undefinedGoogLeNet 論文の翻訳 - 英語と中国語で書かれています。

記事:タイアン
ブログ
ノアスネイルドットコム
|n
CSDN
|
ジェーンの本
声明 著者は学習のためだけに論文を翻訳しています。もし侵害があれば、著者に連絡してブログ記事を削除してください。
翻訳された論文の概要 https://github.com/SnailTyan/deep-learning-papers-translation
コンボリューションの深化
概要
ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14)において、分類と検出のための新しい状態を達成した、コードネームInceptionと呼ばれる深い畳み込みニューラルネットワークのアーキテクチャを提案します。このアーキテクチャの主な特徴は、ネットワーク内部の計算機資源の利用率を向上させたことです。綿密な設計により、計算機バジェットを一定に保ちながら、ネットワークの深さと幅を拡大しました。品質を最適化するため、アーキテクチャの決定はヘブの原理とマルチスケール処理の直感に基づき行われました。ILSVRC14への投稿で使用された特定の化身はGoogLeNetと呼ばれる22層の深いネットワークで、その品質は分類と検出の文脈で評価されています。
ImageNet Large Scale Visual Recognition Challenge 2014(ILSVRC14)において、コードネームInceptionと呼ばれる深層畳み込みニューラルネットワークのアーキテクチャを発表し、分類と検出において新たにベストの結果を得ました。このアーキテクチャの最大の特徴は、ネットワーク内部の計算資源の利用率を向上させたことです。慎重な手動設計により、計算機予算を一定に保ちつつ、ネットワークの深さと幅を拡大しました。品質を最適化するために、Herbの理論やマルチスケール処理の直感に基づいてアーキテクチャを設計しています。ILSVRC14の投稿で適用した特別なケースはGoogLeNetと呼ばれる22層の深層ネットワークで、その品質は分類と検出の文脈で評価されました。
1. はじめに
この3年間で、深層学習と畳み込みネットワークの進歩により、私たちの物体分類・検出能力は劇的に向上しました[10]。1つの心強いニュースは、この進歩のほとんどは、より強力なハードウェア、より大きなデータセットとより大きなモデルの結果だけでなく、主にa No new data sources were used, for example, by the top entries in the ILSVRC 2014 新しいデータソースは、例えば、検出目的で同じ大会の分類データセット以外にILSVRC 2014大会の上位エントリで使用されませんでした。2年前のKrizhevskyら[9]の受賞アーキテクチャと比較して、12倍少ないパラメータで、大幅に精度が向上しています。検出の前では、最大の利益は、より大きく、より大きなディープネットワークのナイーブなアプリケーションからではなく、Girshickら[6]のR-CNNアルゴリズムのように、深いアーキテクチャと古典的コンピュータビジョンの相乗からもたらされています。
1.はじめに
過去3年間、深層学習と畳み込みネットワークの発展により、ターゲットの分類と検出において大きな改善が見られました[10]。心強いニュースの一つは、進歩のほとんどが、より強力なハードウェア、より大きなデータセット、より大きなモデルの結果ではなく、主に新しいアイデア、アルゴリズム、ネットワーク構造の改良の結果であることです。例えば、ILSVRC 2014コンペティションのトップインプットは、検出目的で使用した分類データセット以外に新しいデータソースを使用していません。ILSVRC 2014で私たちが提出したGoogLeNetは、実際には2年前のKrizhevskyら[9]の優勝構造の12分の1のパラメータを使用していましたが、結果は大幅に精度を向上させました。ターゲット検出の最前線では、ますます大規模になるディープネットワークの単純な適用ではなく、Girshickら[6]のR-CNNアルゴリズムのように、ディープアーキテクチャと古典的コンピュータビジョンの相乗効果から最大の利益がもたらされます。
また、モバイルや組込みコンピューティングの普及に伴い、アルゴリズムの効率が向上していることも特筆すべき点です。 本論文で紹介するディープアーキテクチャの設計に至る考察は、精度の数値にこだわるのではなく、この要素を含んでいたことが特筆されます。 実験、モデルのデザイン
この論文では、コードネームInceptionと呼ばれるコンピュータビジョン用の効率的なディープニューラルネットワークアーキテクチャに焦点を当てます。この名前は、Linらのネットワーク論文[12]のNetworkと、有名な "we need to go deeper" network muse [1] の組み合わせから取られたものです。我々の場合、"deep"という言葉は2つの異なる意味で使われている。まず、ある意味で、我々は"Inceptionモジュール"という形で新しいレベルの組織を導入し、より直接的な意味で それはネットワークの深さを増大させる。一般に、Inceptionモデルは、Aroraら[2]の理論的研究に触発され、導かれながら、論文[12]の論理的頂点として見ることができる。このアーキテクチャの利点は、ILSVRC 2014 Classification and Detection Challengeにおいて実験的に検証され、現在のベストを大幅に上回った。
2. 関連研究
LeNet-5 [10]に始まり、畳み込みニューラルネットワーク(CNN)は典型的な標準構造を有している -- スタック型 LeNet-5 [10]に始まり、畳み込みニューラルネットワーク(CNN)は典型的な標準構造を有している -- スタック型畳み込み層(オプションでコントラスト正規化と最大プーリングが続く)に、1層以上の完全連結層が続く。この基本設計は、画像分類の文献で一般的であり、MNIST、CIFAR、そして最も顕著なImageNet分類課題[9, 21]において、現在までに最良の結果を得ています。Imagenetのような大規模データセットでは、最近の傾向として、層数[12]と層サイズ[21, 14]を増やし、ドロップアウト[7]を用いてオーバーフィットの問題に対処しています。
2. 最近の研究成果
