オーバーフィットを克服し、汎化率を向上させるための20のヒントとコツ
オーバーフィットを克服し、汎化率を向上させるための20のヒントとコツ
ディープラーニングモデルの効果をどのように高めていますか?
これはよく聞かれる質問です。
また、時には別の意味で聞かれることもあります。
モデルの精度を上げるにはどうしたらいいですか?
......あるいは逆に、尋ねる。
Webモデルの調子が悪いときはどうしたらいいですか?
通常、私は「原因はよくわからないが、試してみたいことがある」と答えます。
そして、パフォーマンスを向上させることができると思う方法をいくつか挙げていきます。
そのリストを繰り返すことを避けるために、この記事ではそれらをすべて書き出します。
これらのアイデアは、深層学習だけでなく、実はあらゆる機械学習アルゴリズムに利用することができます。

ディープラーニングの性能を向上させる方法
ペドロ・リベイロ・シモエス
撮影
アルゴリズムの性能を向上させるアイデア
このリストは完全ではありませんが、良い出発点となるでしょう。
私の意図は、あなたが試せるようにいくつかのアイデアを投げかけることであり、もしかしたら1つか2つ、うまくいくものがあるかもしれません。
1つのアイデアを試すだけで、効果が出ることもよくあります。
もし、以下のアイデアに良い結果が出たなら、コメント欄で教えてください。
他のアイデアや、これらのアイデアを発展させたものがあれば、ぜひ教えてください!みんなの役に立つかもしれません。
このリストを4つに分けてみました。
- データから見る性能向上
- アルゴリズムによる性能向上
- アルゴリズムチューニングによる性能向上
- モデルフュージョンによる性能向上
性能向上は、上の表の順番で上から下へと減少していきます。例として、最適なパラメータをチューニングするよりも、新しいモデリング手法やデータを増やす方が良い結果をもたらす傾向があります。しかし、これは絶対的なものではなく、ほとんどそうであるというだけです。
ブログのチュートリアルをかなり追加しましたので、記事と関連する
古典的なニューラルネットワークの問題
.
これらのアイデアの中には、人工ニューラルネットワークだけのものもありますが、ほとんどは一般的なものです。他の手法と組み合わせて使うこともできます。
さっそく始めてみましょう。
1. データから見るパフォーマンス向上
学習データや抽象的な問題定義の方法をいじることで、結果が大きく改善されることがあります。最も劇的な改善も
以下はその概要です。
- より多くのデータを収集する
- より多くのデータを生成する
- データに対してスケーリングを行う
- データを変換する
- フィーチャー選択
- 問題の再定義
1) より多くのデータを収集する
まだトレーニングデータを集められるのか?
モデルの品質は、多くの場合、トレーニングデータの品質に依存します。問題に対して最も効果的なデータを使用していることを確認する必要があります。
また、データはできるだけ多く持っておきたいものです。
特にディープラーニングをはじめとする最新の非線形機械学習モデルは、大規模なデータセットでより効果的に機能します。これは、ディープラーニングの手法がエキサイティングである主な理由の1つです。
以下の画像をご覧ください。
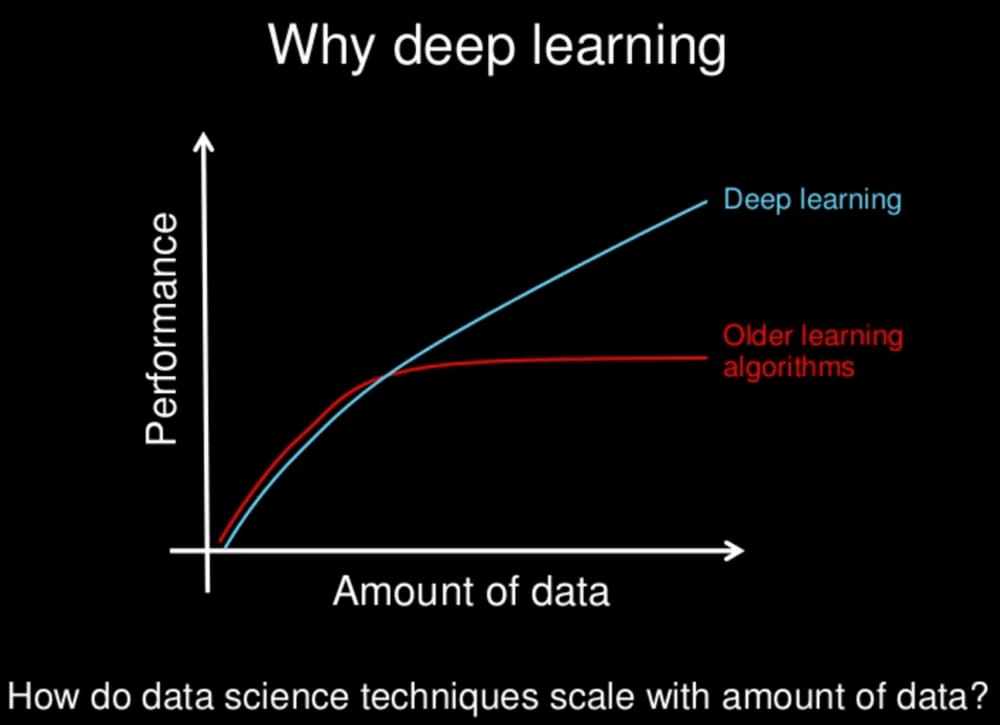
