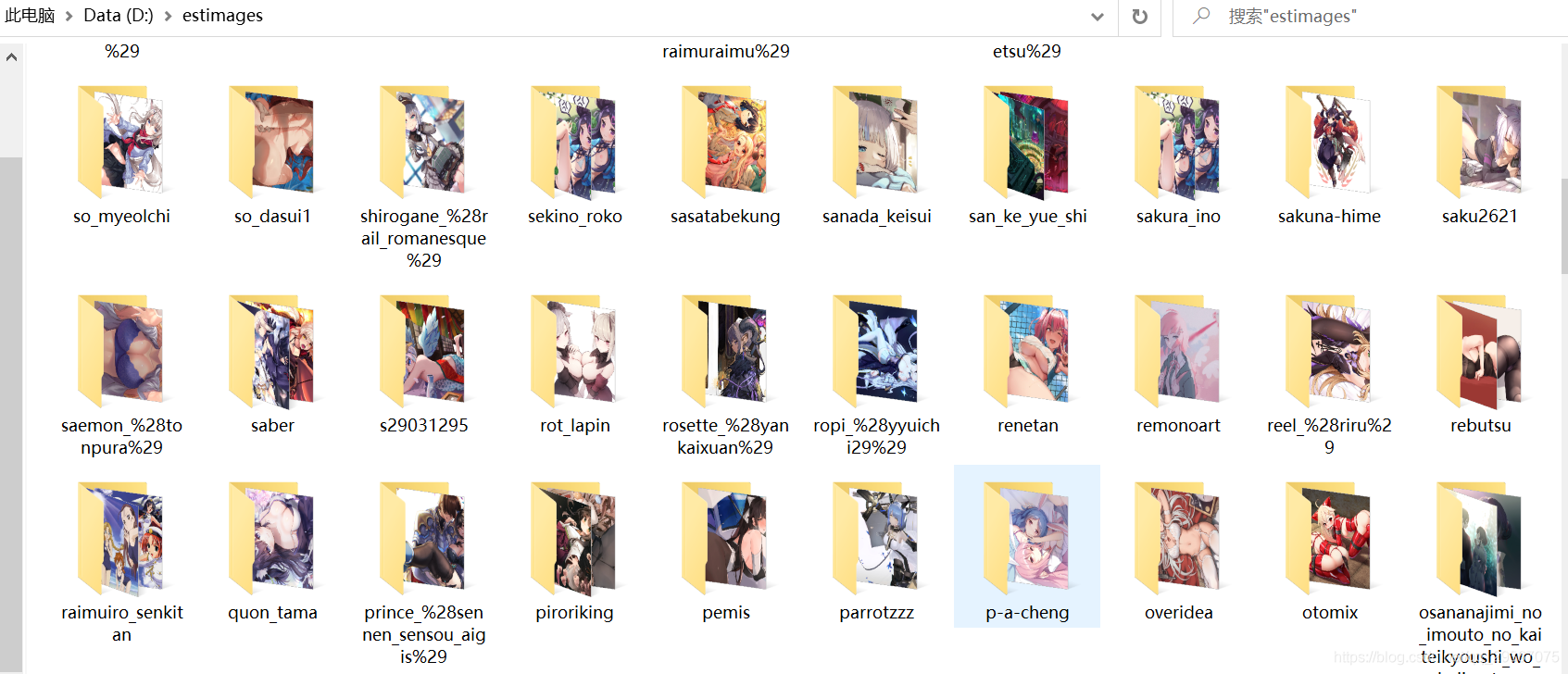
関連
-
Python】import pandas, error pandas Missing required dependencies ['numpy'] Reason Analysis
-
undefinedImportError: 必要な依存関係['Numpy']がありません。
-
pythonBug:AttributeError: タイプオブジェクト 'datetime.datetime' は属性 'datetime' を持たない。
-
Python クローラーで AttributeError: 'NoneType' オブジェクトに属性 'text' がないエラー。
-
Python組み込み関数 - min関数とmax関数 - 詳細解説
-
ImportError を解決します。pandas をインストールした後に 'pandas' という名前のモジュールがない。
-
[コード】pygame 学習
-
Pythonのタイトル。学生情報管理システム - アドバンス版 (GUI + MySQLデータベース)
-
Python djangoプログラミングエラーのコツ、自作プログラミングで遭遇したエラーのまとめ 2018年11月8日更新
-
python 1e-5とはどういう意味ですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Python は '' で '__main__' モジュールを見つけることができません。
-
AttributeError: 'module' オブジェクトには 'SSL_ST_INIT' 属性がない ソリューション
-
Python27 PILソリューションという名前のモジュールがない
-
ImportError: scipy'という名前のモジュールがありません。
-
python-OverflowError: Python の int が大きすぎるため C の long に変換できない
-
TypeError: 'encoding'はこの関数の無効なキーワード引数です。
-
Pythonのjson.loadsで文字列のデコードに失敗しました。ValueError: JSONオブジェクトをデコードできませんでした
-
pythonのエラーです。ValueError: 閉じたファイルへのI/O操作
-
タオバオ販売(特定値表示可能)インターフェイス
-
Python Numpy.ndarray ValueError: 代入先が読み取り専用です。