[解決済み】最も近い文字列のマッチを取得する
質問
複数の文字列をテスト文字列と比較し、最も近い文字列を返す方法が必要です。
TEST STRING: THE BROWN FOX JUMPED OVER THE RED COW
CHOICE A : THE RED COW JUMPED OVER THE GREEN CHICKEN
CHOICE B : THE RED COW JUMPED OVER THE RED COW
CHOICE C : THE RED FOX JUMPED OVER THE BROWN COW
(私のやり方が正しければ) "TEST STRING" に最も近い文字列は "CHOICE C" になるはずです。 これを行う最も簡単な方法は何ですか?
VB.net、Lua、JavaScriptなど複数の言語への実装を予定しています。 現時点では、擬似的なコードでも構いません。 特定の言語の例を示していただけると、こちらもありがたいです。
解決方法は?
1年ほど前、ユーザーが入力した石油掘削装置の情報を、雑多な情報を集めたデータベースから探すことになったとき、この問題を提示されました。目標は、最も一般的な要素を持つデータベースエントリを識別できる、ある種のファジー文字列検索を行うことでした。
研究の一環として レーベンシュタイン距離 これは、ある文字列やフレーズを別の文字列やフレーズに変換するために、何回変更しなければならないかを判断するアルゴリズムです。
私が考えた実装は比較的単純で、2つのフレーズの長さ、各フレーズ間の変化数、そして各単語が対象エントリで見つかるかどうかを重み付けして比較するものでした。
個人サイトに掲載されている記事なので、極力ここに該当する内容を追記します。
ファジーストリングマッチングは、2つの単語やフレーズの類似性を人間のように推定するプロセスである。多くの場合、最も類似している単語やフレーズを特定することが含まれる。この記事では、ファジー文字列照合問題に対する社内ソリューションと、これまで面倒なユーザーの関与を必要としていたタスクを自動化できるようにする、さまざまな問題解決におけるその有用性を説明します。
はじめに
ファジー文字列マッチングの必要性は、もともとGulf of Mexico Validatorというツールの開発中に生まれました。保険に加入している人たちは、自分の資産に関する、ひどくタイプアウトされた情報を私たちに提供し、私たちはそれを既知のプラットフォームのデータベースと照合しなければなりませんでした。情報がほとんどない場合、保険契約者がどのリグを指しているかを認識し、適切な情報を呼び出せるかどうかが、私たちにできる精一杯のことでした。そこで、この自動化されたソリューションが役に立ちました。
ファジー文字列照合の方法を1日かけて調べ、最終的にWikipediaで非常に有用なレーベンシュタイン距離アルゴリズムに行き着きました。
実装方法
その背景となる理論について読んだ後、実装し、最適化する方法を探しました。VBAで書くとこんな感じです。
'Calculate the Levenshtein Distance between two strings (the number of insertions,
'deletions, and substitutions needed to transform the first string into the second)
Public Function LevenshteinDistance(ByRef S1 As String, ByVal S2 As String) As Long
Dim L1 As Long, L2 As Long, D() As Long 'Length of input strings and distance matrix
Dim i As Long, j As Long, cost As Long 'loop counters and cost of substitution for current letter
Dim cI As Long, cD As Long, cS As Long 'cost of next Insertion, Deletion and Substitution
L1 = Len(S1): L2 = Len(S2)
ReDim D(0 To L1, 0 To L2)