ディープラーニングとは?
Andrew Ng氏によるスライド
データはたくさん読めば読むほどいいかというと、必ずしもそうではなく、ほとんどの場合そうです。もし私に選択肢があれば、より多くのデータを求める方を選びます。
関連する読み物
2) より多くのデータを生成する
ディープラーニングのアルゴリズムは、大量のデータがあるときにうまく機能する傾向があります。
前項ですでに述べたとおりです。
何らかの理由でデータが増えない場合は、データを作ることもできます。
- データが数値ベクトルである場合、既存のベクトルの変形ベクトルをランダムに生成します。
- データが画像の場合、既存の画像から類似画像をランダムに生成する。
- データがテキストなら、やり方はわかっているはず ......。
このような実践は、データ拡張やデータ生成と呼ばれることが多い。
生成モデルを使ってもいいし、簡単なトリックを使ってもいい。
例えば、画像データであれば、既存の画像をランダムに選択し、パンニングするだけで、大きな効果を得ることができます。モデルの汎化性が向上しますし、新しいデータにこの種の変換が含まれていても、うまく処理することができます。
データにノイズを加えることもありますが、これは学習データのオーバーフィットを避けるためのルールベース・アプローチに相当します。
関連する読み物
3) データにスケーリングを施す
この方法は、シンプルで効果的です。
ニューラルネットワークモデルを利用する際の一つの目安になるのが
データを活性化関数の閾値範囲にスケーリングする。
シグモイド活性化関数を使用する場合は、0から1の間になるようにデータをスケーリングし、tanh活性化関数を選択した場合は、-1から1の間の値の範囲を維持します。
入力データと出力データは、同じように変換されます。例えば、出力層に出力値を2値データに変換するシグモイド関数がある場合、出力 y は2値に正規化される。ソフトマックス関数が選択された場合でも、y の正規化は有効である。
また、学習データを拡張して、いくつかの異なるバージョンを生成することをお勧めします。
- 0 ~ 1 に正規化する
- 1〜1まで正規化
- 標準化
その後、各データセットでモデルの性能をテストし、最適な生成データセットを選択する。
活性化関数を変更した場合は、この小さな実験を繰り返すとよいでしょう。
モデル内で大きな値を計算することは適切ではありません。また、重みの正規化や活性化値など、モデル内のデータを圧縮する方法は他にもたくさんありますが、これらのテクニックは後ほど説明します。
関連する読み物
4) データに変換を施す
前節のアプローチに関連するが、より多くの作業が必要である。
使用するデータを本当に理解する必要があります。データをビジュアル化し、異常値を拾い出す。
各列のデータの分布を推測することから始める
- この列のデータは歪んだガウス分布なのか、もしそうならBox-Cox法で歪みを補正してみる
- この列は指数関数的に分布しているか、もしそうなら、対数変換する。
- この列のデータには、視覚的に検出することが困難な何らかの特性があるか、データを二乗するか二乗してみる
- いくつかの特徴をより強調するために、特徴を離散化することはできないか
直感で、いくつかのアプローチを試してみてください。
- PCAなどの投影法を用いてデータを前処理することは可能か?
