RCNNアルゴリズム解析の高速化(ソースコード付き、直接実行可能)
I. 序文知識
1. Region Proposal(候補領域)に基づく深層学習ターゲット検出アルゴリズム
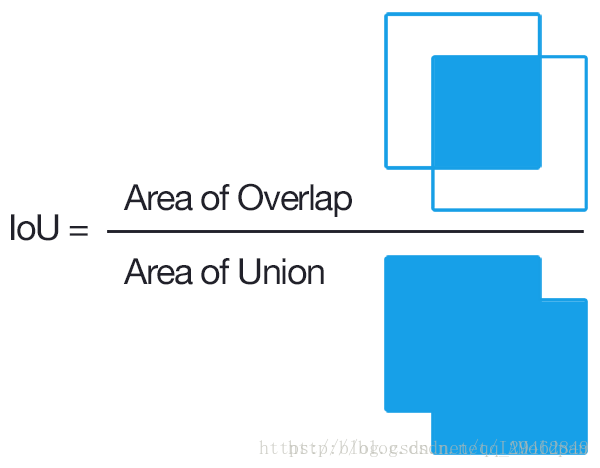
グラフ内のターゲットの可能性のある位置を先取りして特定するRegion Proposalは、画像内のテクスチャ、エッジ、色などの情報を用いて選択した少ないウィンドウ数(数千、数百)で高いリコール(IoU, Intersection-over-Union)を確保します。
2. IoUとは?
Intersection over Unionは、与えられたデータセットにおいて、対応するオブジェクトを検出する精度を測定する指標である。PASCAL VOCチャレンジのような多くのオブジェクト検出チャレンジでこの基準が多く使われていることがわかります。
一般的には、HOG + Linear SVMによる物体検出やConvolutional Neural Networkによる検出(R-CNN、Faster R-CNN、YOLOなど)でこの方法を使い、その性能を確認することが多いようです。なお、この測定は、タスクで使用しているオブジェクト検出アルゴリズムとは関係ありません。
IoUは、出力に予測範囲(bounding boxex)をもたらすあらゆるタスクに使用できるシンプルな測定基準である。IoUを任意の大きさ、形状の物体検出の測定に使えるようにするためには、以下のものが必要である。
1. グランドトゥルース境界ボックス(学習セット画像で検出される物体のおおよその範囲を人為的にマークしたもの)。
2.我々のアルゴリズムが導き出した結果の範囲。
つまり、この基準は真と予測の相関を測るためのものであり、相関が高いほど高い値となる。
次の図のようなものです。

下図は、グランドトゥルースと予測の結果です。緑のマーカーが人間がマークした正しい結果、赤いマーカーがアルゴリズムが予測した結果で、IoUがやるべきことは、この二つの結果でアルゴリズムの精度を測定することです。
領域提案法は、従来のスライディングウィンドウ法よりも高い品質を得ることができます。一般的に使われている領域提案法には、SelectiveSearch (SS, 選択的探索) や Edge Boxes (EB) などがあります。
II. R-CNN、Fast R-CNN、およびFaster R-CNNの関係
Faster R-CNNはR-CNNとFast R-CNNをベースにした改良版である。
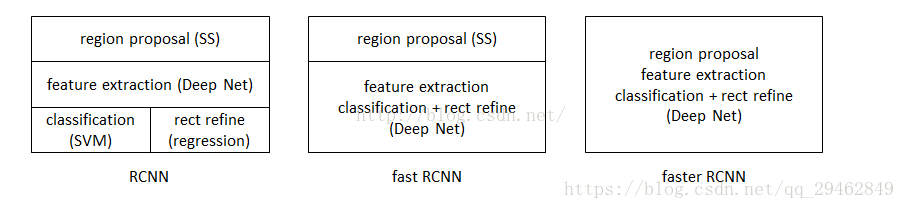
3つの関係
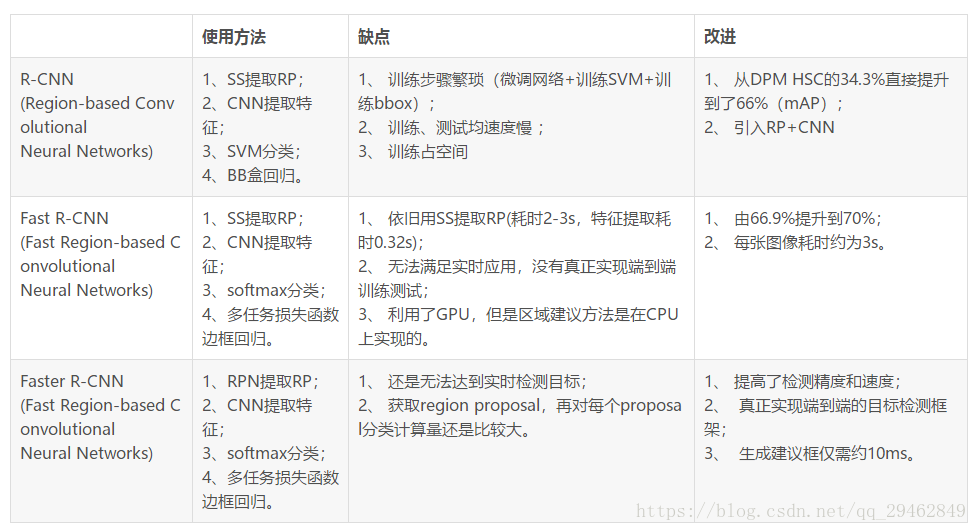
