YOLO v3を一挙紹介
論文アドレス:https://pjreddie.com/media/files/papers/YOLOv3.pdf
学位論文 YOLOv3:インクリメンタルインプルーブメント
ターゲット検出アルゴリズムのYOLOファミリーは、ターゲット検出の歴史における大傑作と言っても過言ではありません。次に、v1、v2をベースに形成されたYOLO v3アルゴリズムの内容を詳しく説明しますので、まず、以下のことを思い出してください。 YOLO v1 一括掲載 は、その YOLO v2 を一挙に公開 , ターゲット検出マップ , YOLO v4一挙掲載 , YOLO v5を一挙公開 .
ネットワーク構成
から
こちら
は、YOLOV3の構造をうまくまとめた図を盗み、YOLOをより直感的に理解できるようにしました。
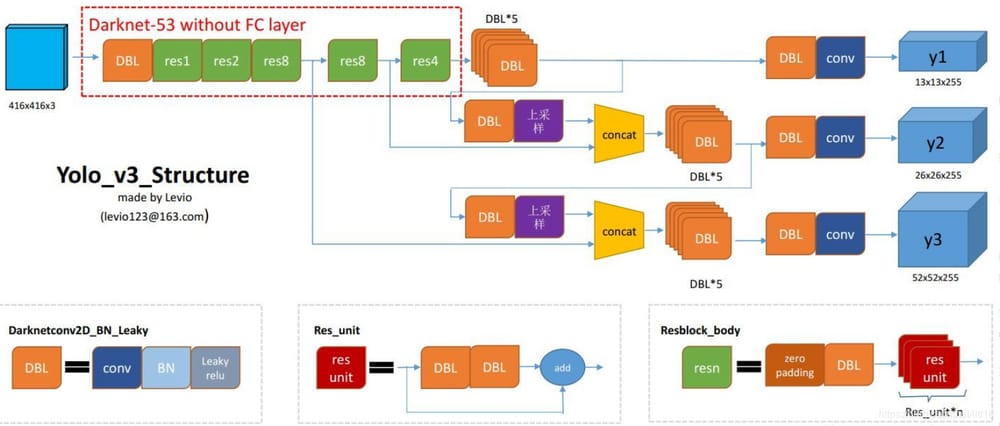
デービーエル
コード Darknetconv2d_BN_Leaky は、yolo_v3 の基本コンポーネントです。コンボリューション+BN+Leaky reluです。
レスン
nは数字を表し、res1, res2, ...があります。,res8 といった具合に、このres_blockにいくつのres_unitsがあるかを示しています。
レスネットがわからない
お願い
ここをクリック
コンカット
: テンソル連結。ダークネットの中間層と、それ以降の層の一つをアップサンプリングして連結する。concat操作は、残差層に対するadd操作とは異なる。concat操作はテンソルの次元を拡張するのに対し、add操作はテンソルの次元を変えずに直接追加するだけである。
細かい部分やわかりにくい部分は、後で一緒にネットワークを解析してみましょう
バックボーン:ダークネット-53
より良い分類結果を得るために、著者らはdarknet-53を自ら設計し、学習させた。darknet-53はResNet-152やResNet-101と比較すると確かに非常に強い。darknet-53は同程度の分類精度を持っているだけでなく、計算速度もResNet-152やResNet-101よりずっと速いのである。また、ResNet-152やResNet-101よりもはるかに強力で、層数も少ない。

yolo_v3は、以前のdarknet-53の52層(完全接続層なし)を使用しています。完全畳み込みネットワークであるyolo_v3は、残留ホッピング接続を多用し、プーリングによる勾配の悪影響を減らすために、著者らは直接POOLingを捨て、convのストライドを使ってダウンサンプリングを実装しています。このネットワーク構造では、ダウンサンプリングにステップサイズ2の畳み込みが用いられている。
小ターゲット検出のためのアルゴリズムの精度を高めるために、YOLO v3ではFPNのようなアップサンプルとフュージョンのアプローチ(最終的に3スケールをフュージョンし、残りの2スケールは26×26と52×52のサイズ)を用いて、複数スケールの特徴マップ上での検出を行う。
また、著者らは3つの予測分岐において完全畳み込み構造を用いており、COCOデータセットの80クラスに対して、最後の畳み込み層の畳み込みカーネル数は255である。3*(80+4+1)=255, 3はグリッドセルが3つのバウンディングボックスを含むこと、4はボックスの4つの座標情報、1はオブジェクトネススコアを意味する ...