For i = 0 To L1: D(i, 0) = i: Next i
For j = 0 To L2: D(0, j) = j: Next j
For j = 1 To L2
For i = 1 To L1
cost = Abs(StrComp(Mid$(S1, i, 1), Mid$(S2, j, 1), vbTextCompare))
cI = D(i - 1, j) + 1
cD = D(i, j - 1) + 1
cS = D(i - 1, j - 1) + cost
If cI <= cD Then 'Insertion or Substitution
If cI <= cS Then D(i, j) = cI Else D(i, j) = cS
Else 'Deletion or Substitution
If cD <= cS Then D(i, j) = cD Else D(i, j) = cS
End If
Next i
Next j
LevenshteinDistance = D(L1, L2)
End Function
シンプルでスピーディー、そしてとても便利な指標です。これを利用して、2つの文字列の類似性を評価するための2つの別々のメトリクスを作成しました。valuePhraseは2つのフレーズ間のレーベンシュタイン距離で、valueWordsは文字列をスペースやダッシュなどの区切り文字で個々の単語に分割し、それぞれの単語を他の単語と比較して、任意の2つの単語を結ぶ最短レーベンシュタイン距離を合計します。つまり、ある「フレーズ」の情報が、本当に別の「フレーズ」に含まれているかどうかを、単語単位で並べ替えて測定するのである。私は、サイドプロジェクトとして、区切り文字に基づいて文字列を分割する最も効率的な方法を考え出すのに数日を費やしました。
valueWords、valuePhrase、Split関数です。
Public Function valuePhrase#(ByRef S1$, ByRef S2$)
valuePhrase = LevenshteinDistance(S1, S2)
End Function
Public Function valueWords#(ByRef S1$, ByRef S2$)
Dim wordsS1$(), wordsS2$()
wordsS1 = SplitMultiDelims(S1, " _-")
wordsS2 = SplitMultiDelims(S2, " _-")
Dim word1%, word2%, thisD#, wordbest#
Dim wordsTotal#
For word1 = LBound(wordsS1) To UBound(wordsS1)
wordbest = Len(S2)
For word2 = LBound(wordsS2) To UBound(wordsS2)
thisD = LevenshteinDistance(wordsS1(word1), wordsS2(word2))
If thisD < wordbest Then wordbest = thisD
If thisD = 0 Then GoTo foundbest
Next word2
foundbest:
wordsTotal = wordsTotal + wordbest
Next word1
valueWords = wordsTotal
End Function
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
' SplitMultiDelims
' This function splits Text into an array of substrings, each substring
' delimited by any character in DelimChars. Only a single character
' may be a delimiter between two substrings, but DelimChars may
' contain any number of delimiter characters. It returns a single element
' array containing all of text if DelimChars is empty, or a 1 or greater
