解決済み:原因:java.io.ioexception: error=13, 権限が拒否されました。
実験環境
centos 7; cdh5.15; anaconda3
問題の説明
作者は
Cloudera Manager
を使用して、クラスタ内のマシンにコンポーネントを割り当てています。
Spark2
コンポーネントを使用します。
Python環境、およびこれらのコンポーネントをインストールするのは
Pyspark
対話型インターフェースでファイルを読み込むと、次のようなエラーが発生します。
Caused by: java.io.IOException: Cannot run program "/root/anaconda3/bin/python": error=13, Permission denied
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1048)
at org.apache.spark.api.python.PythonWorkerFactory.startDaemon(PythonWorkerFactory.scala:197)
at org.apache.spark.api.python.PythonWorkerFactory.createThroughDaemon(PythonWorkerFactory.scala:122)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:95)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:117)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:108)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:403)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:409)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
... 1 more
Caused by: java.io.IOException: error=13, Permission denied
at java.lang.UNIXProcess.forkAndExec(Native Method)
at java.lang.UNIXProcess.<init>(UNIXProcess.java:247)
at java.lang.ProcessImpl.start(ProcessImpl.java:134)
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1029)
問題の分析・解決
上記のエラーレポートによると、アクセス権がないと書いてあります。これはすべてシステムにデフォルトでインストールされている可能性がありますが、どうなっているのでしょうか?ニック・ヤングの顔クエスチョンマーク!!(笑
そのあとはgoogle、baidu、bingいろいろ検索です。それらのほとんどは、環境変数を変更する:と書いてあります。
~/.bashrc
というのは、実はずっと前に変更したのですが、それでも直りませんでした。
ちなみに、ここで言及します。このエラーについては、どのように
spark
. を使い、手動で行いました。
Cloudera Manager
配分を試みました。今のところ手動インストールでは、読み込んでいる
HDFS
ファイル(このエラーも簡単に直せます)を除いては
Cloudera Manager
を割り当てたコンポーネントが正しく動作しません。
Sparkを手動でインストールする
こちらも手動でインストールします
Spark
環境変数の設定です。
厦門大学のデータベース研究室を参照して、このようなことをしました。 リンク
Clouder Managerのアサインメントを使用する
以下の画像はWeb検索で見つけたものです。

は、同じものを持つことを意味します。
Python
この問題は長い間解決されなかったので、希望がある限り試してみることにしました。そこで、7つのVMそれぞれにanacondaをインストールしたのですが、これが本当に面倒で、運が悪かったです(でも、各ノードでバージョンを統一しておくことも推奨されています)。
次の2つの画像を見るまで、解決は続きました。
まずこの作者は、私のエラー報告と同じように、問題を投げかけるところから始めます。
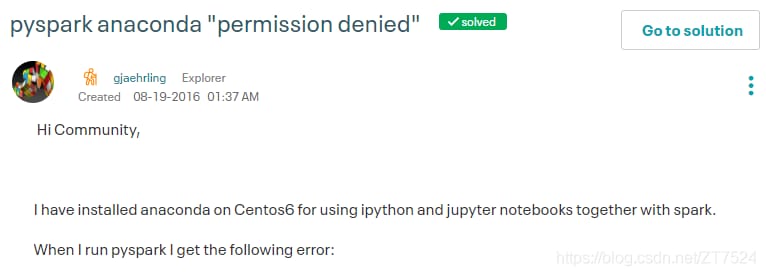
やっと、自分の投稿を見返した。再インストールされたとのこと
anaconda
から
/opt/anaconda
ディレクトリで解決します。
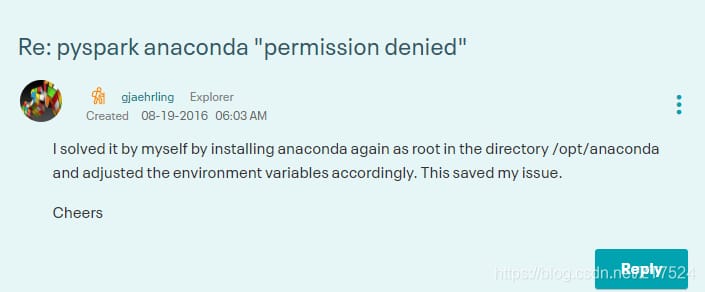
上記のヒントを元に
anaconda
で再インストール。
/opt/
ディレクトリにインストールされます(デフォルトでは
/root
ディレクトリ)を読み込んで
HDFS
データは、現在
linuxシステムインストール
anaconda
参考ファイル
注意:インストール後に ~/.bashrc ファイル内の環境変数をここで変更することを忘れないでください。
export PYSPARK_DRIVER_PYTHON=ipython
export PYSPARK_PYTHON=/opt/anaconda/bin/python
読み込みに成功
HDFS
ファイルを作成します。
(base) [root@slave3 opt]# pyspark2
Python 3.7.3 (default, Mar 27 2019, 22:11:17)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.4.0 -- An enhanced Interactive Python. type '? for help.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
19/08/07 14:15:17 WARN lineage.LineageWriter: Lineage directory /var/log/spark2/lineage doesn't exist or is not writable. Lineage for this application will be disabled.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / . __/\/_,_/_/ /_/\/\_\ version 2.4.0.cloudera1
/_/
Using Python version 3.7.3 (default, Mar 27 2019 22:11:17)
SparkSession available as 'spark'.
In [1]: input = sc.textFile("/user/platform/dga/output_file/20190610172348.txt")
In [2]: input.first()
Out[2]: 'baidu.com,legit,0.15,0.85'
In [3]: input.take(10)
Out[3]:
['baidu.com,legit,0.15,0.85',
'taobao.com,legit,0.0,1.0',
'vovo.tech,legit,0.0,1.0',
'ecmychar.live,legit,0.05,0.95',
これで問題は解決です。本当の解決は簡単なのですが、何が問題なのかを理解するのは簡単ではありません。
奔放なコーダーからスタートし、風月を語りながら技術を語る

関連
-
'dict' オブジェクトには 'has_key' という属性がありません。
-
Python組み込み関数 - min関数とmax関数 - 詳細解説
-
Python仮想環境のインストールと設定
-
Python3ダウンロードファイルです。AttributeError:モジュール 'urllib' には 'request' という属性がありません。
-
Python pipを使ったpymysqlモジュールのインストール (Error: ImportError: No module named pymysql)
-
ModuleNotFoundError: Pythonソリューションに'scipy'という名前のモジュールがありません。
-
Python OSError: [Errno 22] 無効な引数: solution
-
TypeError: Json オブジェクトは str, bytes または bytearray でなければならず、'TextIOWrapper' ではありません。
-
Python3+BeautifulSoupがUnicodeEncodeErrorを報告:'charmap' codec can't encode characters in position
-
pythonのエラーです。ValueError: 閉じたファイルへのI/O操作
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Pythonコードのデバッグ問題:IOError: イメージファイルを識別できない
-
Error: cannot run program--createprocess error=2,The system cannot find specified file.
-
pythonがggplotパッケージを呼び出すとエラーが発生する AttributeError: 'DataFrame' オブジェクトに 'sort' 属性がない
-
SyntaxError: 構文が無効です。
-
Pythonインストールモジュールエラー AttributeError: モジュール 'pip' には 'main' という属性がありません。
-
Pythonでナンバープレート自動認識システムを作ろう!楽しくて実用的です。
-
[コード】pygame 学習
-
Python Hashmap/Dictionary 使用ガイド
-
Pythonクローラー共通ライブラリリクエスト、beautifulsoup、selenium、xpathまとめ
-
Python error TypeError: 'type' object is not subscriptable