- 複数の属性を1つの値にまとめることは可能ですか?
- ブール値で表現される新しい属性を発見することは可能ですか?
- 時間軸や異次元での新しい発見は可能か?
ニューラルネットワークには特徴学習があり、こういうことができるんです。
でも、問題の構造をうまく提示できれば、ネットワークモデルをより早く習得することができますよ。
トレーニングセットで様々な変換を素早く試し、どの変換がある程度効果があり、どの変換が効果がないかを確認する。
関連する読み物
5) 特徴の選択
ニューラルネットワークは、相関のないデータからの影響を最小限に抑えることができます。
そのため、予測値に対するその特徴の寄与はほとんど無視され、0に近い重みが割り当てられる。
学習データの特定の属性を削除することは可能ですか?
どの特徴を残して、どの特徴を削除する必要があるかを特定するために、特徴選択法や特徴重要度法などを用意しています。
手を動かして、すべてのメソッドを試してみてください。
時間に余裕がある場合は、やはり同じニューラルネットワークモデルで複数の方法を試して、それぞれの効果を確認する方法を選択することをお勧めします。
- より少ない特徴量で同じ、あるいはより良い結果が得られるかもしれません。
- もしかしたら、すべての特徴選択法が、同じ特徴属性のセットを破棄することを選択するかもしれません。それなら、これらの無駄な特徴をよく見てみるべきでしょう。
- 選択された機能が、もっと新しい機能を作るきっかけになったのかもしれません。
関連する読み物
6) 問題のリファクタリング
問題の定義に戻ると
あなたが収集したこれらの観察は、問題を説明する唯一の方法ですか?
もしかしたら、他の方法があるかもしれません。問題の構造をより明確に浮かび上がらせる他の方法があるのかもしれません。
私自身は、この演習がとても好きです。なぜなら、思考の幅を広げることを強いられるからです。うまくやるのは難しいんですけどね。特に、既存の手法に多くの時間、労力、資金を費やしてきた場合はなおさらです。
たとえ3~5種類の方法を挙げたとしても、少なくとも最終的に選んだ方法には十分な自信があるはずです。
- 時間的な要素をウィンドウに組み込んでもいいかもしれない
- 分類の問題は回帰の問題に変換できるかもしれませんし、その逆もしかりです。
- おそらく、バイナリ型の出力はソフトマックスに変換することができるだろう
- サブ問題をモデル化できるかもしれない
問題について深く考えることは良い習慣であり、非効率な労力を減らすために、上記のステップを完了してからツールを選択するのがベストです。
いずれにせよ、途方に暮れている方は、このシンプルな連続体から考えてみてはいかがでしょうか。
また、下準備をたくさんサボる必要はありません、詳しくは後の章をご覧ください。
関連する読み物
2. アルゴリズムによる性能向上
機械学習は常にアルゴリズムが重要です。
すべての理論と数学的知識は、データから意思決定プロセスを学習するさまざまな方法を記述しています(ここで予測モデルについてだけ話すとすれば)。
解答にディープラーニングを選択されていますが、最適な手法なのでしょうか?