LeNet-5 [10]に始まり、畳み込みニューラルネットワーク(CNN)は一般的に標準的な構造を持っています - 畳み込み層を積層し(オプションでコントラスト正規化と最大プーリングが続く)、1つ以上の完全連結層が続きます。この基本設計のバリエーションは、画像分類作業において人気があり、これまでのところ、MNIST、CIFAR、そしてより有名なImageNet分類課題において最高の結果を達成しています[9, 21]。ImageNetのような大規模データセットでは、最近の傾向として、層数[12]と層サイズ[21, 14]を増加させ、ドロップアウト[7]を用いてオーバーフィットの問題に対処しています。
最大プール層は正確な空間情報を失うという懸念があるが、[9] と同じ畳み込みネットワークアーキテクチャは、ローカライゼーション [9, 14]、物体検出 [6, 14, 18, 5]、人間の姿勢推定 [19] にも採用され成功している。
最大プーリング層による正確な空間情報の損失が懸念されるが、[9]と同じ畳み込みネットワーク構造は、ローカリゼーション[9、14]、物体検出[6、14、18、5]、歩行者姿勢推定[19]にも採用され、成功している。
霊長類の視覚野の神経科学モデルに触発されたSerreら[15]は、異なるサイズの一連の固定ガボールフィルターを使用して、複数の処理を行った。しかし、[15]の固定2層深層モデルとは異なり、Inceptionアーキテクチャのすべてのフィルタは学習されます。さらに、Inceptionの層は何度も繰り返され、GoogLeNetモデルの場合、22層のディープモデルになります。
霊長類の視覚野の神経科学的モデルに触発されて、Serre ら [15] は複数のスケールを扱うために、異なるサイズの一連の固定ガボールフィルターを使用しました。我々は同様の戦略を用いた。しかし、[15]の固定2層深度モデルとは対照的に、Inception構造の全てのフィルタは学習される。また、GoogLeNetモデルでは22層の深度モデルを得るために、Inception層を何度も繰り返している。
ネットワーク・イン・ネットワークとは、ニューラルネットワークの表現力を高めるためにLinら[12]が提案したアプローチである。彼らのモデルでは、1×1畳み込み層をさらに追加して、ネットワークの深さを増している。
ネットワーク・イン・ネットワークは、ニューラルネットワークの性能能力を向上させるために Lin ら [12]が提案したアプローチである。彼らのモデルでは、1×1の畳み込み層を追加し、ネットワークの深さを増している。このアプローチは我々のアーキテクチャでも多用されている。しかし、我々のセットアップでは、1×1畳み込みは2つの目的を果たす。最も重要なのは、主に次元削減モジュールとして使用し、さもなければネットワークのサイズが制限される畳み込みのボトルネックを除去することである。これにより、深さを増すことができるだけでなく、ネットワークの幅を増やしても、性能を大きく落とすことなく、深さを増すことができる。
最後に、物体検出の現状として、Girshick らによる Regions with Convolutional Neural Networks (R-CNN) 法がある[6]。R-CNNは、全体的な検出問題を2つのサブ問題に分解する:カテゴリーにとらわれない方法でオブジェクトの位置提案を生成するために、色やテクスチャなどの低レベルのキューを利用し、それらの位置でオブジェクトカテゴリーを識別するためにCNN分類器を使用することである。このような2段階のアプローチは、低レベルのキューを用いたバウンディングボックスセグメンテーションの精度と、最先端のCNNの非常に強力な分類能力を活用するものである。このような2段階のアプローチは、低レベルのキューを用いたバウンディングボックスセグメンテーションの精度と、最先端のCNNの非常に強力な分類能力を活用するものです。
最後に、ターゲット検出に対する現在の最良のアプローチは、Girshickらの地域ベースの畳み込みニューラルネットワーク(R-CNN)アプローチです[6]。R-CNNは、検出問題全体を2つのサブ問題に分解します:色、テクスチャなどの低レベルの信号を使用して、カテゴリ横断的にターゲット位置候補領域を生成し、次にCNN分類器を使用してそれらの場所でオブジェクトクラスを識別します。このような2段階のアプローチは、低レベル特徴セグメンテーションのバウンディングボックスの精度と、現在のCNNの非常に強力な分類能力を利用するものである。また、バウンディングボックスの候補領域を分類するためのより良い方法を取り入れるなど、両方の段階を強化することを検討しました。
3. 動機とハイレベルな考察
ディープニューラルネットワークの性能を向上させる最も簡単な方法は、そのサイズを大きくすることです。これには深さ(ネットワークレベルの数)と幅(各レベルのユニット数)の両方を増やすことが含まれます。これは、特にラベル付けされた大量のトレーニングデータが利用可能な場合、より高品質のモデルをトレーニングするための簡単で安全な方法です。しかし、この単純な方法には2つの大きな欠点がある。
これは、強くラベル付けされたデータセットの入手に手間とコストがかかるため、大きなボトルネックとなっている。強くラベル付けされたデータセットの入手には手間とコストがかかり、図1に示すようにImageNet(1000クラスのILSVRCサブセットでも)のような様々な細かな視覚カテゴリを区別するためには、専門の人間の評価者が必要となる場合が多い。

図1:ILSVRC 2014の分類チャレンジの1000クラスから、2つの異なるクラス。
3. モチベーションとハイレベルな思考
ディープニューラルネットワークの性能を向上させる最も簡単な方法は、そのサイズを大きくすることです。これには、深さ(ネットワークの層の数)だけでなく、幅(層ごとのユニットの数)を増やすことも含まれます。これは、特にラベル付けされた大量の学習データが利用可能な場合、より質の高いモデルを訓練するための簡単で安全な方法です。しかし、この単純な方法には2つの大きな欠点がある。サイズが大きくなるということは、通常、パラメータが増えるということであり、特に訓練セットのラベル付きサンプル数が限られている場合、大きくなったネットワークはオーバーフィットしやすくなる可能性がある。これは、強くラベル付けされたデータセットを得るには時間とコストがかかり、図1のImageNet(あるいは1000クラスのILSVRCのサブセット)のような様々な細かな視覚カテゴリを区別するために専門家の判断が必要となることが多いため、大きなボトルネックとなる。

図1:ILSVRC2014分類チャレンジの1000分類の中の2種類の分類。これらのカテゴリーを区別するには、ドメイン知識が必要である。
ネットワークサイズを一律に大きくすることのもう一つの欠点は、計算機資源の使用量が劇的に増えることです。例えば,ディープビジョンネットワークにおいて,2つの畳み込み層が連鎖している場合,そのフィルタの数を一様に増やすと,計算量が2次関数的に増加することになる.
