顔キーポイント検出(データ読み込み、処理)
参考にしてください。
プログラミング初心者が最初に悩むのは、ネットワークに流すデータを読み込むコードをどう書けばいいのかわからないことかもしれません。この記事では、この部分のコードを書くための一般的な方法とプログラミングのアイデアに焦点を当てます。内容は基本的に、公式ドキュメントの翻訳と要約です。
データ
ダウンロード後、data/facesのパスに保存してください。
そこには69枚の顔画像があり、すべてのキーポイントを保存するためのゴールドスタンダードとしてcsvファイルがあり、顔画像1枚につき68個のキーポイントがあります。
csvファイルを開くと、全画像のファイル名と対応するキーポイントの座標が表形式で保存されていることがわかります。

一枚画像とタグの読み込み
本題に入る前に、この後のコードを理解するために、単一の画像とそれに対応するタグの読み取りと視覚化について見てみましょう。
#--coding:utf-8--
import os
import pandas as pd
from skimage import io
import matplotlib.pyplot as plt
# read csv file with pandas library
landmarks_frame = pd.read_csv('data/faces/face_landmarks.csv')
n = 65# line number
img_name = landmarks_frame.iloc[n, 0]
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
print('Image name: {}'.format(img_name))
print('Landmarks shape: {}'.format(landmarks.shape))
print('First 4 Landmarks: {}'.format(landmarks[:4]))
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.' , c='r')
plt.configure()
show_landmarks(io.imread(os.path.join('data/faces/', img_name)),
landmarks)
plt.show()
結果を実行します。


データセットの読み込みと処理
Pytorchのデータを読み込む考え方は、大きく分けて2つのステップに分かれます。
1. データセットを読み込んで処理し、Datasetのサブクラスを取得する。このメソッドはカスタムのサブクラスにすることもできますし、ImageFolderのような既存のクラスメソッドを直接呼び出すこともできます。
2. Dataloaderメソッドを呼び出して、データを一括で反復処理する
I. データセットクラス
torch.utils.data.Datasetはデータセットを表す抽象クラスです。 データセットを読み込む際には、このクラスのサブクラスを定義し、以下のメソッドをオーバーライドする必要があります。
__len__: データセットのサイズ、画像の枚数を返す
__getitem__:インデックス値に対応するサンプルを返します。そこからdataset[i]が対応するサンプルを取得します。 .
csvファイルは__init__関数で、画像は__getitem__関数で読み込むことにします。こうすることで、すべての画像を読み込んでメモリを消費する代わりに、必要なときにインデックスに対応する画像だけを読み込むことができます。
データセットのサンプルは、辞書 {'image':image,'landmarks':landmarks} として保存されます。
データ処理部分は、後述するtransformクラスでラップされます。
具体的なコードを見てみましょう。 データセットを定義してインスタンス化し、最初の4つのサンプルを可視化します。
#--coding:utf-8--
'''
An example of data reading. Feature point coordinate detection
'''
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.' , c='r')
class FaceLandmarksDataset(Dataset):
"""Face Landmarks dataset."""
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
transform (callable, optional): Optional transform to be applied on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:].values
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
# instantiate a class,
face_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
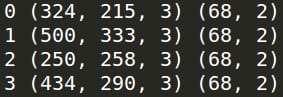
print(i, sample['image'].shape, sample['landmarks'].shape)
ax = plt.subplot(1, 4, i + 1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i == 3:
plt.show()
break
結果を実行します。

II. トランスフォーム
上のコードで、sample = self.transform(sample) という行がありますが、これはサンプルの前処理を行うものです。では、このtransformはどのように書けばいいのでしょうか?
通常、transform はクラスとして記述し、その __call__ メソッドを実装します。ここでは、前処理操作の3つの例として、スケール変換、ランダムクロップ、テンソル変換を紹介します。
完全なコードは次の通りである。
#--coding:utf-8--
'''
An example of data reading. Feature point coordinate detection
'''
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.' , c='r')
class FaceLandmarksDataset(Dataset):
"""Face Landmarks dataset."""
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
transform (callable, optional): Optional transform to be applied on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:].values
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
# Three data transformation class definitions
class Rescale(object):
"""Rescale the image in a sample to a given size.
Rescale the image and the coordinates of the control points to a given size.
Args:
output_size (tuple or int): Desired output size. If tuple, output is
If int, smaller of image edges is matched
to output_size keeping aspect ratio the same.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
if isinstance(self.output_size, int):
if h > w:
new_h, new_w = self.output_size * h / w, self.output_size
else:
new_h, new_w = self.output_size, self.output_size * w / h
else:
new_h, new_w = self.output_size
new_h, new_w = int(new_h), int(new_w)
img = transform.resize(image, (new_h, new_w))
# h and w are swapped for landmarks because for images,
# x and y axes are axis 1 and 0 respectively
landmarks = landmarks * [new_w / w, new_h / h]
return {'image': img, 'landmarks': landmarks}
class RandomCrop(object):
"""Crop randomly the image in a sample.
Randomly crop the image in a sample of specified size. The coordinates of the control points are panned accordingly
Args:
output_size (tuple or int): Desired output size. if int, square crop
is made.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
if isinstance(output_size, int):
self.output_size = (output_size, output_size)
else:
assert len(output_size) == 2
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
image = image[top: top + new_h,
left: left + new_w]
landmarks = landmarks - [left, top]
return {'image': image, 'landmarks': landmarks}
class ToTensor(object):
"""Convert ndarrays in sample to Tensors.
Variation of numpy array to tensor, plus dimensionality.
"""
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
image = image.transpose((2, 0, 1))
return {'image': torch.from_numpy(image),
'landmarks': torch.from_numpy(landmarks)}
#Examples of the application of the first two classes
scale = Rescale(256)
crop = RandomCrop(128)
composed = transforms.Compose([Rescale(256),
RandomCrop(224)])
# Apply each of the above transforms on sample.
fig = plt.figure()
face_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/')
sample = face_dataset[65]
for i, tsfrm in enumerate([scale, crop, composed]):
transformed_sample = tsfrm(sample)
ax = plt.subplot(1, 3, i + 1)
plt.tight_layout()
ax.set_title(type(tsfrm). __name__)
show_landmarks(**transformed_sample)
plt.show()
実行結果。