ここでは、アルゴリズムの選択について簡単に雑談し、その後のコンテンツでは、ディープラーニングの効果を高める方法について具体的に説明します。
ここでは、その概要を説明します。
- アルゴリズムのフィルタリング
- 文献から学ぶ
- リサンプリングの方法
一行ずつ展開していく。
1) アルゴリズムのフィルタリング
どのアルゴリズムが自分の問題に対して最適なのか、事前に知ることはできません。
もし、すでに分かっていたら、機械学習は必要ないでしょう。
今すでに使っているアプローチがベストな選択であるという根拠は何ですか?
この難問について考えてみましょう。
すべての可能な問題に対して有効性を判断した場合、どのアルゴリズムも他のアルゴリズムより優れているとは言えません。すべてのアルゴリズムが同等である。ここで
タダ飯はない説
その要点は
あなたが選んだアルゴリズムが、あなたの問題に最適でないのかもしれません。
さて、私たちはすべての問題を解決できるとは思っていませんが、現在人気のあるアルゴリズムが、あなたのデータセットに適しているとは限りません。
私のアドバイスは、あなたの問題に適したアルゴリズムが他にあることをまず前提に、証拠を集めることです。
一般的なアルゴリズムをふるいにかけて、その中から該当するものをいくつかピックアップしてください。
- ロジスティック回帰や線形判別分析などの線形アルゴリズムを試してみよう
- CART、ランダムフォレスト、gradient boostingなどの木モデルを試す。
- SVMやkNNのようなアルゴリズムを試してみる
- LVQ、MLP、CNN、LSTMなど、他のニューラルネットワークモデルを試す。
より良く機能するものを選び、パラメータやデータを細かく調整することで、さらに結果を向上させることができます。
あなたが選んだディープラーニングの手法を、上記のこれらの手法と比較して、勝てるかどうか試してみてください。
もしかしたら、ディープラーニングモデルをやめて、よりシンプルで学習速度が速く、理解しやすいモデルを選ぶこともできるかもしれません。
関連する読み物
2) 文献から学ぶ
近道は、文献からアイデアを盗むことです。
他の人があなたと似たような問題をやったことがあるか、どんな方法を使ったか。
論文、書籍、Q&Aサイト、チュートリアル、Googleが提供するあらゆるものを読んでください。
すべてのアイデアを書き留め、その線に沿って探求し続ける。
これは繰り返し勉強するのではなく、新しいアイデアを発見してもらうためのものです。
すでに発表されている論文を優先する
すでに多くの賢い人々が、多くの興味深い事柄について書いています。この貴重なリソースを活用しましょう。
関連する読み物
3)リサンプリングの方法
モデルがどの程度機能するかを理解する必要があります。
モデルの有効性の推定は信頼できますか?
ディープラーニングモデルの学習には時間がかかる。
つまり、k-foldクロスバリデーションのような、モデルの有効性を判断するための標準的な黄金律が使えないのです。
- おそらく、データをトレーニングセットとテストセットに単純に分割するのでしょう。その場合、分割後のデータの分布が同じであることを確認する必要があります。一変量統計とデータの可視化は、これを行うための良い方法です。
- もしかしたら、ハードウェアを拡張して、結果を改善できるかもしれません。例えば、クラスターやAWSのアカウントがあれば、n個のモデルを並列に学習させ、その平均値と分散を選択することで、より一貫した結果を得ることができます。
- おそらく、データの一部を選択してクロスバリデーションを行うことも可能でしょう(Early Stoppingに非常に有効)。
- モデル検証のために、データの一部を完全に独立させることができるかもしれません。