また、ネットワークサイズを均一に大きくすると、計算機資源の使用量が大幅に増えるという欠点があります。例えば、ディープビジョンネットワークにおいて、2つの畳み込み層が接続されている場合、そのフィルターの数を一律に増やすと、計算容量が一様に増加する。増加した計算能力が非効率的に使われる場合(例えば、ほとんどの重みがゼロに近くなってしまう場合)、大量の計算能力が無駄になってしまう。計算予算は常に有限であるため、計算資源の効率的な配分は、たとえ性能の質を高めることが第一の目的であっても、サイズが無差別に増加する方に偏ってしまうのである。
これらの問題を解決する根本的な方法は、スパース性を導入し、完全連結層をスパースなものに置き換えることである。また、生体システムを模倣する以外にも、Aroraらの画期的な仕事により、より強固な理論的裏付けが得られるという利点もある[2]。彼らの主な結果は、データセットの確率分布が大規模で非常にスパースなディープニューラルネットワークによって表現可能であれば、先行する層の活性化の相関統計を分析することによって、最適なネットワークトポロジーが層ごとに構築できるとしている。 厳密な数学的証明は非常に強い条件を必要とするが、この文がよく知られたヘブの原理--一緒に発火するニューロンは一緒に配線する--に共鳴するという事実は、基本となる考えが、実際には、それほど厳しい条件のもとでも応用可能であるということを示唆するものである。
この2つの問題を解決する基本的な方法は、スパース性を導入し、完全連結層をスパースな完全連結層、あるいは畳み込み層に置き換えることです。生物学的なシステムを模倣するだけでなく、Aroraらの先駆的な研究により、より強固な理論的基盤を持つという利点もある[2]。彼らの主な結果は、データセットの確率分布が大規模なスパースディープニューラルネットワークで表現できる場合、前の層の活性化の相関統計量を分析し、相関の高いニューロンをクラスタリングすることによって、最適なネットワークトポロジーが層ごとに構築できることを示している。非常に強い条件下では厳密な数学的証明が必要ですが、この文がよく知られたハーブの理論-ニューロンは一緒に興奮し、一緒につながる-と共鳴することは、それほど厳しくない条件下でも基礎となる概念が適用されることを実際に示しています。
残念ながら,現在のコンピューティングインフラは,非一様なスパースに対する数値計算に関しては非常に非効率です. 算術演算の数を 100 倍に減らしたとしても,ルックアップとキャッシュミスのオーバーヘッドが支配的であり,この差は,CPU または GPU ハードウェアの微細な部分を利用して非常に高速な密行列乗算を可能にし,着実に向上して高度に調整されている数値ライブラリの使用によってさらに拡大します [16,9].また、非一様なスパースモデルは、より洗練されたエンジニアリングとコンピューティングインフラを必要とします。現在のビジョン指向の機械学習システムのほとんどは、コンボリューションを採用することにより、空間領域でのスパース性を利用している。しかし,畳み込みは,空間領域におけるスパース性を確保するために,共起演算として実装されている.
残念ながら、現在の計算機アーキテクチャでは、不均一なスパースデータ構造に対する数値計算が非常に非効率的である。アルゴリズム演算の数が100分の1になったとしても、クエリーやキャッシュミスのオーバーヘッドが大きく、スパース行列への切り替えは現実的ではありません。このギャップは、着実に改善され、高度にチューニングされた数値計算ライブラリの採用により、さらに拡大します。これらのライブラリは、基盤となるCPUまたはGPUハードウェアの微細な部分を利用して、極めて高速かつ高密度な行列の乗算を必要とします[16, 9]。また、非一様なスパースモデルは、より複雑なエンジニアリングと計算インフラを必要とします。現在のビジョン指向の機械学習システムのほとんどは、畳み込みの利点を利用することで、ヌル領域のスパース性を利用している。しかし、畳み込みは上層のブロックの密結合セットとして実装されている。しかし、論文[9]では、並列計算をより最適化するために、完全連結に戻す傾向がある。現在の最先端のコンピュータビジョンアーキテクチャは、統一された構造を持っている。より多くのフィルタとより大きなバッチサイズにより、密な計算を効率的に使用する必要がある。
これは、次の中間的なステップ、つまり、理論が示唆するようなフィルターレベルのスパース性を利用するアーキテクチャに希望があるかどうかという問題を提起しています。のように,疎行列を比較的密な部分行列にクラスタリングすると,疎行列の乗算で競争力のある性能が得られる傾向があることが示唆されています.近い将来、同様の手法が非一様な深層学習アーキテクチャの自動構築に利用されると考えるのは、決して突飛なことではないように思われる。
つまり、理論が示唆するように、フィルタレベルのスパース性を利用しつつ、密な行列計算を利用することで現在のハードウェアを活用できるアーキテクチャが有望なのではないかという疑問が生まれます。疎行列の乗算に関する広範な文献([3]など)は、疎行列の乗算では、疎行列を比較的密な部分行列にクラスタリングすることで性能が向上することを論じている。近い将来、非一様な深層学習アーキテクチャの自動構築のために同様のアプローチが利用されるという考えは、遠い未来の話ではないように思われます。
Inceptionアーキテクチャは、視覚ネットワークに対して[2]によって暗示された疎な構造を近似し、密で読みやすいによって仮説の結果をカバーしようとする高度なネットワークトポロジー構築アルゴリズムの仮説の出力を評価するケーススタディとして開始した。 非常に推測的な事業であるにもかかわらず、[12]に基づく参照ネットワークと比較すると初期に適度な利益が観測された。Inceptionは[6]と[5]のベースネットワークとして、ローカライゼーションとオブジェクト検出のコンテキストで特に有用であることが証明されました。興味深いことに、当初のアーキテクチャの選択のほとんどが、分離の際に疑問視され、徹底的にテストされたものの、それらは、以下のように近いことが判明しました。 One must be cautious though: Inceptionアーキテクチャはコンピュータビジョンにとって成功となったが、まだ疑問がある One must be cautious though: Inceptionアーキテクチャはコンピュータビジョンにとって成功となったが、これがその構築につながった指針に起因しているかどうかはまだ疑問がある。