3つの比較
R-CNNとFast R-CNNの詳細については、以下を参照してください。 R-CNNとFast R-CNN
III. より高速なR-CNNターゲット検出
3.1 Faster R-CNNの考え方
Faster R-CNNは、FastR-CNNの選択探索法を領域生成ネットワークに置き換えた、quot;領域生成ネットワークRPN + Fast R-CNNs"のシステムとして簡単に捉えることができる。Faster R-CNNの論文では、このシステムにおける3つの問題に焦点を当てている。
1.領域生成ネットワークをどのように設計するか。
2. 領域生成ネットワークの学習方法。
3. 3. 領域生成ネットワークとFast RCNNネットワークで特徴抽出ネットワークを共有させる方法。
Faster R-CNNアルゴリズム全体を通して、3つのスケールがある。
1. 元画像のスケール:入力された元画像のサイズ。制約を受けず、性能に影響しない。
- 正規化 さ れた ス ケール : 入力 さ れた特徴抽出ネ ッ ト ワー ク のサ イ ズで、 ソ ース コ ー ド では opts.test_scale=600 に設定 さ れてい ます。 アンカーは こ のスケールに設定 さ れます。このパラメータとanchorの相対的な大きさが、検出するターゲットの範囲を決定します。
- Network input scale: 入力される特徴検出ネットワークのサイズ、トレーニング時に設定、ソースコードでは224*224。
3.2 Faster R-CNNフレームワークの紹介
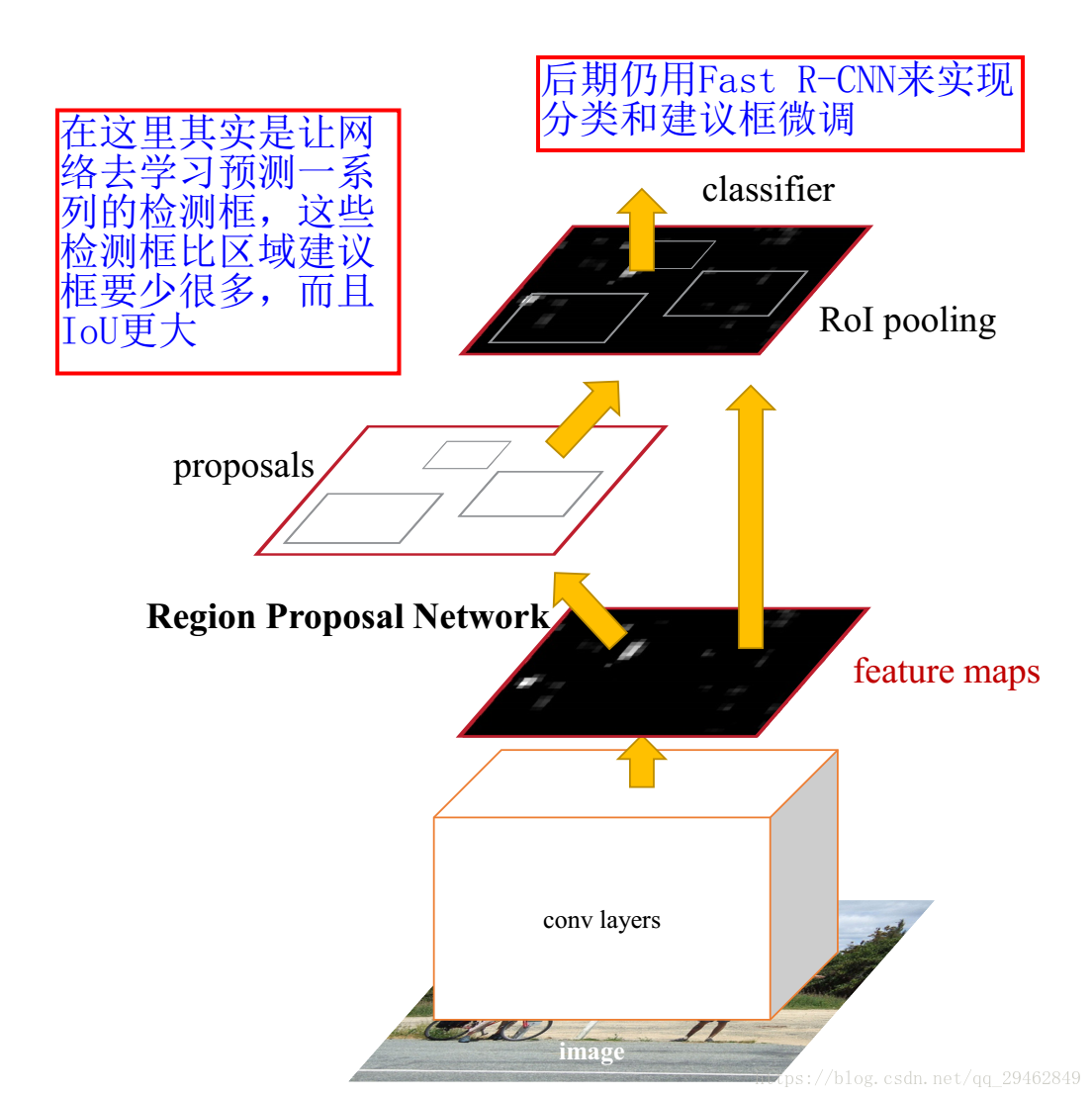
より高速なR-CNNモデル
Faster R-CNNアルゴリズムは大きく2つのモジュールから構成される。
1. PRN候補フレーム抽出モジュール。
2.高速R-CNN検出モジュール。
このうち、RPNは候補フレームを抽出するための完全畳み込みニューラルネットワークで、Fast R-CNNはRPNによって抽出されたプロポーザルをもとにプロポーザル内のターゲットを検出・識別する。
3.3 RPN の紹介
3.3.1 背景
現在の最新のターゲット検出ネットワークでは、まずRegion Proposalアルゴリズムを用いてターゲットの位置を推定する必要があります。SPPnetやFast R-CNNなどのこれらのネットワークは、検出ネットワークの実行時間を短縮していますが、Region Proposalの計算に時間がかかることに変わりはありません。そこで、このようなボトルネックを持つRBGとKaiming Heのグループは、CNNにもRegion Proposalを任せ、グラフ全体の畳み込み特徴を検出ネットワーク全体で共有できる、検出領域を抽出するためのRPN (Region Proposal Network) 地域提案ネットワークを提案し、地域提案をほぼ時間フリーにすることに成功したのです。
