pytorchのConv1dの詳細説明
ブロガーは転載を歓迎しますが、必ず出典を明記した上でオリジナルのリンクを貼ってください ありがとうございます。
(最初にまとめたときはこんなに多くの人に読んでもらえるとは思っていなかったし、質問も結構ありました。いつもCSDNにログインしていないため、コメントへの返信がタイムリーにできないことがあります。Zhihuをお使いの方は、プライベートメッセージで下記までご連絡ください。 Sunny.Xiaの個人ページ メッセージを見たら必ず返信します。メッセージを見たら、必ず間に合うように返信します。何ヶ月も返信なしでコメントしてる人には申し訳ないけど、ナイフで切らないでね。(本当に頻繁にログインしていません。記事を書いている時だけです)
テキスト分類のpytorchを勉強しているときに、1次元畳み込みを使い、その仕組みを理解するのに時間がかかり、Web上で詳しく説明しているブログがないので、記録しておくことにします。
Conv1d
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True).
-
in_channels(
int) - 入力信号のチャンネル.テキスト分類では、これは単語ベクトルの次元です。 -
out_channels(
int) - 畳み込みによって生成されるチャンネル.1次元の畳み込みと同じ数の out_channels が存在します. -
カーネルサイズ(
intまたはtuple) - 畳み込みカーネルのサイズ.畳み込みカーネルのサイズは (k,) で,2番目の次元は in_channels によって決定されるので,畳み込みサイズは実際には kernel_size*in_channels となります. -
ストライド(
intまたはtuple,optional) - コンボリューションステップ -
パディング (
intまたはtuple,optional) - 0で補完された入力の各辺の層数 -
ダイレーション(
intまたはtupleオプション``) - 畳み込みカーネルの要素間の間隔. -
グループ(
int,optional) - 入力チャンネルから出力チャンネルへのブロッキング接続の数. -
バイアス(
bool,optional) - もしbias=Trueを追加し、バイアスをかける。
一例です。
conv1 = nn.Conv1d(in_channels=256, out_channels=100,kernel_size=2)
input = torch.randn(32,35,256)
# batch_size x text_len x embedding_size -> batch_size x embedding_size x text_len
input = input.permute(0,2,1)
out = conv1(input)
print(out.size())
ここで32はbatch_size、35は最大文長、256は単語ベクトルである
1次元の畳み込みを再度入力する場合、32*35*256を32*256*35に変換する必要があるが、これは1次元の畳み込みが最後の次元で掃き出されるためで、最終的に出てくる大きさは 32*100*(35-2+1)=32*100*34
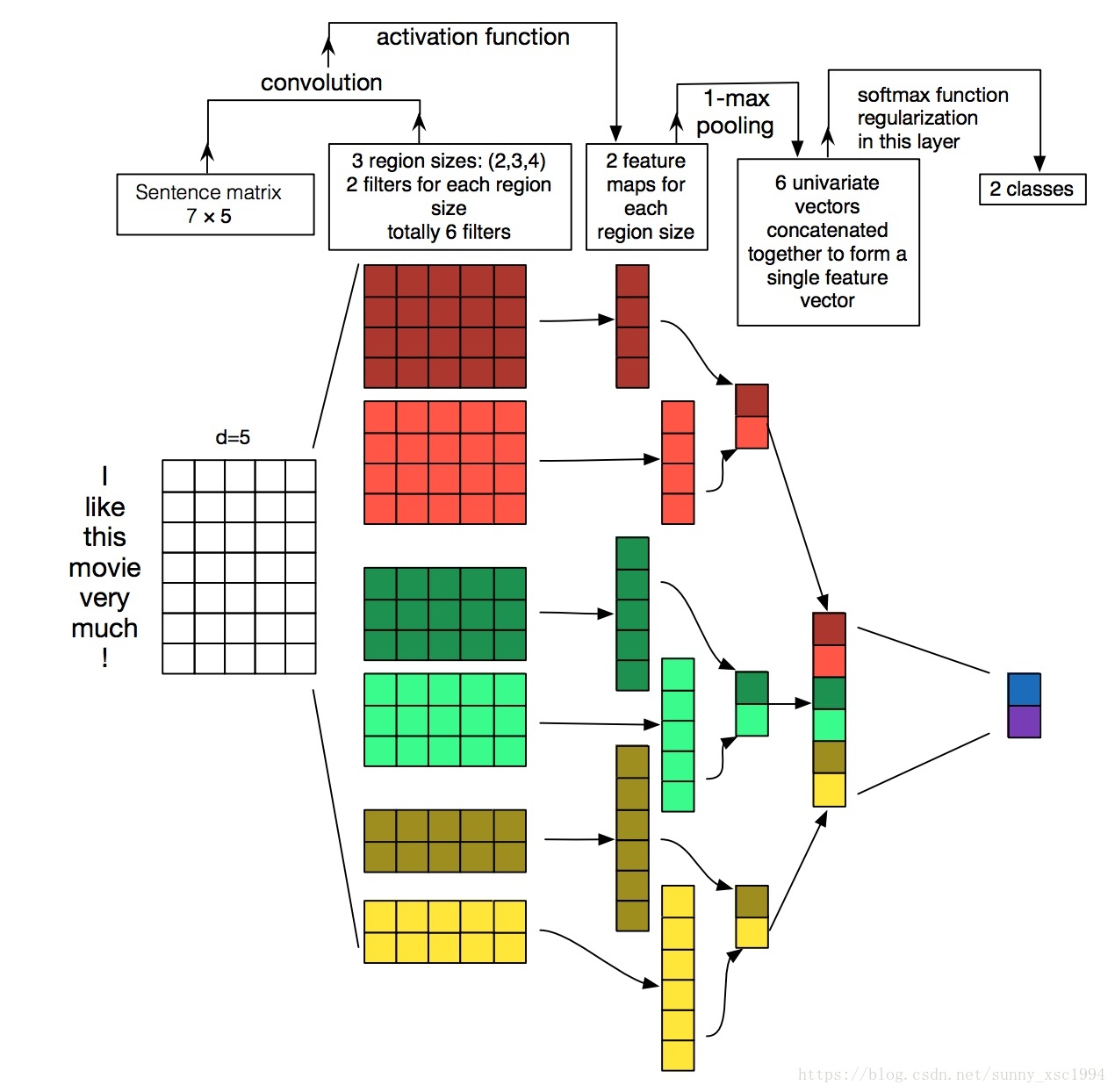
1次元畳み込みがどのように使用されるかを視覚化した図を添付します:。
画像の出典はこちら Kerasのテキスト分類の実装
図の入力単語ベクトルは5次元で、入力サイズは7*5、1次元の畳み込みカーネルはサイズが2、3、4でそれぞれ2つ、合計6つの特徴量を持つ。
k=4の場合、図中の赤の大きな行列を参照、コンボリューションカーネルサイズは4*5、ステップサイズは1。ここでは入力に対して上から下へスイープし、出力ベクトルのサイズは((7-4)/1+1)*1=4*1、最終的にコンボリューションカーネルサイズ4から1値でmax_poolingを経ることになります。最終的に6つの値が得られ、スプライシングされ、完全連結層を経て、2つのカテゴリの確率が出力される。
詳しく説明するためのコードを添付します。
ここで、embedding_size=256, feature_size=100, window_sizes=[3,4,5,6], max_text_len=35
class TextCNN(nn.Module):
def __init__(self, config):
super(TextCNN, self). __init__()
self.is_training = True
self.dropout_rate = config.dropout_rate
self.num_class = config.num_class
self.use_element = config.use_element
self.config = config
self.embedding = nn.Embedding(num_embeddings=config.vocab_size,
embedding_dim=config.embedding_size)
self.convs = nn.ModuleList([
nn.Sequential(nn.Conv1d(in_channels=config.embedding_size,