出力
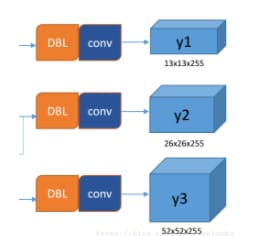
いわゆるマルチスケールとは、この3つの予測経路から、y1、y2、y3はいずれも深さ255、エッジ長の法則は13:26:52です。yolo v3は、1グリッドセルあたり3ボックスを予測する設定なので、各ボックスには(x、y、w、h、信頼度)の基本パラメータ5つと、それに確率の80分類が必要です。つまり、3×(5+80)=255となります。
y1,y2,y3がどのように生まれたか見てみましょう。
著者らは、ネットワークにおいて、それぞれ32倍ダウンサンプリング、16倍ダウンサンプリング、8倍ダウンサンプリングの3つのテストを行い、マルチスケール特徴マップ上での検出がSSDにある程度近くなるようにした。ネットワークでアップサンプル(アップサンプリング)を使用する理由:ネットワークが深いほど、特徴の表現が良い、例えば、16倍のダウンサンプリング検出では、直接検出するために第4ダウンサンプリングの特徴を使用する場合、浅い特徴を使用するので、効果は一般的に良くありません。32回ダウンサンプリングした後の特徴を使いたいが、深い特徴のサイズが小さすぎるので、yolo_v3はステップサイズ2のアップサンプル(upsampling)を使って、32回ダウンサンプリングで得られる特徴マップのサイズを2倍にし、16回ダウンサンプリング後の次元にもなるようにします。同様に8倍サンプリングも、16倍ダウンサンプリングした特徴を2段階でアップサンプリングすることで、より深い特徴を検出に利用できるようになる。
著者らは、融合する特徴層と同じ次元にアップサンプリングすることで深い特徴を抽出している(チャンネルは異なる)。下図のように、層85は13×13×256の特徴量をアップサンプリングして26×26×256とし、層61からの特徴量とつなぎ合わせて26×26×768としている。チャンネル255を得るために、3×3、1×1の一連の畳み込み演算を行い、非線形性を改善し、汎化性能を高め、ネットワーク精度を向上させ、パラメータを減らしてリアルタイム性を向上させている。52×52×255の特徴量も同様の処理である。
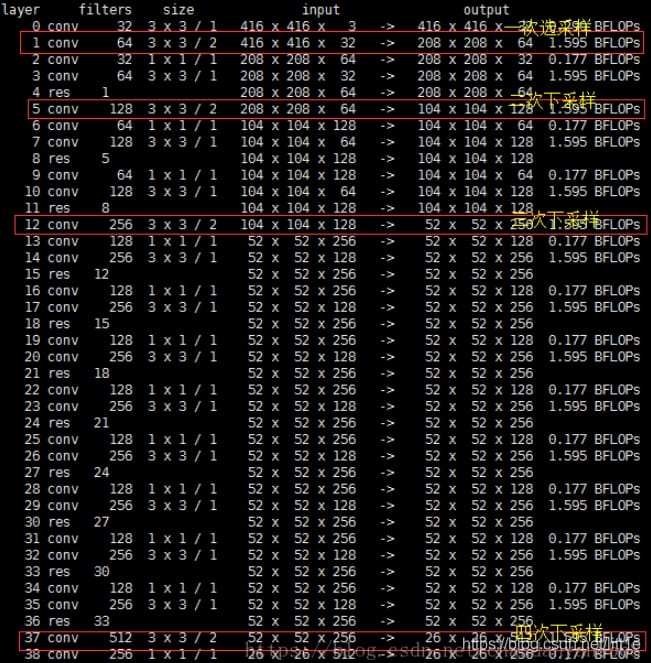
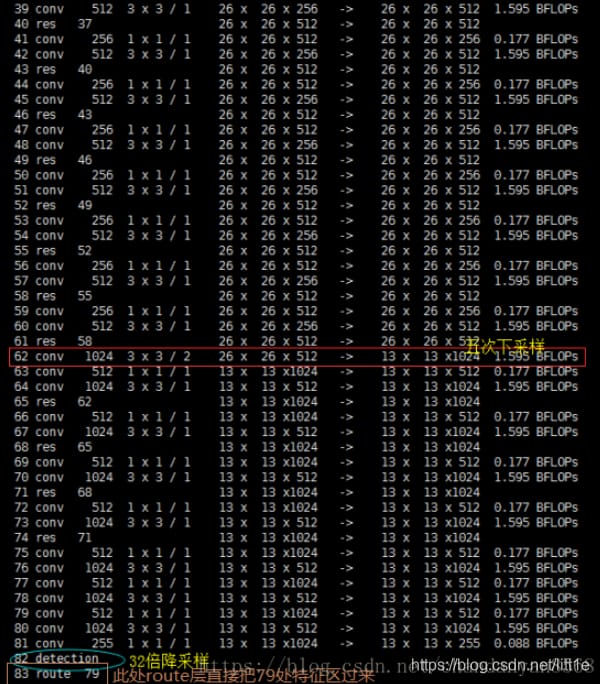
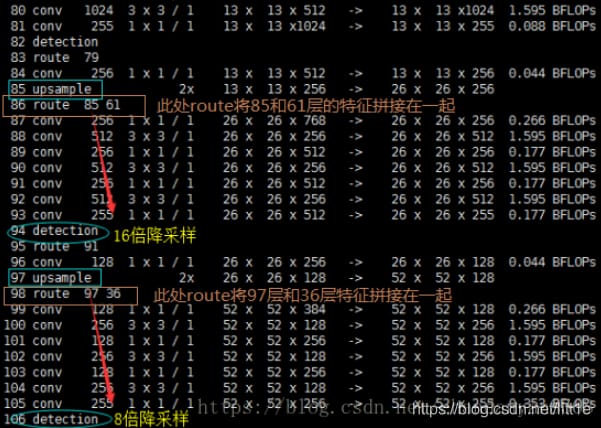
図から、y1,y2,y3の原点を確認することができます。
バウンディングボックス
YOLO v3のバウンディングボックスは、YOLOV2によって再び改良されています。yolo_v2、yolo_v3ともに、画像中のオブジェクトに対してk-meansクラスタリングが使われています。特徴マップの各セルは3つのバウンディングボックスを予測し、各バウンディングボックスは3つのことを予測する。(1) 各ボックスの位置(4値、中心座標txとty、ボックスの高さbhと幅bw)、 (2) オブジェクト性予測、および (3) N個のカテゴリーである。) N個のカテゴリー、cocoデータセットには80個のカテゴリー、vocには20個のカテゴリーがある。
32倍ダウンサンプリングは最も大きな受容野を持ち、大きな物体の検出に適しているため、入力が416×416の場合、各セルの3つのアンカーボックスは(116 ,90); (156 ,198); (373 ,326) となります。16倍は平均的な大きさの物体に適しており、アンカーボックスは (30,61 ); (62,45); (59,119) となる。8倍は知覚領域が最も小さく、小さな対象を検出するのに適しているので、アンカーボックスは (10,13); (16,30); (33,23) となる。つまり、入力が416×416のとき、実際には合計(52×52+26×26+13×13)×3=10647個のプロポーザルボックスが存在することになる。

