pytorchのマルチGPU利用 - #CUDA_VISIBLE_DEVICES use #torch.nn.DataParallel() #エラー解決
記事目次
主にシングルホストマルチカード(シングルホストマルチGPUのトレーニング)について
マルチカードトレーニングを使用する方法はたくさんあります。もちろん、私たちのデバイスに複数のGPUがあることが前提ですが:Ubuntuプラットフォームの現在のGPUの数を見るにはnvidia-smiコマンドを使用し、各GPUには番号が振られます。[0,1,2,3]
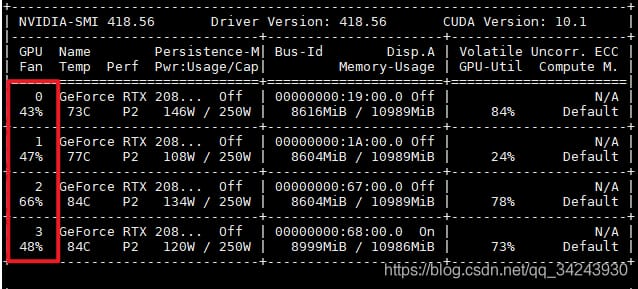
0. グラフィックカード番号(マスターカードは何か)
デフォルトでは、0と表示されているグラフィックカードがマスターカードです。例えば、ホストに4枚のグラフィックカードがある場合、デフォルトでは各グラフィックカードに[0,1,2,3]と表示されています。
<マーク
他のグラフィックカードをマスターカードに設定するにはどうすればよいですか?
By
os.environ["CUDA_VISIBLE_DEVICES"]
使用するグラフィックカードを指定する、など。
os.environ["CUDA_VISIBLE_DEVICES"] = "3,2,0,1"
model = torch.nn.DataParallel(model, device_ids=[0,2,3]).cuda()
この時点で3番のカードがマスターカードとなり、torch.nn.DataParallelで演算用グラフィックカードを指定すると、グラフィックカードは以下のように対応します。
Actual graphics card number -----> Computing graphics card number
3 -----> 0 (primary card)
2 -----> 1
0 -----> 2
1 -----> 3
1. 存在するすべてのグラフィックカードを使用する
複数のカードがある場合、torch.nn.DataParallel を使って直接モデルをラップする最も簡単な方法は、以下の通りです。
net = torch.nn.DataParallel(model)
この時点では、既存のすべてのグラフィックカードがデフォルトで使用されます
2. グラフィックカードを使用する番号を指定する
グラフィックカードがたくさんある(例えば、4枚のグラフィックカードがある)が、グラフィックカード0、1、2だけを使いたい場合。
net = torch.nn.DataParallel(model, device_ids=[0, 1, 2])
あるいは
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(map(str, [0,1,2])) # Generally set at the beginning of the program
# Equivalent to os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2'
net = torch.nn.DataParallel(model)
CUDA_VISIBLE_DEVICES
torch.cuda.set_device(1)
Python環境プログラムで検出可能な現在のグラフィックカードを示します。
カードを1枚だけ指定する必要がある場合は
torch.cuda.set_device(1)
print(torch.cuda.device_count()) # number of available GPUs
gpuの使用数を指定する
(この方法は推奨しません)
torch.cuda.set_device(1)
(私のマシンは4枚なので、印刷結果は 4 で、利用可能な GPU の数を示しています。
torch.nn.DataParallel(model, device_ids=[1, 2])
を指定した場合、見えるグラフィックカードは変わりません)
また、後者は
set_device(1)
と指定することができます。
を含む必要があります。
CUDA_VISIBLE_DEVICES
を指定すると、device:0 を占有する gpu メモリが残ってしまうという欠点があります。
3. os.environ["CUDA_VISIBLE_DEVICES"の詳細
3.1. [CUDA_VISIBLE_DEVICES"] 使用方法
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(map(str, [0,1,2])) # usually set at the beginning of the program
# Equivalent to os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2'
os.environ["CUDA_VISIBLE_DEVICES"] = '1,2'
Python環境プログラムで検出可能な現在のグラフィックカードを示します。
os.environ["CUDA_VISIBLE_DEVICES"] = '1,2'
torch.nn.DataParallel(model, device_ids=[0,1])
os.environ['CUDA_VISIBLE_DEVICES']='1'
使用するデバイスを指定する場合
このように
は、pytorch sense のデバイス番号を変更します。
この場合、pytorch-awareのナンバリングはdevice:0から始まります。上記のように、1番のグラフィックカードをdevice:0に、1番のグラフィックカードをdevice:1に変更し、以下のように使用する必要があります。
import torch
print(torch.cuda.is_available())
3.2. CUDA_VISIBLE_DEVICES"] が無効である場合の対処法
うまくいかないのは、コードの行が間違った場所に置かれているためです。
を必ず配置してください。
os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2'
print(torch.cuda.device_count())
は、GPU にアクセスするすべてのコードの前に置きます。
torch.cuda.device_count()
4. torch.cudaの主要な関数
4.1. GPU が使用可能かどうかを判断する torch.cuda.is_available()