RCNNは、「なぜ分類にCNNを使わないのか」という疑問を解決します。
高速R-CNNは、「なぜバウンディングボックスとラベルを一緒に出力しないのか」という問いに答える。
より高速なR-CNNは、「なぜ選択的探索を行うのか」という疑問に答える。
3.3.2 RPNコアアイデア
RPNのコアとなるアイデアは、アンカー・メカニズムとボーダー回帰がマルチスケール・マルチアスペクト比のRegion Proposalを得ることができるので、本質的にスライディング・ウィンドウ(最後の畳み込み層の上をスライドするだけ)を使って、CNN畳み込みニューラルネットワークを使って直接Region Proposalを生成することである。
また、RPNネットワークは、検出提案フレームを生成するタスクのためにエンドツーエンドで学習できる完全畳み込みネットワーク(FCN, fully-convolutional network)であり、オブジェクトの境界とスコアの両方を予測することが可能である。CNNに2つの畳み込み層(完全畳み込み層clsとreg)を追加しているだけです。
各特徴マップの位置を特徴ベクトル(ZFは256d、VGGは512d)にエンコードする。
すなわち、各畳み込みマッピング位置において、この位置の複数のスケール(3種類)、アスペクト比(3種類)のk(3*3=9)個の領域案のオブジェクトネス・スコアとresressedboundsを出力する。
RPNネットワークへの入力は、任意のサイズの画像(ただし、最低限必要な解像度、例えばVGGは228*228)であることができます。特徴抽出にVGG16を用いる場合、RPNネットワークの構成は、VGG16+RPNの形で表すことができる。
VGG16:参考
https://github.com/rbgirshick/py-faster-rcnn/blob/master/models/pascal_voc/VGG16/faster_rcnn_end2end/train.prototxt VGG16のうち特徴抽出に使用する部分は、pool5とpool5以降のネットワーク階層を除いた13畳み込み層(conv1_1-->conv5.3)であることがわかる。
我々の最終目標はFast R-CNNターゲット検出ネットワークと計算を共有することであるため、2つのネットワークは一連の畳み込み層を共有すると仮定している。この論文の実験では、ZFは5つの共有可能な畳み込み層を持ち、VGGは13の共有可能な畳み込み層を持っている。