9個のアプリオリボックスの大きさを実感してください。下図の青いボックスが、クラスタリングによって得られたアプリオリボックスです。黄色いボックスはグランドトゥルース、赤いボックスはオブジェクトのセントロイドが配置されたグリッドです。

ここで、バウンディングボックスとアンカーボックスの違いに注目してください。
バウンディングボックスは、ボックスの位置(中心座標と幅)、信頼度、Nカテゴリを出力します。
アンカーボックスは単なるスケール、すなわち幅と高さだけである。
LOSS機能
YOLOv3の重要な変更点の1つ:クラスのソフトマックスを廃止したことです。
YOLO v3では、画像から検出された物体のマルチラベル分類を行うことができるようになりました。
ロジスティック回帰を用いて、アンカーで囲まれた部分に物体性スコア、つまり、この場所の一部がターゲットである可能性を適用します。このステップを予測前に行うことで、不要なアンカーを削除し、計算量を減らすことができる。
テンプレートフレームが設定した閾値を超えていても最適でない場合は、やはり予測しない。
高速なR-CNNとは異なり、yolo_v3は最適な1つの事前情報のみを操作し、9つのアンカー事前情報から最も高いobjectnessスコアを持つものを見つけるためにロジスティック回帰を使用します。ロジスティック回帰は、事前情報とobjectnessスコアの対応関係を曲線で線形モデル化したものです。
lxy, lwh, lcls, lconf = ft([0]), ft([0]), ft([0]), ft([0])
txy, twh, tcls, indices = build_targets(model, targets)# find the most suitable anchor box in 13 26 52 dimensions greater than the iou threshold as targets
#txy[dimension(0:2),(x,y)] twh[dimension(0:2),(w,h)] indices=[0,anchor index, gi, gj]
# Define criteria
MSE = nn.MSELoss()
CE = nn.CrossEntropyLoss()
BCE = nn.BCEWithLogitsLoss()
# Compute losses
h = model.hyp # hyperparameters
bs = p[0].shape[0] # batch size
k = h['k'] * bs # loss gain
for i, pi0 in enumerate(p): # layer i predictions, i
b, a, gj, gi = indices[i] # image, anchor, gridx, gridy
tconf = torch.zeros_like(pi0[... , 0]) # conf
# Compute losses
if len(b): # number of targets
pi = pi0[b, a, gj, gi] # predictions closest to anchors find the data corresponding to targets in p lxy