os.environ["CUDA_VISIBLE_DEVICES"] = '1,2'
print(torch.cuda.current_device())
利用できる意味 真
4.2. torch.cuda.device_count() で利用可能な GPU の数を確認する。
os.environ["CUDA_VISIBLE_DEVICES"] = '1,2'
という結果になるはずです。3
4.3. torch.cuda.current_device() で現在使用中の GPU シリアルナンバーを確認する。
torch.cuda.get_device_capability(device)
torch.cuda.get_device_name(device)
という結果になるはずです。0
これは、上で述べたことを証明するものです。
torch.cuda.empty_cache()
を使って、使用するデバイスを指定します。
は pytorch が感じるデバイス番号を変更します。
pytorchを意識した番号付けは、これまで通りdevice:0から始まります。
4.4 その他いくつかの機能
指定したGPUの容量、名称の表示
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
プログラムによって占有されているGPUリソースをクリアする
AssertionError: Invalid device id
GPUのランダムシードを設定する
os.environ["CUDA_VISIBLE_DEVICES"] = '0,1' # usually set at the beginning of the program
net = torch.nn.DataParallel(model,device_ids=[1, 2])
CUDA_VISIBLE_DEVICES
5. エラーを報告する AssertionError: 無効なデバイスID
gpu指定番号のモデルでマルチgpuトレーニングを行っています。
指定された数のGpusを持つ必要があります
と表示されます。
torch.nn.DataParallel(model, device_ids=[1, 2])
エラー
エラー報告例 1.
os.environ["CUDA_VISIBLE_DEVICES"] = '1,2' # generally set at the beginning of the program
net = torch.nn.DataParallel(model,device_ids=[1, 2])
os.environ["CUDA_VISIBLE_DEVICES"] = '1,2'
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(map(str, [1,2])) # usually set at the beginning of the program
net = torch.nn.DataParallel(model,device_ids=[0, 1])
Python 環境プログラムによって検出可能な現在のグラフィックカードを示します。
そして
torch.nn.DataParallel
gpu番号を指定すると、AssertionErrorが発生します。無効なデバイスIDエラー
理由 No.2のグラフィックカードが表示されるように設定されていません。
エラー報告例 2.
os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2,3' # Here the master card is the machine 0 card
model = torch.nn.DataParallel(model, device_ids=[1,2,3]).cuda()
os.environ["CUDA_VISIBLE_DEVICES"] = '1,2'
使用するデバイスを指定する場合
このように
は、pytorch sense のデバイス番号を変更します。
Pytorch を意識した番号付けは、これまで通り device:0 から始まります。
プログラムでは、このように変更する必要があります。
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(map(str, [1,2])) # usually set at the beginning of the program
net = torch.nn.DataParallel(model,device_ids=[0, 1])
6. エラーを報告する RuntimeError: モジュールはデバイス cuda:1 (device_ids[0]) にそのパラメータとバッファを持っていなければなりませんが、見つかりました。
PyTorch フレームワーク、使用
torch.nn.DataParallel
この問題は、マルチカード並列計算で発生する可能性があり
この問題は、マルチカード計算時のマスターカードの設定に起因しています
. マルチカード並列計算時に
は、使用するグラフィックスカードにプライマリカードを含める必要があります。
でないと問題が発生します。
以下のコードでは、プライマリカードが計算に関与していないため、このエラーが発生します。
os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2,3' # Here the master card is the machine 0 card
model = torch.nn.DataParallel(model, device_ids=[1,2,3]).cuda()
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ハートビート・エフェクトのためのHTML+CSS
-
HTML ホテル フォームによるフィルタリング
-
HTML+cssのボックスモデル例(円、半円など)「border-radius」使いやすい
-
HTMLテーブルのテーブル分割とマージ(colspan, rowspan)
-
ランダム・ネームドロッパーを実装するためのhtmlサンプルコード
-
Html階層型ボックスシャドウ効果サンプルコード
-
QQの一時的なダイアログボックスをポップアップし、友人を追加せずにオンラインで話す効果を達成する方法
-
sublime / vscodeショートカットHTMLコード生成の実装
-
HTMLページを縮小した後にスクロールバーを表示するサンプルコード
-
html のリストボックス、テキストフィールド、ファイルフィールドのコード例