一方、データセットを小さくして、より強力なリサンプリング手法を用いることも可能である。
- おそらく、サンプルデータセットで学習させたモデルの結果と、フルデータセットで学習させた結果の間に強い相関があることが分かると思います。その場合、小規模なデータセットをモデル選択に使用し、最終的に選択した手法を完全なデータセットに適用することができる。
- おそらく、データセットのサイズを任意に制限し、データの一部をサンプリングし、それらをすべての学習タスクに使用することも可能でしょう。
モデルの効果予測に全幅の信頼を置いていること。
関連する読み物
3. アルゴリズムチューニングによる性能向上
フィルタリングすることで、常に1つか2つのうまくいくアルゴリズムを見つけることができることが多い。しかし、そのアルゴリズムの中からベストなものを見つけ出すには、何日も、何週間も、あるいは何ヶ月もかかります。
ここでは、リファレンスをチューニングする際に、アルゴリズムの性能を向上させるためのアイデアを紹介します。
- モデルの診断可能性
- 重みの初期化
- 学習率
- 活性化関数
- ネットワーク構造
- バッチとエポック
- レギュラーアイテム
- 最適化目標
- トレーニングの早期終了
最も効果が期待できるパラメータセットを得るために、複数回(3~10回以上)モデルを学習するパラメータを指定する必要がある場合があります。各パラメータについて、繰り返し試してみてください。
ハイパーパラメータの最適化については、以下のブログが参考になります。
1) 診断可能性
モデルの性能が向上しなくなった原因を知ることで、初めて最良の結果を得ることができます。
モデルがオーバーフィットしているからなのか、アンダーフィットしているからなのか。
この質問を常に念頭に置いてください。決して
モデルは、程度の差こそあれ、常にこの2つの状態の間にあるのです。
モデルの性能を素早く確認する一つの方法は、各ステップにおけるトレーニングセットとバリデーションセットでのモデルの性能を計算し、その結果をグラフ化することです。
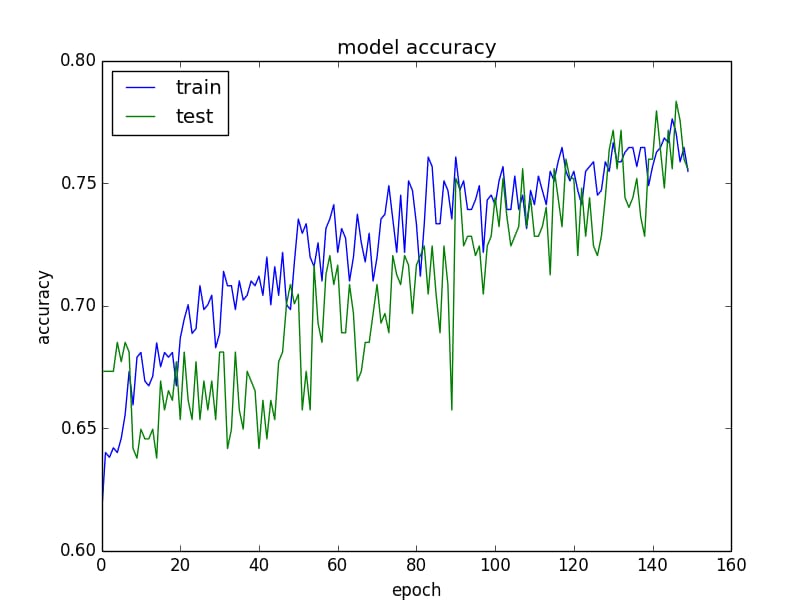
トレーニングセットとバリデーションセットでモデルの精度をテストする
- トレーニングセットがバリデーションセットよりも優れている場合、オーバーフィットの可能性があるので、正規の項を追加してみてください。
- トレーニングセットとバリデーションセットの両方の精度が低く、アンダーフィットの可能性があることを示す場合、モデルの改良を続け、トレーニングステップを延長することができます。
- トレーニングカーブとバリデーションカーブに焦点がある場合、Early Stoppingトリックを使用する必要があるかもしれません。
モデルの性能を向上させるための様々なアプローチを掘り下げ、比較するために、同様のグラフを頻繁にプロットする。
これらのグラフは、最も貴重な診断ツールになるかもしれません。
もう一つの効果的な診断方法は、モデルが正しく予測したもの、あるいは間違って予測したものをサンプルとして研究することです。
シナリオによっては、この方法によってアイデアが得られることもあります。
- 予測しにくいサンプルデータがもっと必要な場合がある
- 学習しやすいサンプルをトレーニングセットから取り除くことができるかもしれない
- 異なるタイプの入力データに対して、異なるモデルをターゲットにすることができるかもしれない
関連する読み物
2) 重みの初期化
経験則として、重みは小さい乱数で初期化することがあります。
実際、これで十分かもしれません。しかし、あなたのネットワーク・モデルにとって、これは最適な選択なのでしょうか?
