Jupyter notebookをベースとしたSparkクラスタ開発環境構築の詳細プロセス
I. コンセプトの紹介
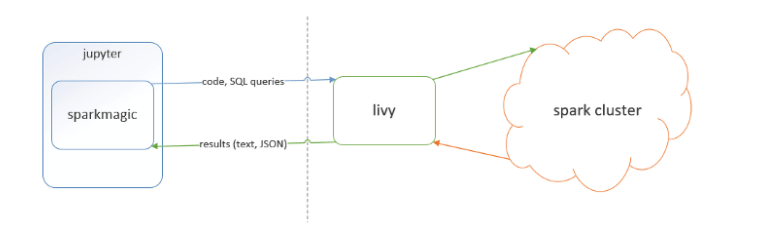
1. Sparkmagic:LivyサーバのSpark RESTを介して、リモートのSparkクラスタとJupyter Notebookで作業するためのツールである。Sparkmagicプロジェクトには、複数の言語でSparkコードを対話的に実行するためのフレームワークのセットと、Jupyter NotebookからSpark環境で実行するためのコード変換に使用できるカーネルが多数含まれています。
2. Livy SparkベースのオープンソースRESTサービスで、コードスニペットやシリアライズしたバイナリコードをREST経由でSparkクラスタに送信して実行させるもの。Scala、Python、RのコードスニペットをリモートSparkクラスタに送信して実行する、Java、Scala、Pythonで書かれたSparkジョブをリモートSparkクラスタに送信して実行する、クラスタで実行するバッチアプリケーションを送信するという基本機能を提供する。
II. 基本フレームワーク
を下図に示します。
III. 準備すること
自分で構築するか、MRSなどのHuaweiクラウド上のサービスを直接利用できるSaprkクラスタを用意し、クラスタにSparkクライアントをインストールします。Jupyter NotebookとLivyを同一ノード(Dockerコンテナでも仮想マシンでも可)にインストールし、インストールパッケージのパスを https://livy.incubator.apache.org/download/
IV. リヴィの設定と起動
livy.confを参照するように修正します。 https://enterprise-docs.anaconda.com/en/latest/admin/advanced/config-livy-server.html
以下の設定を追加します。
<provider
android:name="androidx.core.content.FileProvider"
android:authorities="org.signin.fileprovider"
android:exported="false"
android:grantUriPermissions="true">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/provider_paths" />
</provider>
livy-env.shを修正し、SPARK_HOME、HADOOP_CONF_DIR、その他の環境変数を設定する。
<provider
android:name="androidx.core.content.FileProvider"
android:authorities="org.test.fileprovider"
android:exported="false"
android:grantUriPermissions="true">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/provider_paths" />
</provider>
リヴィを開始します。
. /bin/livy-server start
V. Jupyter Notebookとsparkmagicのインストール
Jupyter Notebookはオープンソースで広く利用されているプロジェクトなので、ここではインストール方法については触れないことにします