インセプションのアーキテクチャは、非常に重要な部分です。
Inceptionアーキテクチャは、[2]で示された視覚ネットワークの疎な構造を近似し、密でアクセスしやすいコンポーネントで仮説の結果を上書きしようとする複雑なネットワークトポロジー構築アルゴリズムの仮想出力を評価するケーススタディとして始まりました。非常に推測的な事柄ではあるが、[12]に基づく参照ネットワークと比較して、早い段階で適度な利得が観察される。Inceptionは、その差を広げるために少しチューニングすることで、[6]と[5]のローカリゼーションコンテキストとターゲット検出のためのベースネットワークとして特に有用であることが証明されました。興味深いことに、初期のアーキテクチャの選択のほとんどは疑問視され、完全なテストのために分離されましたが、それらは局所的に最適であることが判明しました。しかし、注意しなければならないのは、コンピュータ・オン・コンピュータの領域でInceptionアーキテクチャが成功したにもかかわらず、そのアーキテクチャを構築するために使用された指導原理に起因するかどうかは疑問が残るということです。このことを確認するためには、より徹底的な分析と検証が必要です。
4. アーキテクチャの詳細
Inceptionアーキテクチャの主なアイデアは、畳み込みビジョンネットワークの最適な局所スパース構造がどのように近似されるかを考えることである。Aroraら[2]はレイヤーごとの構築を提案している Aroraら[2]は、最後のレイヤーの相関統計値を分析し、相関の高いユニットのグループにクラスタリングすることを提案している。下の層(入力に近い層)では、相関のあるユニットが局所的に集中するため、1つの領域に多くのクラスタが集中し、[12]で提案されているように、次の層で1×1畳み込みの層でカバーすることができると仮定している。しかし,より大きなパッチの畳み込みによってカバーできる,より空間的に広がったクラスタの数は少なくなり,より大きな領域でのパッチの数は減少していくことも予想される。パッチアライメントの問題を回避するために、現在のInceptionアーキテクチャは、1×1、3×3、5×5のフィルターサイズに制限されています。
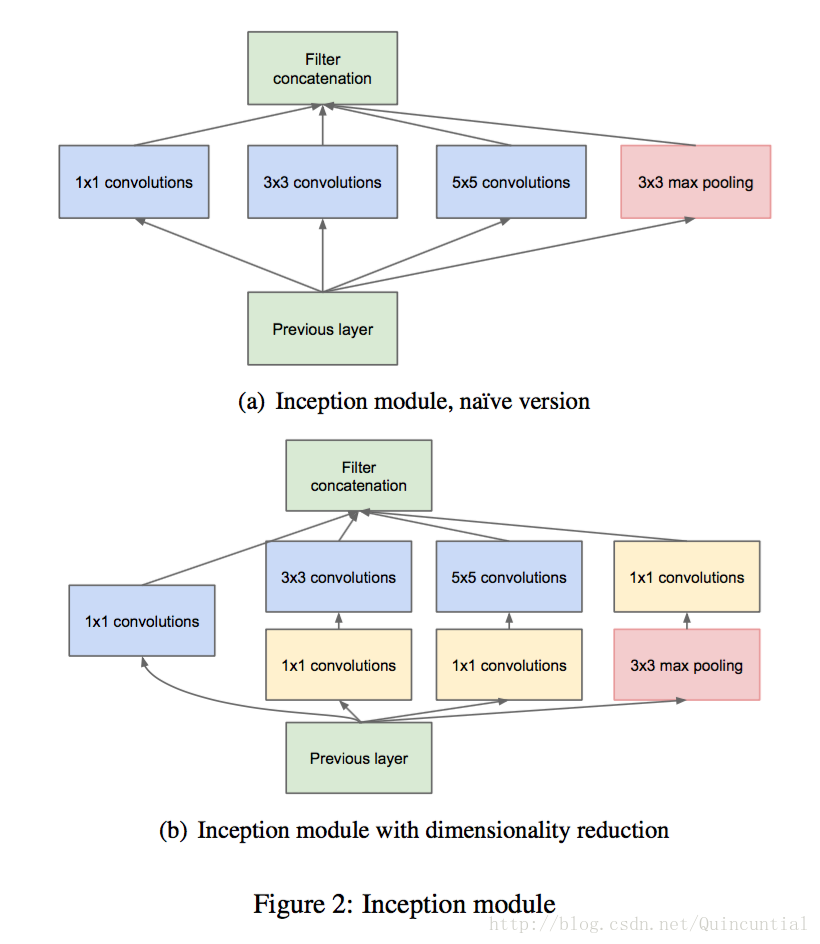
4. アーキテクチャの詳細
Inceptionアーキテクチャの主な考え方は、畳み込み視覚ネットワークの最適な疎構造を近似し、簡単にアクセスできる密なコンポーネントでカバーする方法を検討することである。変換不変性を仮定していることに注意してください。これは、私たちのネットワークが畳み込みのビルディングブロックに基づくことを意味します。Aroraら[2]は、最後の層の相関統計量を分析し、相関の高いユニットのグループにクラスタリングする階層を提案した。これらのクラスターは次の層のユニットを形成し、前の層のユニットと接続される。先の層の各セルは入力層のある領域に対応し、これらのセルはフィルタセットにグループ化されていると仮定する。下位の層(入力に近い層)では、関連するセルが局所的な領域に集中している。このように、[12]で示したように、結局は多くのクラスタが一つの領域に集中し、次の層の 1×1 畳み込み層でカバーすることができるのである。しかし、より大きなブロックでの畳み込みによってカバーできる、より大きな空間に広がるクラスタの数は少なく、ブロックの数はますます大きな領域で減少することも予想される。ブロック補正の問題を回避するために、現在のInceptionアーキテクチャの形態では、フィルタのサイズを1×1、3×3、5×5に限定しているが、これは必要性というよりも利便性に基づいて決定されたものである。これは、提案するアーキテクチャが、これらすべての層の出力フィルタバンクを組み合わせて、次のステージの入力となる1つの出力ベクトルに接続するものであることも意味しています。また、プーリング操作は現在の畳み込みネットワークの成功に不可欠であるため、そのような各ステージで代替の並列プーリングパスを追加することを提案し、さらに有益な効果をもたらすべきである(図2(a)参照)。
これらのquot;Inceptionモジュールを積み重ねると、その出力相関統計は変化する。より抽象度の高い特徴がより高い層で捉えられると、その空間的な集中度は減少すると予想される。このことは、3×3畳み込みと5×5畳み込みの比率が、高階層に行くに従って増加することを示唆している。
これらのquot;Inceptionモジュールが積み重なると、その出力の相関統計は変化するはずで、より高い層がより抽象度の高い特徴を捉えるようになると、その空間的な集中度は減少すると予想される。このことは、3×3と5×5の畳み込みの割合が、より高いレベルに移るにつれて増加するはずであることを示唆している。
上記のモジュールの大きな問題の一つは、少なくともこの素朴な形では、適度な数の5×5畳み込みでさえ、法外なコストがかかることである。この問題は、プーリングユニットがミックスに加えられるとさらに顕著になる。 プーリング層の出力を畳み込み層の出力とマージするプーリング層の出力を畳み込み層の出力とマージすると、ステージごとに出力数が必然的に増加することになる。このアーキテクチャは最適なスパース構造をカバーするかもしれないが、非常に非効率的であり、数ステージで計算量が爆発的に増加することになる。
上記のモジュールの大きな問題は、多数のフィルタを持つ畳み込み層の上に、適度な量の5×5畳み込みを行ったとしても、少なくともこの単純な形では、非常にコストがかかるということである。この問題は、プーリングユニットが追加されるとさらに顕著になる。出力フィルターの数は、前段のフィルターの数と等しくなる。プーリング層出力と畳み込み層出力のマージは、このステージから次のステージへの出力数の増加を不可避にする。このアーキテクチャは最適なスパース構造をカバーするかもしれないが、非常に非効率で、数ステージで計算が爆発する可能性がある。
これは、エンベッディングの成功に基づくもので、低次元のエンベッディングであっても、比較的多くの情報を含んでいる可能性があります。つまり、1×1畳み込みは、高価な3×3畳み込みや5×5畳み込みの前に、縮小計算に使われるのです。最終的な結果は図2(b)に描かれている。