out_channels=config.feature_size,
kernel_size=h),
# nn.BatchNorm1d(num_features=config.feature_size),
nn.ReLU(),
nn.MaxPool1d(kernel_size=config.max_text_len-h+1))
for h in config.window_sizes
])
self.fc = nn.Linear(in_features=config.feature_size*len(config.window_sizes),
out_features=config.num_class)
if os.path.exists(config.embedding_path) and config.is_training and config.is_pretrain:
print("Loading pretrain embedding... ")
self.embedding.weight.data.copy_(torch.from_numpy(np.load(config.embedding_path)))
def forward(self, x):
embed_x = self.embedding(x)
# print('embed size 1',embed_x.size()) # 32*35*256
# batch_size x text_len x embedding_size -> batch_size x embedding_size x text_len
embed_x = embed_x.permute(0, 2, 1)
# print('embed size 2',embed_x.size()) # 32*256*35
out = [conv(embed_x) for conv in self.convs] #out[i]:batch_size x feature_size*1
#for o in out:
# print('o',o.size()) # 32*100*1
out = torch.cat(out, dim=1) # corresponding to the second dimension (row) spliced together, e.g. 5*2*1,5*3*1 spliced into 5*5*1
# print(out.size(1)) # 32*400*1
out = out.view(-1, out.size(1))
# print(out.size()) # 32*400
if not self.use_element:
out = F.dropout(input=out, p=self.dropout_rate)
out = self.fc(out)
return out
embed_xは32*35*256で始まり、batch_sizeは32。permute後は32*256*35になり、カスタムネットワークに入力後、各要素は32*100*1、合計4要素になる。dim=1次元でstitch後、32*400*1、view後、32*400、最後に400*num_classサイズの完全連結行列を経て、32*2になる。
関連
-
Pytorch-1-TX2にpytorchをインストール(自分でやったよ)
-
[Centernet recurrence] AttributeError:Can't pickle local object 'get_dataset.<locals>.Dataset
-
torch.stack()の公式解説、詳細、例題について
-
ピトーチテンソルインデックス
-
AttributeError: 'Graph' オブジェクトには 'node' という属性がありません。
-
顔キーポイント検出(データ読み込み、処理)
-
Silve pil.unidentifiedimageerror: cannot identify image file
-
RuntimeError: CUDAエラー: 不正なメモリアクセスが発生しました。
-
pytorchのマルチGPU利用 - #CUDA_VISIBLE_DEVICES use #torch.nn.DataParallel() #エラー解決
-
テンソルコード可視化-Pytorch
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] Pytorch ある割合で特定の値を持つランダムなint型テンソルを作成する方法は?例えば、25%が1で残りが0というような。
-
AttributeError NoneType オブジェクトに属性データがない。
-
PytorchがNotImplementedErrorを発生させるようです。
-
ピトーチリピートの使用方法
-
pytorchのSpeat()関数
-
Pytorch torch.Tensor.detach()メソッドの使い方と、指定したモジュールの重みを変更する方法
-
torch.stack()の使用
-
pytorchラーニングノート(XIV)。DataLoaderのソースコード読み込み
-
pytorch-DataLoader (データイテレータ)
-
EOFError: 入力がなくなった