RPNの具体的なプロセスは以下の通りである。最終的な畳み込みによって得られた特徴マップに対して、小さなネットワークでスライディングスキャンを行い、このスライディングネットワークは一度に特徴マップ上のn*n(論文ではn=3)のウィンドウに完全に接続される(画像の有効感覚野は大きい。ZFでは171ピクセル、VGGでは228ピクセル)、低次元ベクトル(ZFでは256d / VGGでは512d)にマッピングされ、最後にこの低次元ベクトルは2つの完全連結層、すなわちbbox回帰層(reg)とbox分類層(cls)に供給される。スライディングウィンドウ処理により、reg層とcls層はconv5-3の全特徴空間を関連付けていることが保証される。
reg-layer:プロポーザルに対応するアンカーの(x,y,w,h)を予測する。
cls層:提案が前景(オブジェクト)か背景(非オブジェクト)かを判断する。
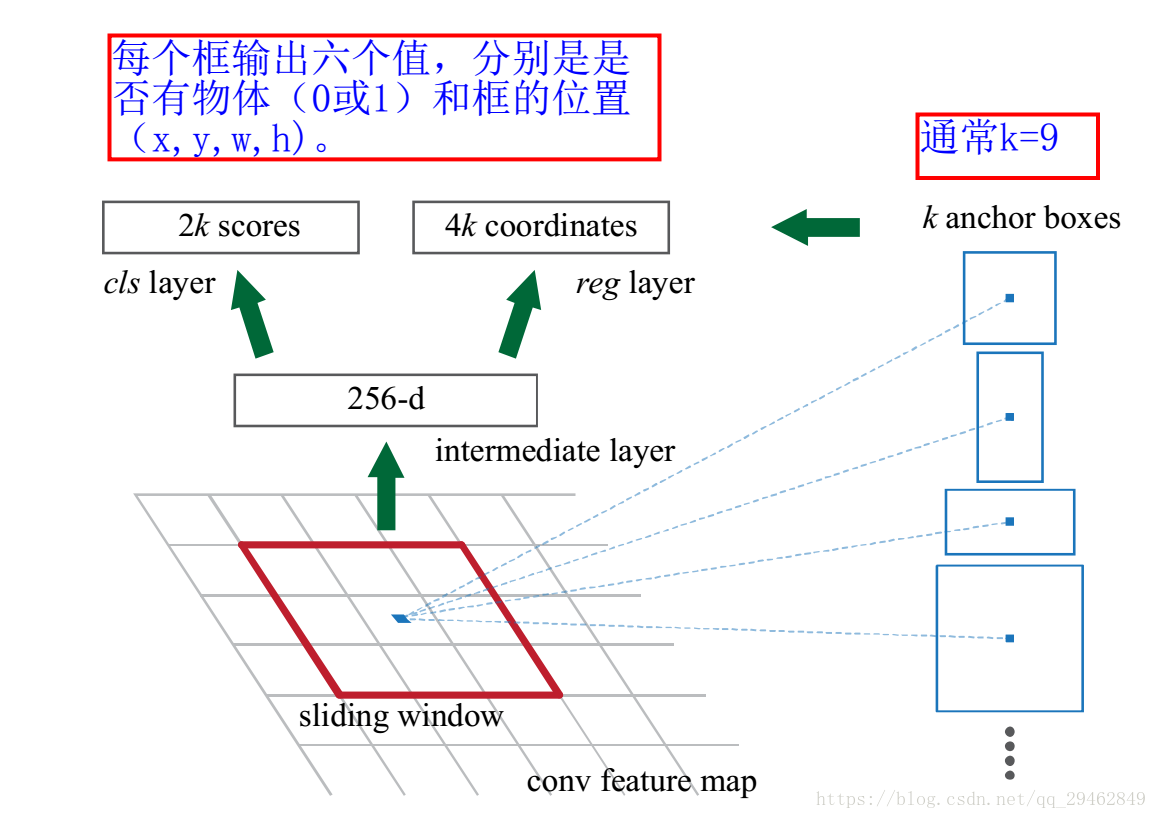
RPNフレームワーク
上の図では、3*3コンボリューションカーネルの重心がオリジナルマップ(リスケール、ソースコードはリスケールを600*1000に設定)上の位置(点)に対応し、その点をアンカーの重心として、オリジナルマップの複数のスケールと縦横比を持つアンカーを縁取っていることに注目。つまり、アンカーはコンボ特徴マップ上ではなく、オリジナルマップ上にあるのだ。H*Wサイズの特徴層では、その上の各ピクセル点が9個のアンカーに対応し、ここにはfeat_stride = 16という重要なパラメータがある。これは、特徴層上の1点を動かすと、元の地図上の16ピクセル点を動かすことに相当する(16の由来は、ネットワークのストライドを見れば理解できるだろう)。この9つのアンカーの座標をパンして、元の地図上の座標を得る。その後、グランドトゥルースラベルとこれらのアンカーとの関係 に応じて rpn_lables を生成するが、具体的な方法は論文に記載されており、 オーバーラップに応じて計算されるので、ここでは詳しく説明しな い。box_targetsは_compute_targets()関数で生成され、実際に各アンカーに対して最もマッチするグランドトゥルースのボックスを見つけ、論文にあるようにボックス座標の変換を行う。
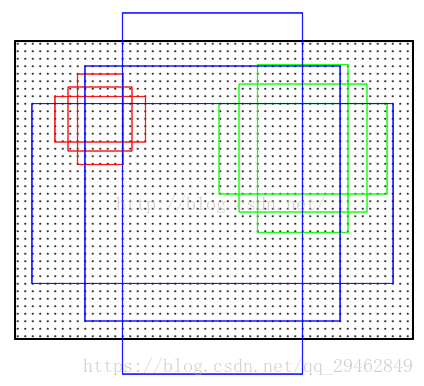
9つのアンカー(3つのスケール[128x128;256x256;512x512]、3つの比率[1:1;1:2;2:1])。
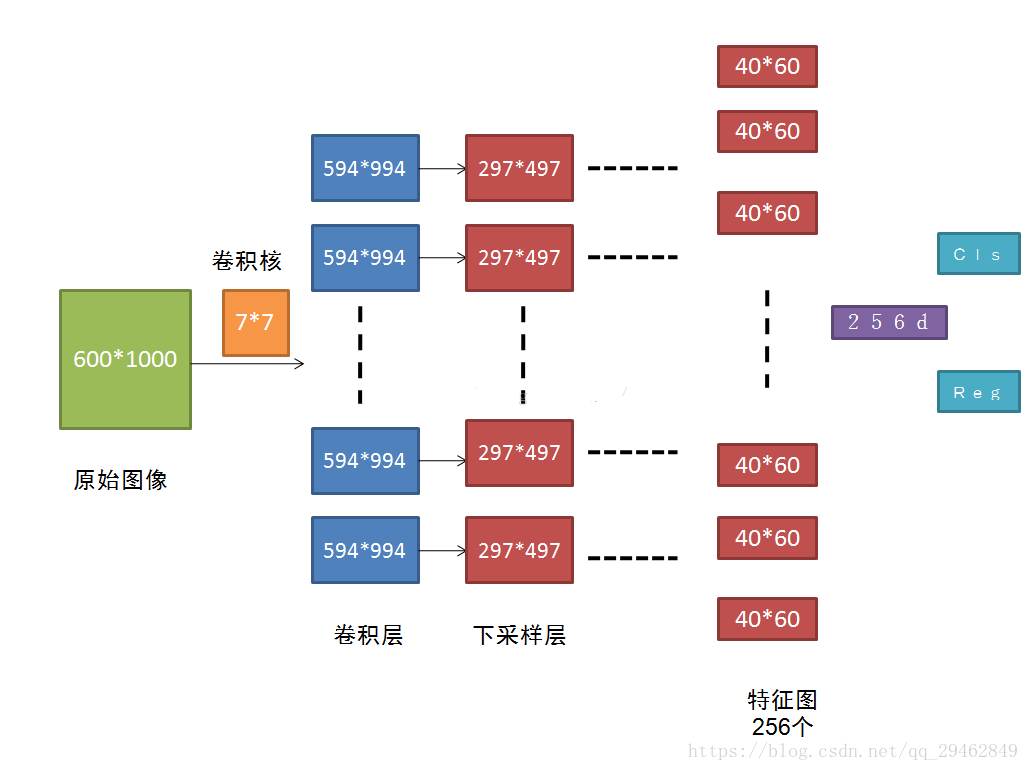
