[解決済み】ナイーブベイズ分類の簡単な説明【終了しました
質問
Naive Bayesのプロセスがわかりにくいので、どなたか英語で簡単にステップバイステップで説明していただけませんか?発生した回数で比較を確率として取るのはわかるのですが、学習データと実際のデータセットがどう関係しているのかが全くわかりません。
トレーニングセットがどのような役割を果たすのか、解説をお願いします。ここでは果物、例えばバナナのような非常に簡単な例を挙げています。
training set---
round-red
round-orange
oblong-yellow
round-red
dataset----
round-red
round-orange
round-red
round-orange
oblong-yellow
round-red
round-orange
oblong-yellow
oblong-yellow
round-red
解決方法は?
1つは、Naive Bayesの分類器とランプについてもっとよく理解する必要があるということ、もう1つは、トレーニングセットに関する混乱です。
一般に機械学習アルゴリズムは、分類や予測などの教師あり学習や、クラスタリングのような教師なし学習のタスクのために学習させる必要があります。
学習ステップでは、アルゴリズムは特定の入力データセット(学習セット)で学習され、後に未知の入力(見たこともないもの)に対してテストを行い、その学習に基づいて分類や予測などを行います(教師あり学習の場合)。ニューラルネット、SVM、ベイズなどの機械学習技術のほとんどはこれに基づいている。
一般的な機械学習プロジェクトでは、基本的に入力セットを開発セット(トレーニングセット+開発-テストセット)とテストセット(または評価セット)に分割する必要があります。基本的な目的は、開発セットまたはテストセットのどちらかで、システムが今まで見たことのない新しい入力を学習し、分類することであることを忘れないでください。
テストセットは通常、トレーニングセットと同じ形式をとります。しかし、テストセットは訓練コーパスと異なることが非常に重要です。 トレーニングセットをテストセットとして再利用した場合、新しい例に対する汎化方法を学習せずに、単に入力を記憶したモデルは、誤解を招くような高得点を得ることになります。
一般的には、例として、データの70%をトレーニングセットのケースとして使用することができます。また、元のセットをトレーニングセットとテストセットに分割することも忘れないようにしましょう ランダムに .
では、もうひとつの質問であるナイーブベイズについてです。
ナイーブベイズ分類の概念を示すために、次のような例を考えてみましょう。
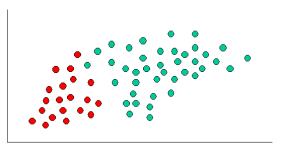
このように、オブジェクトは次のいずれかに分類されます。
GREEN
または
RED
. 私たちの仕事は、新しいケースが到着したら、それを分類すること、つまり、現在存在するオブジェクトに基づいて、どのクラスラベルに属するかを決定することである。
の2倍の数があるので
GREEN
オブジェクトと
RED
のメンバーである可能性は2倍と考えるのが妥当である。
GREEN
よりも
RED
. ベイズ解析では、この確信が事前確率と呼ばれる。事前確率は、過去の経験、この場合は
GREEN
と
RED
オブジェクトであり、実際に起こる前に結果を予測するためによく使われる。
したがって、こう書くことができる。
の事前確率
GREEN
:
number of GREEN objects / total number of objects
の事前確率
RED
:
number of RED objects / total number of objects
があるので、合計で
60
オブジェクトを作成します。
40
のうち
GREEN
および20
RED
となり、クラスメンバーシップの事前確率は次のようになります。
の事前確率
GREEN
:
40 / 60
の事前確率
RED
:
20 / 60
事前確率を定式化したことで、新しいオブジェクトを分類する準備が整いました (
WHITE
下図の○印)。オブジェクトはよくクラスタリングされているので、より多くの
GREEN
(または
RED
の近傍にあるものほど、その色に属している可能性が高い。この可能性を測定するために、我々はXの周りに、クラスラベルに関係なく点の数(先験的に選択される)を包含する円を描く。そして、円内の各クラス・ラベルに属する点の数を計算する。これより、尤度を計算する。
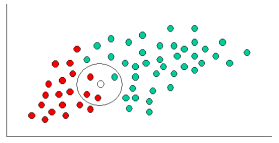
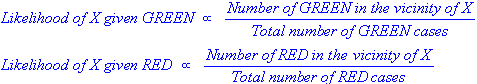
上記の図から、Likelihood of
X
与えられた
GREEN
は、Likelihood of
X
与えられた
RED
を包含するため、円は
1
GREEN
オブジェクトと
3
RED
のものです。このように
![]()
![]()
事前確率では
X
に属している可能性があります。
GREEN
(の2倍あることを考えると)。
GREEN
と比較して
RED
のクラスメンバーシップは、尤度がそうでないことを示している。
X
は
RED
(もっとたくさんあることを考えると
RED
の近辺にあるオブジェクトを
X
より
GREEN
). ベイズ解析では、いわゆるベイズの法則(Thomas Bayes 1702-1761にちなんで命名)を用いて、事前情報と尤度の両方の情報源を組み合わせて事後確率を形成することにより、最終的な分類がなされます。

最後に、Xを次のように分類します。
RED
そのクラスメンバーシップは最大の事後確率を達成するため。
関連
-
[解決済み] Sliding Window Algorithmとは?例題は?
-
[解決済み] 大きなӨ記号は具体的に何を表すのですか?
-
[解決済み] ヒープ化 VS ビルドヒープ
-
[解決済み] 最大スパニングツリーの求め方は?
-
[解決済み] 数字の範囲を表すときの「exclusive」「inclusive」の意味は?
-
[解決済み] 深さ優先グラフアルゴリズムの時間複雑性【非公開
-
[解決済み】美観を損なわないカラーパレットをランダムに生成するアルゴリズム【終了しました
-
[解決済み】遺伝的アルゴリズム/遺伝的プログラミングの良い解決例とは?[クローズド]
-
[解決済み】異なるサイズの長方形を、かなり最適な方法で可能な限り小さな長方形に詰め込むには、どのようなアルゴリズムが使用できるだろうか?
-
[解決済み】丸められたパーセンテージを100%にする方法
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] TSPの場合、Held-Karpアルゴリズムは、Brute-forceのO(n!)からO(2^n*n^2)に時間複雑性をどのように減少させるのでしょうか?[クローズド]
-
[解決済み] Sliding Window Algorithmとは?例題は?
-
[解決済み] O(n)とO(log(n))の違い -どちらが優れていて、O(log(n))とは一体何なのか?
-
[解決済み] Breadth First Searchの時間複雑性解析
-
[解決済み] n個のユニオンのfind(サイズによるユニオン)演算を実行する際の時間計算量がO(n log n)であるのはなぜか?
-
[解決済み] バックトラックアルゴリズムの時間計算方法は?
-
[解決済み] O(log* N)とは何ですか?
-
[解決済み] NP - 非決定性多項式時間
-
[解決済み】ある点が2次元の三角形の中にあるかどうかを判断する方法は?[クローズド]
-
[解決済み】最も近い文字列のマッチを取得する