活性化関数の違いによって応答戦略も変わってきますが、実際には大きな違いはなかったと記憶しています。
モデルの構造はそのままに、さまざまな初期化戦略を試してみてください。
重み値はモデルが学習する必要のあるパラメータであることを忘れないでください。いくつかの異なる重み値のセットで良い結果を得ることができますが、より良い結果を得たいと思うはずです。
- すべての初期化方法を試し、最適な初期化値のセットを見つける。
- 自動コーダーのような教師なし手法で事前学習を試してみる
- 既存のモデルのウェイトパラメータセットを使って、入力層と出力層を再トレーニングしてみる(移動学習)。
重みの初期化値を変更することは、活性化関数や目標関数を変更することと同等であることを忘れないでください。
関連する読み物
3)学習率
また、学習率を調整することで、成果の向上につながることもあります。
こちらも、いくつかのアイデアをご紹介します。
- 非常に大きな学習率、非常に小さな学習率を試す
- リファレンスに沿った規則正しい値を中心に格子状に探索する
- 学習率を小さくしてみる
- 学習ステップの間隔を一定にして学習速度を減少させてみる
- ベクトル値を追加して、グリッドで検索してみる
ネットワークモデルが大きくなると、より多くの学習ステップが必要になり、またその逆も然りです。ニューラル・ノードやネットワーク層を増やせば、学習速度も上がります。
学習率は、学習ステップ、バッチサイズ、最適化方法と連動している。
関連する読み物
4) 活性化関数
ReLU活性化関数にした方がいいかもしれませんね。
単純に、その方がうまくいくからです。
ReLUの前にシグモイドとtanhが流行し、その後、出力層にソフトマックス、リニア、シグモイド関数が使われるようになりました。それ以外の選択肢を試すのはお勧めしません。
入力データをその値の範囲に正規化することを忘れずに、3つの関数をすべて試してみてください。
当然のことながら、出力内容の形式に基づいて伝達関数を選択する必要があります。
例えば、2値分類のシグモイド関数を回帰問題の線形関数に変更し、出力値を再処理するとしよう。また、適切な損失関数を調整する必要がある場合もある。データ変換のセクションでより多くのアイデアを探してきてください。
関連する読み物
5) ネットワークトポロジー
ネットワークのトポロジーを調整することも、少しは効果があります。
設計に必要なノードの数、ネットワークの層数を教えてください。
詮索しないでください、何人いるかは地獄が知っています。
自分で設定するための合理的なパラメータを見つけなければならないのです。
- 多くのノードを持つ隠れ層を追加してみる(ワイド化)
- 1層あたりのノード数を減らしたディープニューラルネットワークを試してみる(縦深)
- 上記2つを組み合わせてみる
- 最近発表された同様の問題を持つ論文を模倣してみる
- トポロジカルモデルや書籍に載っている古典的なテクニックを試す(下記リンク参照)
これはパズルですね。ネットワークモデルは大きければ大きいほど表現力が豊かになるので、もしかしたら、まさにそのようなものが必要かもしれません。
より朝の構造が、抽象的な機能のより構造化された組み合わせの可能性を提供し、多分あなたはそのようなネットワークも必要とします。
後のネットワークモデルは、より多くの学習過程を必要とし、学習ステップと学習速度を常に調整する必要がある。
関連する読み物
以下のリンクは、何かのヒントになるかもしれません。
6) バッチとエポック
バッチのサイズは、勾配値と、重みの更新頻度を決定します。エポックとは、トレーニングセット内のすべてのサンプルが、バッチ順に1ラウンドのトレーニングに参加することを意味します。
バッチサイズやエポック数を変えて試してみましたか?