より高速なR-CNN畳み込みフローチャート
元の600*1000をCNNで畳み込み、CNNの最終層(conv5)でサイズ40*60の特徴マップを得るが、これは本文にあるように代表値2400に相当する。特徴マップサイズをW*Hとすると、W*H*Kのアンカーが必要となり、本稿では40*60*9≈2kが必要である。
RPNネットワークでは、アンカーの概念、Loss fucntionsの計算方法、RPN層の学習データ生成の具体的な内容を理解することに注力する必要があります。
3.4 RPNの並進的不変性
コンピュータビジョンの課題の一つに翻訳不変性がある。例えば、顔認識課題で学習した重みを持つ同じネットワークで、小さい顔(解像度24×24)と大きい顔(解像度1080×720)の両方を正しく認識する方法である。画像中のターゲットがパンされた場合、提案フレームもパンされ、同じ関数で提案フレームを予測することも可能であるべきです。
従来の主流は2つ。
1つ目は、画像またはフィーチャーマップレイヤーをサンプリングして、スケール/幅/高さを調整する方法です。
次に、スケール/幅/高さのフィルタをサンプリングします(または、スライディングウィンドウと考えることもできます)。
しかし、この問題を解決するためのFaster R-CNNの具体的な実装は、畳み込みカーネルの中心(推薦ウィンドウを生成するためのアンカー)によってスケール、縦横比をサンプルし、3スケール、3比率を使って9つのアンカーを生成することである。
3.5 窓の分類と位置の絞り込み
分類層(cls_score)は、各位置において、9個のアンカーが前景と背景に属する確率を出力する。
ウィンドウ回帰層(bbox_pred)は、各位置にある9つのアンカーのそれぞれについて、ウィンドウのパンとスケーリングに対応するパラメータ(x,y,w,h)を出力する。
各位置について、分類層は256次元の特徴量から前景と背景に属する確率を出力し、窓回帰層は256次元の特徴量から4つのパンニングとスケーリングパラメータを出力します。
なお、候補となるウィンドウは明示的に抽出されず、ネットワークそのものがすべて判定と補正に使用される。
3.6 学習領域提案型損失関数
3.6.1 タグ分類の規則
RPNを学習するためには、各アンカーにクラスラベル{target, non-target}を割り当てる必要がある。正のラベルについては、論文で以下のように示されている(正のラベルは、以下の条件のいずれかを満たすと判断される)。
1. GTの囲み枠の中で最も高いIoUと重なるアンカー
2. 2. あらゆるGTラップアラウンドボックスでIoUが0.7より大きいアンカー