これは、Inceptionアーキテクチャの2つ目のアイデアである、計算量が増えすぎてしまう次元を賢く削減することにつながります。これは、埋め込み処理の成功に基づくものです。低次元の埋め込み処理であっても、より大きな画像ブロックに関する多くの情報を含んでいる可能性があります。しかし、エンベッディングは情報を高密度で圧縮した形で表現しており、圧縮された情報は処理が非常に困難です。このような表現は、([2]の条件により)ほとんどの場所でスパースのままであるべきで、信号を集約する必要があるときだけ圧縮する必要があります。つまり、1×1畳み込みは、高価な3×3畳み込みや5×5畳み込みの前に次元削減の計算をするために使われる。また、次元削減のために使用するだけでなく、線形補正ユニットを使用することで兼用化することも含まれている。最終的な結果は、図2(b)のようになる。
一般に、Inceptionネットワークは、上記のタイプのモジュールを互いに積み重ねたネットワークであり、時折、Max-poolingレイヤーを使用します。 技術的理由(トレーニング時のメモリ効率)のために、Inceptionを使い始めることが有益と思われました。 技術的理由(トレーニング時のメモリ効率)のために、下位レイヤーを従来の畳み込み方式に保ち、上位レイヤーでのみInceptionモジュールを使い始めることが有益と思われました。これは厳密には必要ではなく、単に我々の現在の実装におけるインフラ的な非効率性を反映したものです。
一般に、Inceptionネットワークは、上記のタイプのモジュールを積み重ねたネットワークであり、ステップサイズ2の最大プーリング層はネットワークの解像度を半分にすることがある。技術的な理由(学習時のメモリ効率)から、下位層では従来の畳み込み形式を維持したまま、上位層でのみInceptionモジュールを使用し始めることが有益であると思われます。これは絶対に必要というわけではなく、単に我々の現在の実装におけるインフラの非効率性を反映したものです。
また、視覚情報は様々なスケールで処理された後、次のステージで異なるスケールから同時に特徴を抽出できるように集約されるべきであるという実用的な直観に従った設計となっています。
このアーキテクチャの有用な点は、後段で計算複雑度が無秩序に爆発することなく、1段あたりのセル数を大幅に増やすことができる点です。これは、より大きなサイズのブロックの高価な畳み込みの前に、次元削減を一般的に使用することによって達成される。さらに、視覚情報は異なるスケールで処理され、集約されるべきであるという実用的な直観に従って設計されており、次のステージでは異なるスケールから同時に特徴を抽出できるようになっている。
計算機資源の利用が改善されたことで、各ステージの幅とステージの数を増やすことができます。Inceptionアーキテクチャを利用して、少し劣るが計算量の少ないバージョンを作ることができます。
計算機資源の利用が改善されたことで、計算量の制約を受けることなく、各ステージの幅やステージ数を増やすことができるようになりました。少し悪くても計算量の少ないバージョンをInceptionアーキテクチャを使用して作成することができます。利用可能なすべての制御により、計算資源のバランスを制御することができ、その結果、Inceptionアーキテクチャを使用せずに同様に実行したネットワークよりも3~10倍高速になることがわかりましたが、この時点では慎重な手動設計が必要です。
5. GoogLeNet
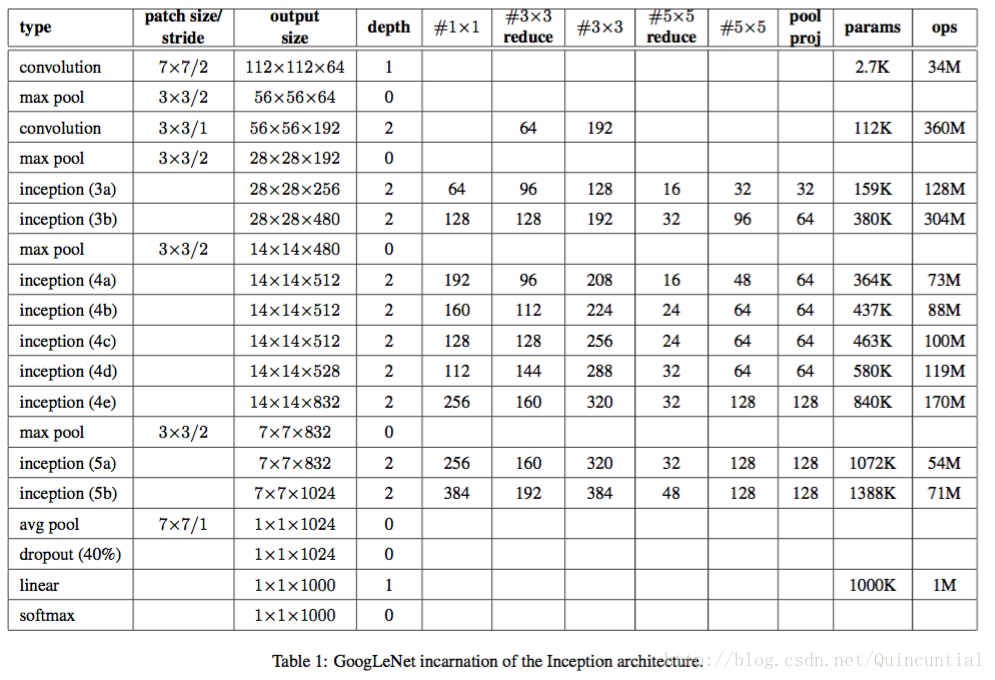
GoogLeNet"という名称は、私たちが「GeogLeNetコンテスト」に応募した際に使用したInceptionアーキテクチャの具体的な姿を指しています。 より深く、より広いInceptionネットワークも使用しましたが、若干品質が優れており、アンサンブルに追加した方が良いと思われました。表1は、コンペティションで使用された最も一般的なInceptionのインスタンスを示しています。このネットワーク(異なる画像パッチサンプリング手法で学習)は、アンサンブルの7つのモデルのうち6つに使用されました。
5. GoogLeNet
GoogLeNet"という名前で、ILSVRC 2014のコンペティション応募で使用されたInceptionアーキテクチャの特殊なケースについて触れています。また、少し優れたより深く広いInceptionネットワークも使用しましたが、これを追加しても結果はほんの少ししか改善されないようです。経験則から、正確なアーキテクチャのパラメータは比較的影響が小さいと考えられるため、このネットワークの詳細については無視します。表1は、コンペティションで使用された最も一般的なInceptionの例を示しています。このネットワーク(異なるイメージブロックサンプリング手法で学習)は、私たちのポートフォリオの7つのモデルのうち6つを使用しています。

Inceptionモジュール内を含む全ての畳み込みは、整流化された線形活性化を用いている。このネットワークの受容野の大きさは、RGB色空間において224×224で、平均は0である。 "#3×3 reduce" と "#5×5 reduce" は、quot.quot.quot.quot.の略である。 これらの縮小/投影層は全て同様にrectified linear activateを使用している。
Inceptionモジュール内の畳み込みも含め、すべての畳み込みは整流化された線形活性化を用いている。このネットワークでは、知覚野は平均0、サイズ224×224のRGB色空間となっている。1×1フィルタの数はpool projの欄に表示される。pool proj 列には、ビルトイン最大プーリング後の投影レイヤーの 1×1 フィルタの数が表示されています。これらのダウンスケール/投影層はすべて、線形補正活性化も使用しています。