sparkmagicはJupyter Notebookのカーネルのようなものと理解すればよく、pip install sparkmagic.をインストールするだけです。インストールが終わると、$HOME/.sarkmagic/config.jsonというファイルが生成されますが、これはsarkmagicの重要な設定ファイルであり、sparkの設定と互換性のあるものです。キーコンフィギュレーションは図のようになります。

ここで、urlはhttpとhttpsの両方のプロトコルをサポートするLivyサービスのipとポートです。
VI. スパークマジックカーネルを追加する
PYTHON3_KERNEL_DIR="$(jupyter kernelspec list | grep -w "python3" | awk '{print $2}')"
KERNELS_FOLDER="$(dirname "${PYTHON3_KERNEL_DIR}")"
SITE_PACKAGES="$(pip show sparkmagic|grep -w "場所" | awk '{print $2}')"
cp -r ${SITE_PACKAGES}/sparkmagic/kernels/pysparkkernel ${KERNELS_FOLDER} です。
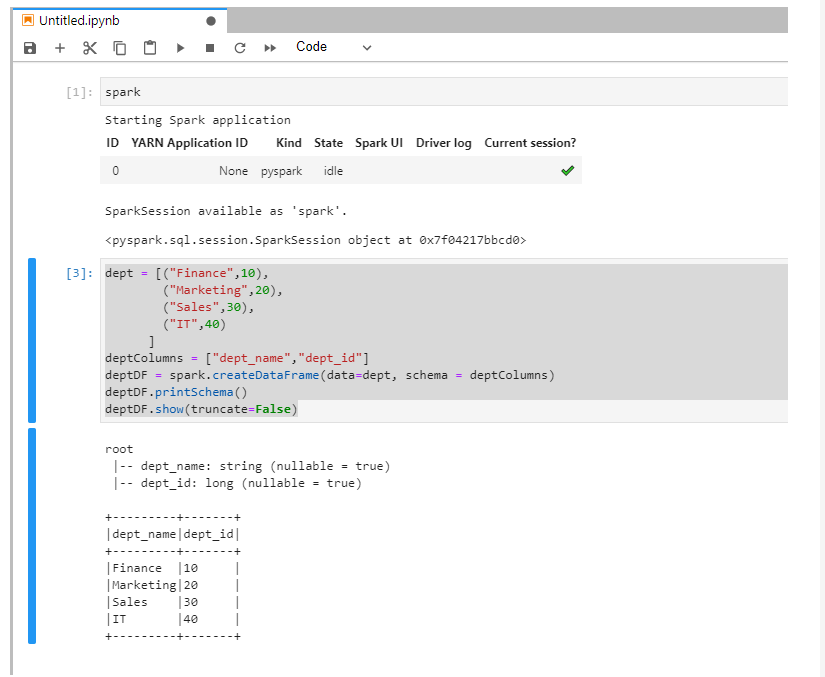
VII. Jupyter Notebookでsparkのコードを実行し、検証する。
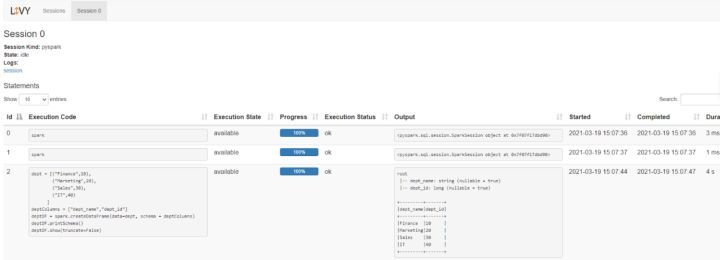
viii. Livyにアクセスし、現在のセッションログを表示します。
今回はJupyter notebookをベースにしたSparkクラスタ開発環境構築の詳細な流れについて紹介しましたが、Jupyter notebookをベースにしたSparkクラスタ開発環境構築の詳細については、スクリプトハウスの過去記事を検索するか、以下の関連記事を引き続き閲覧してください。
関連
-
K8sandra入門チュートリアル - Linux上のKubernetesにK8sandraをデプロイする
-
Burpsuiteの使い方とスタートアップ 詳細チュートリアル
-
Burp Suite Proのインストールと設定のチュートリアルの詳細
-
BurpSuiteのインストールと設定の詳細
-
UltraEdit エディタ無料起動方法
-
HDFSのNamenode高可用性メカニズムを見てみよう
-
VSCodeリモートサーバ接続エラー:Could not establish connection to VSCode
-
Visual Studioを使ったファイル差分比較の問題点まとめ
-
[解決済み】git error: failed to push some refs to remote
-
自律走行技術のV2X技術の紹介
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ゲートウェイ・ゲートウェイ原理の徹底分析
-
Git.gitignore開発必携アドバイス集
-
Fiddlerを用いたソフトウェアテストにより、脆弱なネットワークテストを実現
-
roolupを使ったライブラリの構築(ステップバイステップの実装)
-
[解決済み】アーキテクチャx86_64の未定義シンボル。コンパイル時の問題
-
[解決済み】ターミナルで"-"破線のファイル名を開くには?
-
[解決済み】スタイルシートとして解釈されるリソースがMIMEタイプtext/htmlで転送される(Webサーバーとは関係ないようです)。
-
[解決済み】リソースの読み込みに失敗しました:サーバーは404(Not Found)のステータスで応答しました。)
-
C1ミッション01:ゲームアーカイブスの改造方法
-
VScodeでfortranを使用するための設定