GTの囲み枠は複数のアンカーに対応することができるので、GTの囲み枠は複数のポジティブタグを持つことができることに注意してください。
実際には、2番目のルールを使用すると、基本的に十分な正のサンプルを見つけることができますが、例えば、アンカーボックスとグリッドトゥルースに対応するすべてのアンカーボックスのIoUが0.7より大きくないなど、いくつかの極端なケースでは、最初のルールで生成することができます。
ネガティブラベル すべてのGT囲みボックスとのIoUが0.3未満であるアンカー。
ポジティブラベルでもネガティブラベルでもないアンカーや、画像境界を越えるアンカーは、学習対象に影響を与えないため、破棄する。
3.6.2 マルチタスクロス (Fast R-CNN より)
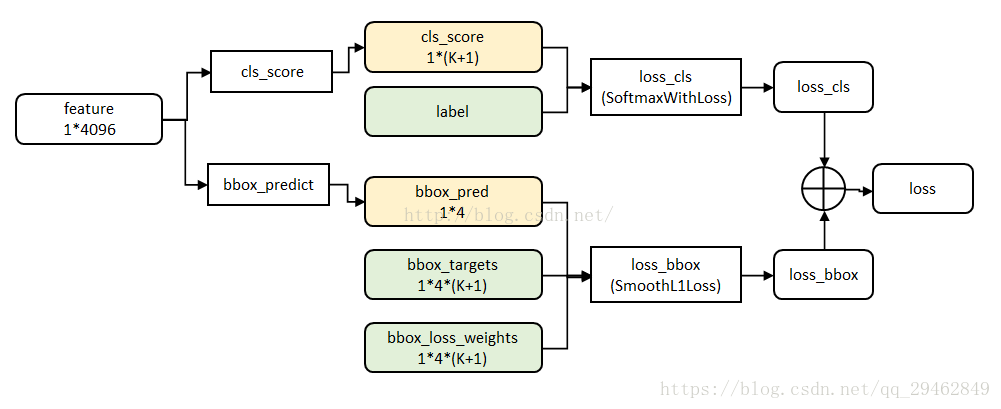
マルチタスクデータ構造
ここでは、分類と回帰の合計2種類の損失が関係している(詳しくは論文をご覧ください)
ここでは説明しないが、回帰についてはR-CNNやFast R-CNNを参照するとよいだろう
3.7 非極端値の抑制
最大値抑制は、冗長な検出フレームを提案するために使用され、そのアルゴリズムは NMSアルゴリズム
4. ソースコード
ここでは、Googleオープンソースのオブジェクト検出apiのコードを使用しています、コードのインストールと設定について
Googleオブジェクト検出フレームワーク設定チュートリアル
ここに設定されているので、直接ソースコードを実行することができます!!!!
以下は、学習済みモデルを用いた直接的な物体検出です。単一画像の検出だけでなく、動画中のオブジェクトの検出も含まれています。
import numpy as np
import os
import six.movs.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
import cv2
## This is needed to display the images.
#%matplotlib inline
## This is needed since the notebook is stored in the object_detection folder.
sys.path.append(". ")
from utils import label_map_util
from utils import visualization_utils as vis_util
# What model to download.
# Download the trained model on the official website
MODEL_NAME = 'faster_rcnn_resnet101_coco_11_06_2017'