' element array if the Text is successfully split into substrings.
' If IgnoreConsecutiveDelimiters is true, empty array elements will not occur.
' If Limit greater than 0, the function will only split Text into 'Limit'
' array elements or less. The last element will contain the rest of Text.
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
Function SplitMultiDelims(ByRef Text As String, ByRef DelimChars As String, _
Optional ByVal IgnoreConsecutiveDelimiters As Boolean = False, _
Optional ByVal Limit As Long = -1) As String()
Dim ElemStart As Long, N As Long, M As Long, Elements As Long
Dim lDelims As Long, lText As Long
Dim Arr() As String
lText = Len(Text)
lDelims = Len(DelimChars)
If lDelims = 0 Or lText = 0 Or Limit = 1 Then
ReDim Arr(0 To 0)
Arr(0) = Text
SplitMultiDelims = Arr
Exit Function
End If
ReDim Arr(0 To IIf(Limit = -1, lText - 1, Limit))
Elements = 0: ElemStart = 1
For N = 1 To lText
If InStr(DelimChars, Mid(Text, N, 1)) Then
Arr(Elements) = Mid(Text, ElemStart, N - ElemStart)
If IgnoreConsecutiveDelimiters Then
If Len(Arr(Elements)) > 0 Then Elements = Elements + 1
Else
Elements = Elements + 1
End If
ElemStart = N + 1
If Elements + 1 = Limit Then Exit For
End If
Next N
'Get the last token terminated by the end of the string into the array
If ElemStart <= lText Then Arr(Elements) = Mid(Text, ElemStart)
'Since the end of string counts as the terminating delimiter, if the last character
'was also a delimiter, we treat the two as consecutive, and so ignore the last elemnent
If IgnoreConsecutiveDelimiters Then If Len(Arr(Elements)) = 0 Then Elements = Elements - 1
ReDim Preserve Arr(0 To Elements) 'Chop off unused array elements
SplitMultiDelims = Arr
End Function
類似性の尺度
この2つの指標と、2つの文字列の距離を単純に計算する3つ目の指標を使って、最大のマッチング数を達成するために最適化アルゴリズムを実行するための一連の変数ができました。ファジー文字列マッチングはそれ自体がファジーな科学であり、 文字列の類似性を測定するための線形的に独立した測定基準を作成し、 互いにマッチさせたい文字列のセットを知っておくことで、 我々の特定のスタイルの文字列に対して、最高のファジーマッチ結果を与える パラメータを見つけることができます。