このネットワークは、計算効率と実用性を考慮して設計されたものであり、個々のデバイスでも推論が実行できるようになっている。ネットワーク構築に使用される層(独立したビルディングブロック)の数は、全体で約100層である。しかし、このような場合、ネットワークがどのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能するのか、どのように機能をするのか、どのように機能をするのか、どのように機能をするのか、どのように機能をするのか、どのような機能をするのか、どのように機能をするのか、どのように機能をするのか、そのように機能を機能をするのか、そしてその機能を機能をするのか、その機能をするために必要なものは、どのように機能するのか、そしてその機能を機能をするために何ができるのか。
このネットワークは、計算機資源の限られたデバイス、特にメモリフットプリントの少ないデバイスでも推論を実行できるように、計算効率と実用性を考慮して設計されています。パラメータを持つ層のみを計算する場合、ネットワークは22層(プーリング層も計算する場合は27層)となる。ネットワークを構築するための全レイヤー(独立した構成要素)の数は、約100である。正確な数は機械学習基盤がどのように層を計算するかに依存する。分類器の前の平均プーリングは[12]に基づいているが、我々の実装には追加の線形層がある。この線形層は我々のネットワークが他のラベルのセットに容易に適応することを可能にするが、それは主に使いやすさを目的としており、我々はそれが大きな影響を持つことを期待しない。我々は、完全連結層から平均プーリングに変更することで、性能が約
top-1 %0.6
の精度を向上させることができましたが、完全連結層を取り除いた後でも、まだmissingの使用は不可欠です。
ネットワークの深さが比較的大きい場合、勾配を効果的に全層に伝搬させることができるかどうかが懸念された。この課題に対して浅いネットワークが高い性能を示したことから、ネットワークの中間層で生成される特徴が非常に重要であることが示唆された。 この中間層に接続された補助分類器を追加することで、分類器の下層における識別が正則化され、vanish gradient 問題に対処できると考えられた。これらの分類器は、Inception()の出力の上に置かれた、より小さな畳み込みネットワークの形をとっている。
给定深度相对较大的网络,有效传播梯度反向通过所有层的能力是一个问题。在这个任务上,更浅网络的強性能表明网络中部层产生的特征应该是非常有识别力的通将辅助分器添加到中间层,可以期望低阶段的类别力,以被认为是在添接正则化同时克服度消失问题这些分器使扬较小涉的形式,放置在线课程。(4a)和邀請(4b)模块的输出之上。在训练期间,它们的损失以折权扣重(辅助分类器)损失的权重是0. 3)加到网络的整个损失,在推断时,这些辅助网络被丢弃,后面的控制实验表明辅助网络的影响先较小(约 0.5),只需要其中一个就能得同样的效果,也可能够成了这样的结果。
The exact structure of the extra network on the side, including the auxiliary classifier, is as follows:
- An average pooling layer with 5×5 filter size and stride 3, resulting in an 4×4×512 output for the (4a), and 4×4×528 for the (4d) stage.
- A 1×1 convolution with 128 filters for dimension reduction and rectified linear activation.
- A fully connected layer with 1024 units and rectified linear activation.
- A dropout layer with 70% ratio of dropped outputs.
- A linear layer with softmax loss as the classifier (predicting the same 1000 classes as the main classifier, but removed at inference time).
A schematic view of the resulting network is depicted in Figure 3.

Figure 3: GoogLeNet network with all the bells and whistles.
包括辅助分类器在内的附加网络的具体结构如下:
- 一个滤波器大小5×5,步长为3的平均池化层,导致(4a)阶段的输出为4×4×512,(4d)的输出为4×4×528。
- 具有128个滤波器的1×1卷积,用于降维和修正线性激活。
- 一个全连接层,具有1024个单元和修正线性激活。
- 丢弃70%输出的丢弃层。
- 使用带有softmax损失的线性层作为分类器(作为主分类器预测同样的1000类,但在推断时移除)。
最终的网络模型图如图3所示。

图3:含有的所有结构的GoogLeNet网络。
6. Training Methodology
GoogLeNet networks were trained using the DistBelief [4] distributed machine learning system using modest amount of model and data-parallelism. Although we used a CPU based implementation only, a rough estimate suggests that the GoogLeNet network could be trained to convergence using few high-end GPUs within a week, the main limitation being the memory usage. Our training used asynchronous stochastic gradient descent with 0.9 momentum [17], fixed learning rate schedule (decreasing the learning rate by 4% every 8 epochs). Polyak averaging [13] was used to create the final model used at inference time.