MODEL_FILE = MODEL_NAME + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
NUM_CLASSES = 90
#download model
opener = urllib.request.URLopener()
#download model, if it's already downloaded the following code can be commented out
#opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar_file = tarfile.open(MODEL_FILE)
for file in tar_file.getmembers():
file_name = os.path.basename(file.name)
if 'frozen_inference_graph.pb' in file_name:
tar_file.extract(file, os.getcwd())
#Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
#Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
#Helper code
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# For the sake of simplicity we will use only 2 images:
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
# Path to the test images
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 4) ]
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score i
実験結果
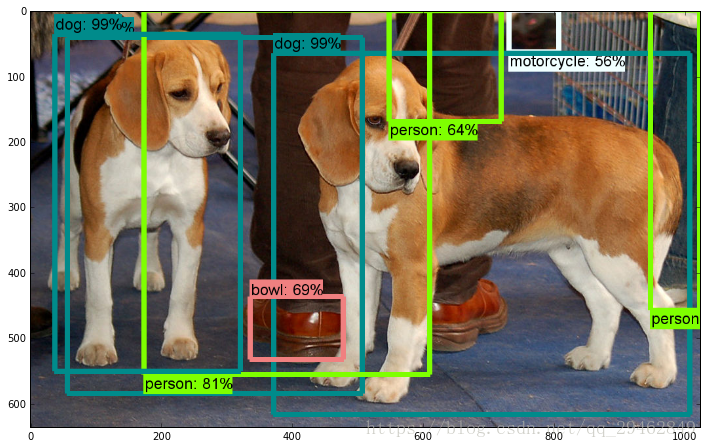
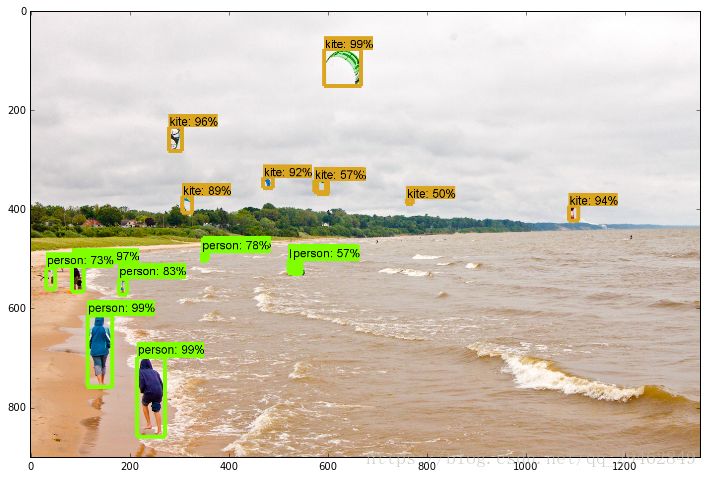
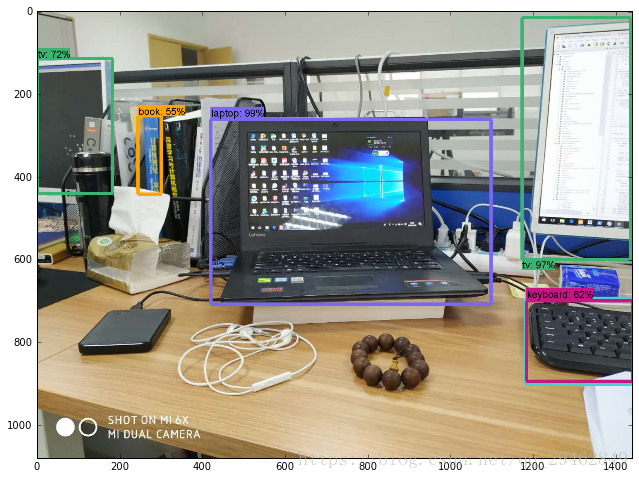
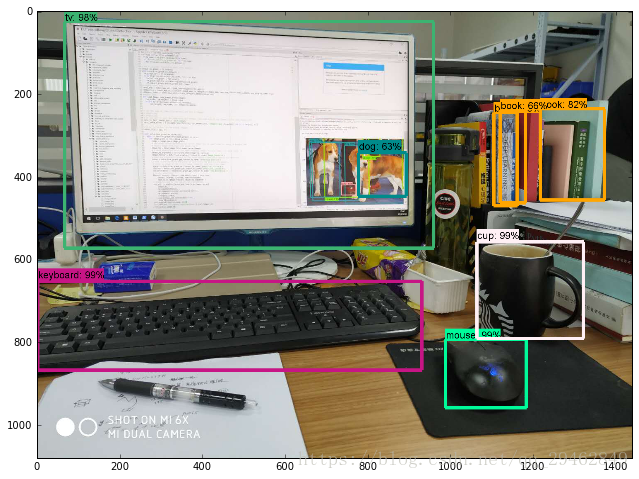

ソースコードへのリンクです。 より高速化されたR-CNNのソースコード
関連
-
ターゲット検出ベースモジュール(iou/giou/ciou/diou)のIoU概要