当初は、完全一致の場合の検索値が低く、順列化が進むと検索値が高くなるような指標を目標としていました。非現実的なケースですが、定義された並べ換えのセットを使って定義するのは非常に簡単で、最終的な数式を設計して、希望通りに検索値が増加する結果を得ることができました。
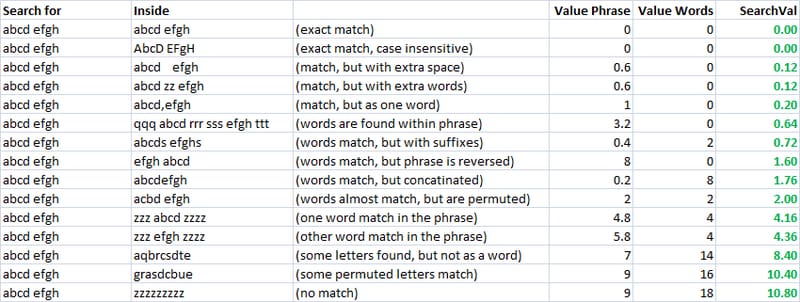
上のスクリーンショットでは、ヒューリスティックを微調整して、検索語と結果の違いを感じながら、うまくスケーリングできるようなものを考えています。私が使ったヒューリスティックは
Value Phrase
は、上記のスプレッドシートで
=valuePhrase(A2,B2)-0.8*ABS(LEN(B2)-LEN(A2))
. 私は、レーベンシュタイン距離のペナルティを、2つの"phrase"の長さの差の80%で、効果的に減らしていました。この方法では、同じ長さの "phrases" は完全なペナルティを受けますが、「追加情報」を含む(長い) "phrases" は、それを除けば、ほとんど同じ文字を共有しているので、ペナルティを軽減することができます。私は
Value Words
関数をそのまま使用し、最終的に
SearchVal
ヒューリスティックは次のように定義されました。
=MIN(D2,E2)*0.8+MAX(D2,E2)*0.2
- 加重平均です。2つのスコアのうち、低い方が80%、高い方が20%の重み付けをした。これは、マッチング率を上げるためのヒューリスティックな方法です。これらの重みは、テストデータで最高のマッチング率を得るために微調整することができます。
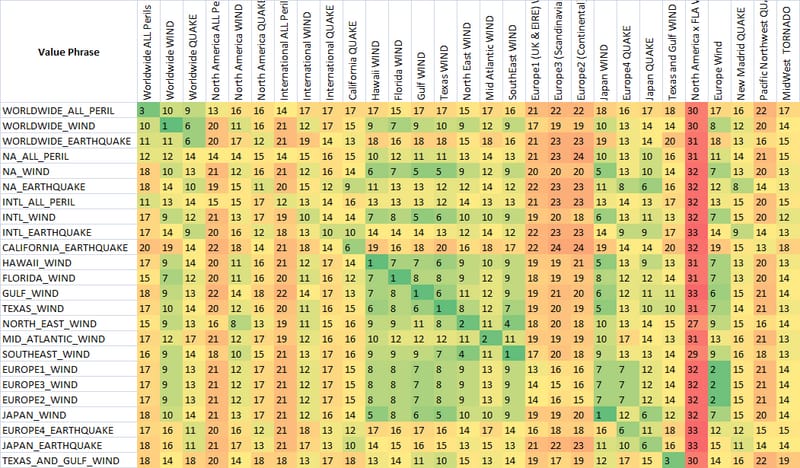
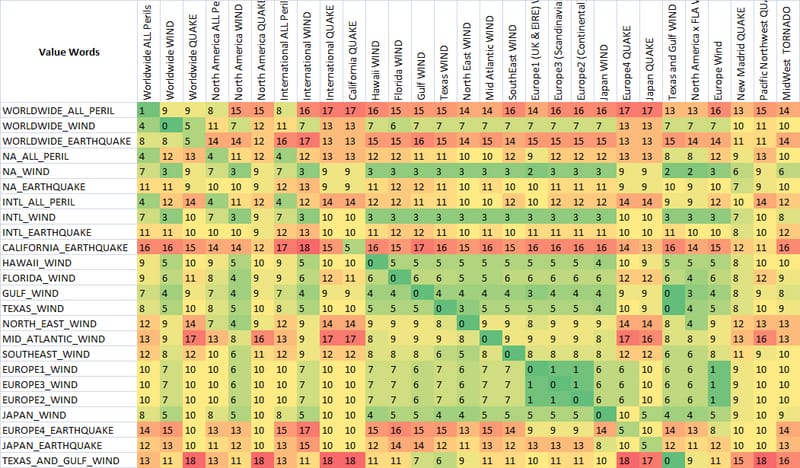
ご覧のように、ファジー文字列マッチングメトリクスである最後の2つのメトリクスは、すでにマッチすることを意図した文字列に低いスコアを与える自然な傾向があります(対角線の下)。これは非常に良いことです。
応用編 ファジーマッチングを最適化するために、それぞれの指標に重み付けをしています。そのため、ファジー文字列照合のアプリケーションごとに、パラメータの重み付けを変えることができる。最終的なスコアを定義する式は、評価指標とその重みの単純な組み合わせである。
value = Min(phraseWeight*phraseValue, wordsWeight*wordsValue)*minWeight
+ Max(phraseWeight*phraseValue, wordsWeight*wordsValue)*maxWeight
+ lengthWeight*lengthValue
最適化アルゴリズム(離散的で多次元的な問題なので、ここではニューラルネットワークが最適)を使って、今度はマッチング数を最大化することが目標になります。最終的なスクリーンショットに見られるように、各セットが互いに何回正しくマッチしたかを検出する関数を作成しました。ある列や行が、マッチするはずだった文字列に最低点が割り当てられた場合に1点、最低点が同点で、同点の文字列の中に正しいマッチがある場合に部分点が与えられます。その後、最適化を行った。緑色のセルは現在の行と最もよく一致する列で、セルを囲む青色の四角は現在の列と最もよく一致する行であることがわかる。下の隅にあるスコアは、おおよそ成功したマッチの数であり、これを最大化するように最適化問題に指示するのです。
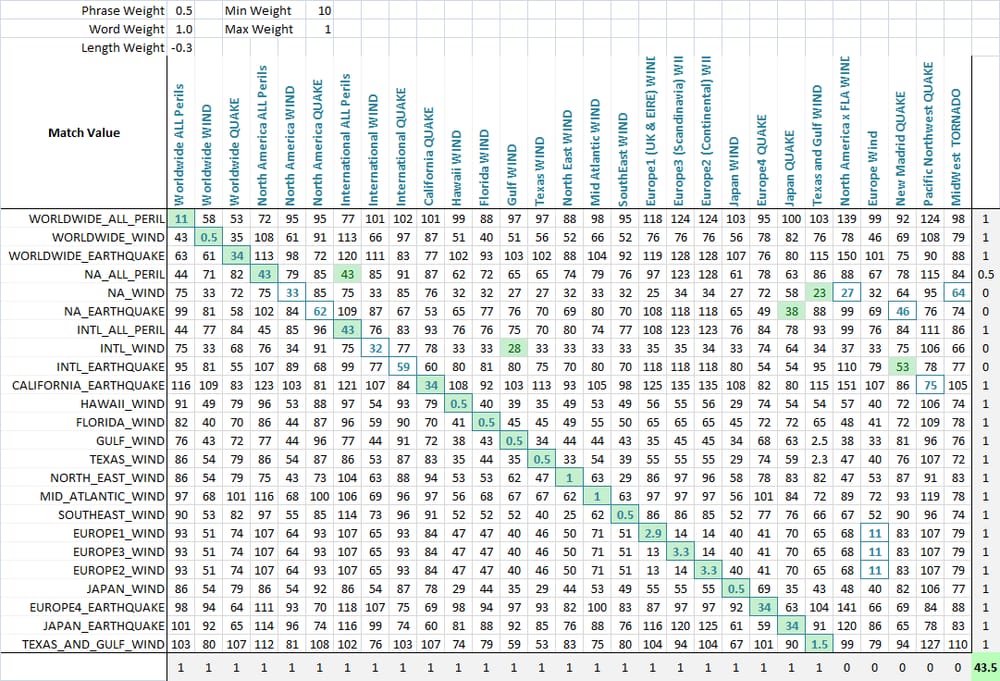
アルゴリズムは素晴らしい成功を収め、解のパラメータはこの種の問題について多くのことを語っています。最適化されたスコアは44で、可能な限り最高のスコアは48であることにお気づきでしょう。最後の5列はおとりであり、行の値とは全く一致しない。囮が多ければ多いほど、当然ながらベストマッチを見つけるのは難しくなります。
この特別なマッチングの場合、長い単語を表す略語を期待しているので、文字列の長さは関係なく、長さに対する最適な重みは-0.3、つまり、長さが異なる文字列にはペナルティを課さない。つまり、長さの異なる文字列にはペナルティを課さないということです。このような省略形を想定してスコアを減らし、部分的な単語マッチが、文字列が短いために単純に少ない置換で済む非単語マッチより優先される余地を増やしました。