前回は、学習率、ネットワークサイズ、エポック数の関係について説明しました。
ディープラーニングモデルは、小バッチで大きなエポックと多くの反復で学習させるのが一般的です。
これは、あなたの問題に役立つかもしれません。
- バッチサイズをフルトレーニングセットのサイズに設定してみる(バッチ学習)
- バッチサイズを1にしてみる(オンライン学習)
- グリッドサーチでミニバッチのサイズを変えてみる (8, 16, 32, ...)
- さらに数エポック学習し、さらに数エポック学習を継続する。
無限に近いエポック数を設定し、中間結果をスナップショットして、最適なモデルを探してみてください。
モデル構造によっては、バッチのサイズに敏感なものもあります。多層パーセプトロンはバッチサイズに非常に鈍感で、LSTMとCNNは非常に敏感だと思いますが、すべて慈悲深いものです。
関連する読み物
7) 正規の項
正則化は、学習データのオーバーフィットを克服する良い方法である。
最近人気の正則化手法にドロップアウトがありますが、試されたことはありますか?
ドロップアウト法は、学習中に一部のニューラルノードをランダムにスキップし、同じレイヤーの他のノードに引き継がせる方法です。シンプルだが効果的な方法だ。
- 大きな重み値にペナルティを与えるための重み減衰
- 大きな活性化関数値にペナルティを課すための活性化制限
L1、L2、2つの合計など、様々なペナルティやペナルティ項を試してみてください。
関連する読み物
8) 最適化手法と損失関数
従来は確率的勾配降下法が主な解法であったが、多くのオプティマイザが存在する。
さまざまな最適化策を試されましたか?
Stochastic gradient descentはデフォルトの方法です。まずこれを使用して結果を出し、その後、さまざまな学習率や運動量の値を調整し、最適化を行います。
より高度な最適化手法の多くは、より多くのパラメータを使用し、より複雑な構造を持ち、より速く収束します。問題によって、それぞれにメリットとデメリットがあるのでしょう。
既存の手法からより多くの可能性を引き出すには、各パラメータを掘り下げ、グリッドサーチ手法でさまざまなフェッチをテストする必要があります。この作業は大変で時間がかかりますが、やってみる価値はあります。
新しい/人気のあるメソッドは収束が早く、与えられたネットワークトポロジーの可能性を素早く理解することができますね、例:。
- ADAM
- RMSprop
また、より伝統的なアルゴリズム(Levenberg-Marquardt)や比較的新しいアルゴリズム(genetic algorithms)など、他の最適化アルゴリズムも検討することができます。他の方法は、SGD の良いスタートを作り、その後のチューニングを容易にすることができます。
そして、最適化される損失関数は、解くべき問題により関連性の高いものとなります。
しかし、一般的なトリック(例えば回帰問題ではMSEやMAEがよく使われる)もあり、損失関数を変更することで思わぬ利益が得られることもあります。この場合も、入力データの規模や使用する活性化関数が関係している可能性があります。
関連する読み物
9) アーリー・ストッピング
モデルのパフォーマンスが低下し始めたら、トレーニングを停止することができます。
これにより、多くの時間を節約できるため、おそらくより細かいリサンプリング手法を使ってモデルを評価することができるようになります。
早期停止は、データのオーバーフィットを防ぐための正則化手法でもあり、各トレーニングラウンドの終了時に、トレーニングセットとバリデーションセットでモデルがどの程度うまく機能しているかを観察する必要があります。
検証セットでのモデルの効果が落ちたら、学習を停止することができる。
また、チェックポイントを設定して、その時の状態を保存しておけば、モデルの学習を継続することができます。
関連する読み物
4. フュージョンで効果アップ
複数のモデルからの予測を融合させることができます。
モデルチューニングに続いて、これも大きな改善点です。
実際、細かく調整された複数のモデルが別々に予測するよりも、問題なく動作する複数のモデルの予測を融合させた方が良い結果を得られることが多いのです。
モデルフュージョンの主な3つの方向性を見てみましょう。
- モデルフュージョン
- パースペクティブフュージョン
- スタッキング