-
undefinedGoogLeNet 論文の翻訳 - 英語と中国語で書かれています。
-
ResNetの紹介
-
深層学習トラッキングアルゴリズム概要
-
Tensorflow 踩坑:ImportError: DLL のロードに失敗しました。指定されたモジュールが見つかりません。 TensorFlowのネイティブランタイムのロードに失敗しました。
-
ImportError: libSM.so.6: cannot open shared object file: そのようなファイルやディレクトリはありません
-
PackagesNotFoundError: 次のパッケージは、現在のチャンネルから利用できません ソリューション
-
Tensorflowのメタフィジカルエラーです。終了コード -1073741819 (0xC0000005)
-
pytorchはエラーを報告します。ValueError: num_samples は正の整数値であるべきですが、num_samples=0 となりました。
-
Tensorflow-gpu2.0.0インストールとtensorflow-gpuインストール成功のテストプログラム。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
py-faster-rcnn/lib の make でエラー: コマンドラインオプション '-Wdate-time' が認識されない
-
xx.exe の 0x00007FF7A7B64FB3 でスローされた例外: 0xC0000005: 場所 0x00 を読み取るアクセス違反
-
OrderedDict' オブジェクトに 'eval' 属性がありません。
-
参照用シークレットを呼び出す:BN層詳細解説
-
Win10でanacondaのconda activateで環境起動時にエラーが出る場合はどうすればいいのでしょうか?
-
caffeのインストールで「error : too few arguments in function call」エラーが発生する。
-
TypeError: 'module' object is not callable solution to [Keras] call "merge".
-
ロジスティック回帰は2分法モデル
-
tensorflow experience code error Adding visible gpu devices: 0 , モジュール 'tensorflow' には 'Session' という属性がありません。
-
AttributeError: 'tuple' オブジェクトには 'log_softmax' という属性がありません。