tconf[b, a, gj, gi] = 1 # conf
# pi[... , 2:4] = torch.sigmoid(pi[... , 2:4]) # wh power loss (uncomment)
lxy += (k * h['xy']) * MSE(torch.sigmoid(pi[... , 0:2]),txy[i]) # xy loss
lwh += (k * h['wh']) * MSE(pi[... , 2:4], twh[i]) # wh yolo loss
lcls += (k * h['cls']) * CE(pi[... , 5:], tcls[i]) # class_conf loss
# pos_weight = ft([gp[i] / min(gp) * 4.])
# BCE = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
lconf += (k * h['conf']) * BCE(pi0[... , 4], tconf) # obj_conf loss
loss = lxy + lwh + lconf + lcls
上記は pytorch フレームワークで記述された yolo v3 の loss_function コードのスニペットです。定数係数は無視して、以下の点を強調したいと思います。
- まず、yolov3はターゲットを構築するために、グランドトゥルースに対して、まずそのセントロイドがどのセルに該当するかを決定し、このセルの各アンカーとグランドトゥルースのIOU値を計算し、座標を考慮せず、形状のみを考慮してIOU値を計算します(アンカーには座標xyがないため、アンカーとグランドトゥルースの中心点を同じ位置(原点)に移動し、対応するIOU値を計算します)。この座標を13×13または26×26または52×52に対応する地図に用いて、それぞれ9つのアンカーのIOUを計算し、条件を満たすものを見つけ、そのインデックスと位置を記録することができる。記録されたインデックス位置から、予測されるアンカーボックスを探す。
- xywh は損失を計算するための平均二乗差で、予測 xy はラベル xy との差を見つけるためにシグモイドになります。ラベル xy はグリッドセルの中心点座標で、その値は 0-1 の間なので、予測 xy はシグモイドになるはずです。
- 分類に用いるマルチカテゴリー・クロスエントロピーと、信頼度に用いるバイナリー・クロスエントロピーである。クラス、xywh の損失計算には正のサンプルのみが関与し、負のサンプルは信頼度の損失のみに関与する。
参考記事
https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b
https://blog.csdn.net/yanzi6969/article/details/80505421
https://blog.csdn.net/chandanyan8568/article/details/81089083
https://blog.csdn.net/leviopku/article/details/82660381
https://blog.csdn.net/u014380165/article/details/80202337
関連
-
などの警告を出しながらFaster-RCNNを実行します。RuntimeWarning: invalid value encountered in greater_equal などの警告が表示されます。
-
ResNetの紹介
-
xx.exe の 0x00007FF7A7B64FB3 でスローされた例外: 0xC0000005: 場所 0x00 を読み取るアクセス違反
-
深層学習トラッキングアルゴリズム概要
-
tensorflowをインポートしています。ImportError: libcublas.so.9.0: cannot open shared object file: No such file or director
-
トーチの取り付けと使用
-
カーネルが死んだようです」の解決法。自動的に再起動します" の解決方法
-
caffeのインストールで「error : too few arguments in function call」エラーが発生する。
-
Tensorflow-gpu2.0.0インストールとtensorflow-gpuインストール成功のテストプログラム。
-
AttributeError: 'tuple' オブジェクトには 'log_softmax' という属性がありません。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ValueError:入力配列を形状 (450,600,3) から形状 (64,64,3) にブロードキャストできませんでした。
-
[Tensorflow-Error】CUDA_ERROR_OUT_OF_MEMORY:メモリが不足しています。
-
Tensorflow 踩坑:ImportError: DLL のロードに失敗しました。指定されたモジュールが見つかりません。 TensorFlowのネイティブランタイムのロードに失敗しました。
-
参照用シークレットを呼び出す:BN層詳細解説
-
PackagesNotFoundError: 次のパッケージは、現在のチャンネルから利用できません ソリューション
-
Tensorflowのメタフィジカルエラーです。終了コード -1073741819 (0xC0000005)
-
pytorchはエラーを報告します。ValueError: num_samples は正の整数値であるべきですが、num_samples=0 となりました。
-
ロジスティック回帰は2分法モデル
-
TensorFlow実行時エラー、AttributeError: モジュール 'pandas' には 'computation' という属性がない。
-
AttributeError: モジュール 'pandas' には 'core' という属性がありません。