1)モデルフュージョン
モデルを選ぶのではなく、統合することが必要である。
複数のディープラーニングモデルを学習させ、それぞれが良い結果を出した場合、それらの予測値の平均をとります。
モデルの分散が大きければ大きいほど、良い結果が得られます。例として、大きく異なるネットワークトポロジーやテクニックを使用することができます。
各モデルが独立して有効であれば、統合された結果はより一貫性のあるものになります。
逆に、その逆の実験もできます。
ネットワークモデルの学習は、毎回異なる初期化を行い、最終的な重みの収束値も異なる。この作業を複数回繰り返して、複数のネットワークモデルを生成し、それらのモデルからの予測値を統合します。
その予測は高い相関を持つだろうが、おそらくより困難なサンプルに対しては少しブーストがかかるだろう。
関連する読み物
2)パースペクティブフュージョン
前項で述べたように、別の視点でモデルを学習させたり、問題を彫り直したりします。
私たちの目標は、依然として有用なモデルを得ることですが、異なる方法(例えば、相関のない予測結果)で得ることです。
上記のようなアプローチから、学習データに対して全く別のスケーリングや変換の手法をとることができます。
選択したバリエーションと問題描写の角度の差が大きければ大きいほど、結果が改善される可能性が高くなります。
予測された結果を単純に平均化するのも良い方法です。
3)スタッキング
また、個々のモデルの予測値をブレンドする方法も学ぶことができます。
これは積層汎化、または単に積層と呼ばれるものです。
通常、個々のモデルの予測値の重みは、単純な線形回帰の方法で学習することができる。
個々のモデルの予測値の平均をとる方法をベースラインとし、重みをつけた融合を実験グループとする。
概要
人それぞれ
追加情報
また、非常に良い情報もありますが、この記事ほど包括的ではありません。
以下にいくつかのソースと関連記事を挙げておきますので、ご興味のある方は深く読んでみてください。
- ニューラルネットワークFAQ
- グリッドサーチ法を用いたディープラーニングモデルのハイパーパラメータの解法
- ディープニューラルネットワークのための必携のヒント
- ディープニューラルネットワークの検証精度を向上させる方法とは?
他に良いリソースをご存知でしたら、お気軽にコメントを残してください。
関連
-
許容メモリサイズは134217728バイトで、問題は解決された php
-
[UE4公式ドキュメント翻訳】Unreal Engine 4 For Unity Developers (UE4、ユニティデベロッパーズ向け)
-
アセンブリノート No.2 - jnz (または jz ) を実行するためにテストを使用する方法
-
intellij idea 登録コードアクティベーションコード手順を入力する
-
リクエストの処理中に処理されない例外が発生した
-
ansible error resolution:UNREACHABLE sshでホストへの接続に失敗しました。
-
子コンテナが起動中に失敗した エラーが解決
-
削除ポップアップボックス
-
ファイル、アセンブリ、またはその依存関係のいずれかを読み込むことができませんでした。不正確なフォーマットのプログラムをロードしようとしました。
-
cygwin many commands show command not foundの解決策。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
unity build when エラー
-
エラーです。Cannot find module '@vue/cli-plugin-babel'.
-
error: 単項「*」の型引数が無効です(「int」を持つ) *__first = __tmp.
-
コンパイル時の型エラーでメソッドが未定義になる
-
Universal Recovery Masterの見つけ方と完全な削除方法
-
vsftpでディレクトリが変更できない問題の解決法
-
Android SpinnerAdapterの使用
-
Android Studio FAQ -- AndroidManifest.xml のカバレッジに関する問題
-
SSHログインプロンプトの解決策:接続が拒否されました。
-
日付書式yyyy-MM-ddとYYYY-MM-ddの違いは何ですか?