単語の重みが1.0であるのに対し、フレーズの重みは0.5しかない。つまり、ある文字列から単語全体が欠落しているとペナルティを課し、フレーズ全体をそのまま評価するのである。これは、これらの文字列の多くに共通する単語(peril)があり、本当に重要なのは組み合わせ(regionとperil)が維持されているかどうかであるため、有用である。
これは、2つのスコア(Value phraseとValue words)のうち、最も良いものがあまり良くない場合、マッチングに大きなペナルティを与えるが、最も悪いものには大きなペナルティを与えないという意味である。本質的に、これは どちらか のどちらかが良いスコアであることが必要で、両方は必要ありません。一種の「取れるものは取ってしまえ」的な考え方です。
この5つの重みの最適化された値が、どのようなファジーストリングマッチングが行われているかを示すのは、実に興味深いことです。ファジー文字列マッチングの全く異なる実用的なケースで、これらのパラメーターは非常に異なっています。私はこれまでに3つのアプリケーションでこれを使いました。
最終的な最適化には使用されませんでしたが、ベンチマークシートが作成され、対角線上のすべての完全な結果に対して列を自分自身にマッチさせ、ユーザーがパラメータを変更してスコアが0から分岐する速度を制御したり、検索フレーズ間の生来の類似性(理論的には結果の偽陽性を相殺するために使用可能)に注目したりできるようになりました。

その他のアプリケーション
このソリューションは、完全には一致しない文字列の集合の中からコンピュータシステムに文字列を識別させたい場合に、どこでも使える可能性がある。(文字列の近似一致vlookupのようなもの)。
つまり、レーベンシュタイン距離アルゴリズムの実装と高レベルのヒューリスティック(一方のフレーズから他方のフレーズの単語を見つける、両方のフレーズの長さなど)を組み合わせて使用したいのだろうということです。なぜなら、ベストマッチの決定は、ヒューリスティックな(ファジーな)決定だからです - 類似性を決定するために、どのような測定基準に対しても重みのセットを考え出す必要があります。
適切なヒューリスティックと重みのセットがあれば、比較プログラムは、あなたが下したであろう決断を素早く行うことができます。
関連
-
[解決済み] Zip爆弾はどうやって作るの?
-
[解決済み] メソッドと関数の違いは何ですか?
-
[解決済み] ゲーム「2048」の最適なアルゴリズムとは?
-
[解決済み] 抽象メソッドと仮想メソッドの違いは何ですか?
-
[解決済み] 並行処理と並列処理の違いは何ですか?
-
[解決済み] 簡単な面接問題が難しくなった:1~100の数字が与えられたとき、ちょうどk個の数字が欠けていることを見つけなさい。
-
[解決済み】ある点が2次元の三角形の中にあるかどうかを判断する方法は?[クローズド]
-
[解決済み】log(n!)=Θ(n-log(n))なのか?)
-
[解決済み】ポリゴンの膨張・収縮(オフセット、バッファリング)のためのアルゴリズム
-
[解決済み】固定長 6 int 配列の最速ソート
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] ソートされていない配列でバイナリサーチは使えるか?重複
-
[解決済み] TSPの場合、Held-Karpアルゴリズムは、Brute-forceのO(n!)からO(2^n*n^2)に時間複雑性をどのように減少させるのでしょうか?[クローズド]
-
[解決済み] 再帰の複雑さ T(n) = T(n-1) + T(n-2) + C
-
[解決済み] O(n)とO(log(n))の違い -どちらが優れていて、O(log(n))とは一体何なのか?
-
[解決済み] Breadth First Searchの時間複雑性解析
-
[解決済み] ビッグ・オー vs ビッグ・シータ【重複あり
-
[解決済み] Zip爆弾はどうやって作るの?
-
[解決済み】8歳児にビッグ・オー?[重複あり]
-
[解決済み】与えられた和になるように数字の組み合わせの可能性を探す
-
[解決済み】最も近い文字列のマッチを取得する