複数の前処理を統合するtransforms.Compose関数が一般的です。
III. データローダー
データセットを読み込んで前処理をしたら、次はデータセットに対してどのように反復処理を行うかです。簡単に書くと、for i in range(len(dataset)) を使って反復処理をループさせるという方法です。コード例は以下の通りです。
transformed_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
transformed_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i, sample['image'].size(), sample['landmarks'].size())
if i == 3:
break root_dir='data/faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i, sample['image'].size(), sample['landmarks'].size())
if i == 3:
break
しかし、この書き方では、バッチ処理、読み込み順の乱れ、マルチスレッドでの読み込みなど、いくつかの問題を無視している。torch.utils.data.DataLoaderはこれらの機能を提供します。
DataLoaderの呼び出し例を見てみましょう。上の3つのTransformsクラスの定義を見てみましょう。
transformed_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
dataloader = DataLoader(transformed_dataset, batch_size=4,
shuffle=True, num_workers=4)
# Helper function to show a batch
def show_landmarks_batch(sample_batched):
"""Show image with landmarks for a batch of samples."""
images_batch, landmarks_batch = \
sample_batched['image'], sample_batched['landmarks']
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose((1, 2, 0)))
for i in range(batch_size):
plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size,
landmarks_batch[i, :, 1].numpy(),
s=10, marker='.' , c='r')
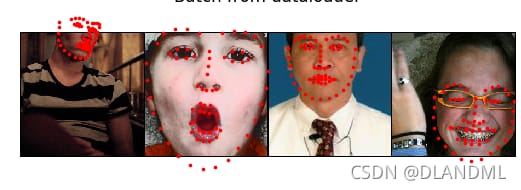
plt.title('Batch from dataloader')
for i_batch, sample_batched in enumerate(dataloader):
print(i_batch, sample_batched['image'].size(),
sample_batched['landmarks'].size())
# observe 4th batch and stop.
if i_batch == 3:
plt.configure()
show_landmarks_batch(sample_batched)
plt.axis('off')
plt.show()
break
結果を実行します。
IV. もうひとつのデータセット読み込み方法 イメージフォルダ
カテゴリー分けの作業をするとき、異なるカテゴリーの画像を異なるフォルダーに入れ、フォルダー名をそのカテゴリーのラベルとする、このようなことが可能です。
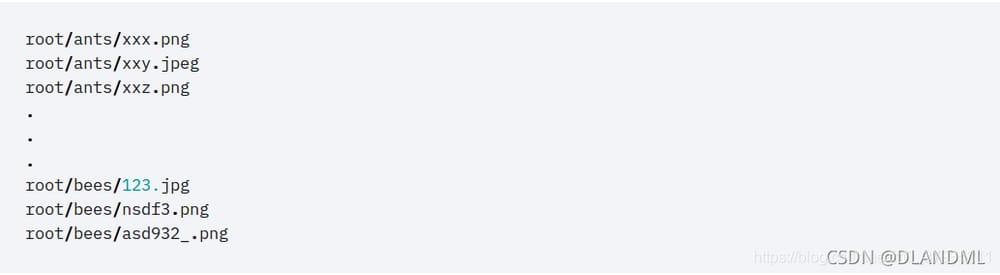
この時点で、データセットクラスをカスタマイズすることなく、ImageFolderで直接画像やタグを読み込むことができます。コード例は以下の通りです。
import torch
from torchvision import transforms, datasets
data_transform = transforms.Compose([
RandomSizedCrop(224),
RandomHorizontalFlip(),
ToTensor(),
Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
hymenoptera_dataset = datasets.ImageFolder(root='hymenoptera_data/train',
transform=data_transform)
dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset,
batch_size=4, shuffle=True,
num_workers=4)
参考
https://blog.csdn.net/m0_37935211/article/details/90246643
関連
-
Pytorch-1-TX2にpytorchをインストール(自分でやったよ)
-
AttributeError NoneType オブジェクトに属性データがない。
-
pytorchのSpeat()関数
-
Pytorch torch.Tensor.detach()メソッドの使い方と、指定したモジュールの重みを変更する方法
-
torch.stack()の使用
-
torch.catとtorch.stackの違いについて
-
pytorchラーニングノート(XIV)。DataLoaderのソースコード読み込み
-
pytorch-DataLoader (データイテレータ)
-
ピトーチテンソルインデックス
-
PyTorchのF.cross_entropy()関数
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】pytorchでテンソルを平らにする方法は?
-
[解決済み] Pytorch ある割合で特定の値を持つランダムなint型テンソルを作成する方法は?例えば、25%が1で残りが0というような。
-
[Centernet recurrence] AttributeError:Can't pickle local object 'get_dataset.<locals>.Dataset
-
PytorchがNotImplementedErrorを発生させるようです。
-
ピトーチリピートの使用方法
-
pytorch学習におけるtorch.squeeze()とtorch.unsqueeze()の使用法
-
torch.stack()の公式解説、詳細、例題について
-
AttributeError: 'Graph' オブジェクトには 'node' という属性がありません。