6. 训练方法
GoogLeNet网络使用DistBelief[4]分布式机器学习系统进行训练,该系统使用适量的模型和数据并行。尽管我们仅使用一个基于CPU的实现,但粗略的估计表明GoogLeNet网络可以用更少的高端GPU在一周之内训练到收敛,主要的限制是内存使用。我们的训练使用异步随机梯度下降,动量参数为0.9[17],固定的学习率计划(每8次遍历下降学习率4%)。Polyak平均[13]在推断时用来创建最终的模型。
Image sampling methods have changed substantially over the months leading to the competition, and already converged models were trained on with other options, sometimes in conjunction with changed hyperparameters, such as dropout and the learning rate. Therefore, it is hard to give a definitive guidance to the most effective single way to train these networks. To complicate matters further, some of the models were mainly trained on smaller relative crops, others on larger ones, inspired by [8]. Still, one prescription that was verified to work very well after the competition, includes sampling of various sized patches of the image whose size is distributed evenly between 8% and 100% of the image area with aspect ratio constrained to the interval [ 3 4 , 4 3 ] [ 3 4 , 4 3 ] . Also, we found that the photometric distortions of Andrew Howard [8] were useful to combat overfitting to the imaging conditions of training data.
图像采样方法在过去几个月的竞赛中发生了重大变化,并且已收敛的模型在其他选项上进行了训练,有时还结合着超参数的改变,例如丢弃和学习率。因此,很难对训练这些网络的最有效的单一方式给出明确指导。让事情更复杂的是,受[8]的启发,一些模型主要是在相对较小的裁剪图像进行训练,其它模型主要是在相对较大的裁剪图像上进行训练。然而,一个经过验证的方案在竞赛后工作地很好,包括各种尺寸的图像块的采样,它的尺寸均匀分布在图像区域的8%——100%之间,方向角限制为 [ 3 4 , 4 3 ] [ 3 4 , 4 3 ] 之间。另外,我们发现Andrew Howard[8]的光度扭曲对于克服训练数据成像条件的过拟合是有用的。
7. ILSVRC 2014 Classification Challenge Setup and Results
The ILSVRC 2014 classification challenge involves the task of classifying the image into one of 1000 leaf-node categories in the Imagenet hierarchy. There are about 1.2 million images for training, 50,000 for validation and 100,000 images for testing. Each image is associated with one ground truth category, and performance is measured based on the highest scoring classifier predictions. Two numbers are usually reported: the top-1 accuracy rate, which compares the ground truth against the first predicted class, and the top-5 error rate, which compares the ground truth against the first 5 predicted classes: an image is deemed correctly classified if the ground truth is among the top-5, regardless of its rank in them. The challenge uses the top-5 error rate for ranking purposes.
7. ILSVRC 2014分类挑战赛设置和结果
ILSVRC 2014分类挑战赛包括将图像分类到ImageNet层级中1000个叶子结点类别的任务。训练图像大约有120万张,验证图像有5万张,测试图像有10万张。每一张图像与一个实际类别相关联,性能度量基于分类器预测的最高分。通常报告两个数字:top-1准确率,比较实际类别和第一个预测类别,top-5错误率,比较实际类别与前5个预测类别:如果图像实际类别在top-5中,则认为图像分类正确,不管它在top-5中的排名。挑战赛使用top-5错误率来进行排名。
We participated in the challenge with no external data used for training. In addition to the training techniques aforementioned in this paper, we adopted a set of techniques during testing to obtain a higher performance, which we describe next.
- We independently trained 7 versions of the same GoogLeNet model (including one wider version), and performed ensemble prediction with them. These models were trained with the same initialization (even with the same initial weights, due to an oversight) and learning rate policies. They differed only in sampling methodologies and the randomized input image order.
- During testing, we adopted a more aggressive cropping approach than that of Krizhevsky et al. [9]. Specifically, we resized the image to 4 scales where the shorter dimension (height or width) is 256, 288, 320 and 352 respectively, take the left, center and right square of these resized images (in the case of portrait images, we take the top, center and bottom squares). For each square, we then take the 4 corners and the center 224×224 crop as well as the square resized to 224×224, and their mirrored versions. This leads to 4×3×6×2 = 144 crops per image. A similar approach was used by Andrew Howard [8] in the previous year’s entry, which we empirically verified to perform slightly worse than the proposed scheme. We note that such aggressive cropping may not be necessary in real applications, as the benefit of more crops becomes marginal after a reasonable number of crops are present (as we will show later on).
- The softmax probabilities are averaged over multiple crops and over all the individual classifiers to obtain the final prediction. In our experiments we analyzed alternative approaches on the validation data, such as max pooling over crops and averaging over classifiers, but they lead to inferior performance than the simple averaging.
我们参加竞赛时没有使用外部数据来训练。除了本文中前面提到的训练技术之外,我们在获得更高性能的测试中采用了一系列技巧,描述如下。
- 我们独立训练了7个版本的相同的GoogLeNet模型(包括一个更广泛的版本),并用它们进行了整体预测。这些模型的训练具有相同的初始化(甚至具有相同的初始权重,由于监督)和学习率策略。它们仅在采样方法和随机输入图像顺序方面不同。
- 在测试中,我们采用比Krizhevsky等人[9]更积极的裁剪方法。具体来说,我们将图像归一化为四个尺度,其中较短维度(高度或宽度)分别为256,288,320和352,取这些归一化的图像的左,中,右方块(在肖像图片中,我们采用顶部,中心和底部方块)。对于每个方块,我们将采用4个角以及中心224×224裁剪图像以及方块尺寸归一化为224×224,以及它们的镜像版本。这导致每张图像会得到4×3×6×2 = 144的裁剪图像。前一年的输入中,Andrew Howard[8]采用了类似的方法,经过我们实验证,其方法差略于我们提出的方案,我们注意到在实际应用中,是不必要的因為存在的际量数的裁像,更多就能裁像的好会得很微小(正我们后面展示的那样)。
- softmax概括率在多个裁剪图像上和所有单个分类器上进行平均,然后获得最终预察在我们的实验中,我们分析了验证数据的代方,如裁剪图像上的最大池化和分类器的平均,在它比格们简格的性能略...但是的过去。
この論文の残りの部分では、最終的な提出物の全体的な性能に寄与する複数の要因について分析する。
この記事の続きでは、最終提出物の全体的な性能に寄与する複数の要因について分析します。
最終的に、検証データ、テストデータともにトップ5の6.67%という誤差を獲得し、他の参加者の中で1位となりました。これは、2012年のSuperVisionと比較して56.5%、前年と比較して約40%の相対的な減少です。これは、過去3年間に外部データを用いて分類器を訓練したSuperVisionと比較して56.5%、前年度のベストアプローチ(Clarifai)と比較して約40%の相対的な減少になります。

コンテストの最後のコミットは、バリデーションとテストセットに対する最終的なコミットを取得します。
top-5 6.67%
のエラー率で、他の参加者の中で1位となりました。これは、分類器の学習に外部データを用いた2012年のSuperVision方式と比較して56.5%、前年の最優秀方式(Clarifai)と比較して約40%の相対的な削減を実現したことになります。表2は、過去3年間で最も成績の良かったいくつかの手法の統計データを示しています。

また、1つのモデルを使用する場合は、検証データ上でトップ1エラー率が最も低いモデルを選択しました。すべての数値は、テストデータの統計にオーバーフィットしないように、検証用データセットで報告されているすべての数値。

また、表3で使用したモデルの数と切り出した画像の数を変えることで、画像を予測する際の複数テストの選択肢の性能を解析的に報告する。

8. ILSVRC 2014 ディテクションチャレンジの設定と結果
ILSVRCの検出タスクは、画像中の物体を200のクラスから選択し、その周囲にバウンディングボックスを生成するものである。検出されたオブジェクトは、groundtruthのクラスと一致し、そのバウンディングボックスが50%以上重なる場合、正しいとみなされます(Jaccard indexを使用)。また,検出されたオブジェクトの外枠は誤検出とみなし,ペナルティを課す.結果は平均平均精度(mAP)で報告される.GoogLeNetによる検出のアプローチは[6]によるR-CNNと同様であるが、領域分類器としてInceptionモデルを追加している。さらに、領域提案ステップは、選択的探索[20]アプローチとマルチボックス[5]予測を組み合わせることによって、より高いオブジェクトのために改善されている。 誤検出の数を減らすために、スーパーピクセルサイズは2×で増加した。これにより、選択的探索アルゴリズムから得られる提案は半分になる。また、multi-box[5]のプロポーザルを200個追加した結果、[6]のプロポーザルの約60%になり、カバー率が92%から93%に向上した。プロポーザル数の削減とカバレッジの増加の全体的な効果は、単一モデルの場合の平均平均精度の1%の改善である。最後に、各領域を分類する際に6つのGoogLeNetsのアンサンブルを使用する。なお、R-CNNとは異なり、時間不足のためバウンディングボックス回帰は使用していない。
8. ILSVRC 2014 Detection Challengeの設定と結果
ILSVRC検出タスクは、画像中の物体のバウンディングボックスを200のカテゴリから生成するように設計されている。検出された物体は、実際のカテゴリと一致し、その境界ボックスが50%以上重なっていれば正解とする(Jaccard indexを使用)。関連性のない検出は誤検出として記録され、ペナルティを受ける。分類タスクとは異なり,各画像には複数のオブジェクトが含まれることもあれば,全く含まれないこともあり,また,それらのスケールは変動する可能性がある.GoogLeNet検出はR-CNN[6]に類似したアプローチを用いるが、領域分類器としてInceptionモジュールを追加している。さらに、領域生成ステップは、選択的探索[20]法とマルチボックス[5]予測を組み合わせることで、より高いターゲットバウンディングボックスリコールに改善された。また、誤検出を減らすために、超解像のサイズを2倍に拡大し、選択探索アルゴリズムの領域生成を半減させた。合計で200個の領域生成をマルチボックスの結果から補ったが、そのうちの約60%は[6]のために生成されたものであり、同時にカバレッジを92%から93%に向上させた。領域生成の回数を減らし、カバレッジを上げることによる全体的な影響としては、モデルが1つの場合の平均精度平均が1%向上した。最後に、1つの領域の分類を待つ場合、6つのGoogLeNetsを組み合わせて使用した。この結果、精度は40%から43.9%に向上した。なお、R-CNNとは対照的に、時間不足のためバウンディングボックス回帰は使用しなかった。
まず、検出結果の上位を報告し、検出タスクの第1回目からの進捗を示す。上位のチームはいずれも畳み込みネットワークを用いている。表 4 に公式スコアと各チームに共通する戦略を報告する。 外部データは通常、モデルの事前学習を行うための ILSVRC12 分類データである。いくつかのチームは、ローカリゼーションデータの使用についても言及している。ローカライズタスクのバウンディングボックスのかなりの部分は検出データセットに含まれていないため、このデータを用いて、分類と同じ方法で一般的なバウンディングボックスリグレッサを事前学習させることができる。分類と同じ方法で事前学習を行います。
関連
-
などの警告を出しながらFaster-RCNNを実行します。RuntimeWarning: invalid value encountered in greater_equal などの警告が表示されます。
-
xx.exe の 0x00007FF7A7B64FB3 でスローされた例外: 0xC0000005: 場所 0x00 を読み取るアクセス違反
-
参照用シークレットを呼び出す:BN層詳細解説
-
Tensorflowのメタフィジカルエラーです。終了コード -1073741819 (0xC0000005)
-
Win10でanacondaのconda activateで環境起動時にエラーが出る場合はどうすればいいのでしょうか?
-
カーネルが死んだようです」の解決法。自動的に再起動します" の解決方法
-
caffeのインストールで「error : too few arguments in function call」エラーが発生する。
-
Pytorch Deep Learningです。TypeError: 'builtin_function_or_method' object is not iterable エラーの解決方法
-
Tensorflow-gpu2.0.0インストールとtensorflow-gpuインストール成功のテストプログラム。
-
AttributeError: 'tuple' オブジェクトには 'log_softmax' という属性がありません。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
深層学習トラッキングアルゴリズム概要
-
tensorflowをインポートしています。ImportError: libcublas.so.9.0: cannot open shared object file: No such file or director
-
ImportError: libSM.so.6: cannot open shared object file: そのようなファイルやディレクトリはありません
-
OrderedDict' オブジェクトに 'eval' 属性がありません。
-
トーチの取り付けと使用
-
PackagesNotFoundError: 次のパッケージは、現在のチャンネルから利用できません ソリューション
-
U-netのソースコード解説(Keras編)
-
ロジスティック回帰は2分法モデル
-
AttributeError: モジュール 'pandas' には 'core' という属性がありません。
-
tensorflowエラーノート:PyCharmとAttributeErrorの下で様々なモジュールのインポートの問題:モジュール 'pandas.core.computation' は属性を持っていません。