ユニークSQLの原理と応用を解説
1. ユニークSQLとは?
ユーザーがSQL文を実行すると、各SQL文のテキストはパーサーに入り、"パースツリー"が生成されます。その整数値をUnique SQL IDといい、同じUnique SQL IDを持つSQL文は同じ"Unique SQL"に属します。
例えば、次の2つのSQL文を順番に入力するとします。
select * from t1 where id = 1;
select * from t1 where id = 2;
解析結果のトポロジーが同じなので、固有SQLのIDも同じになります。したがって、以下のように両方の文は同じUnique SQLに属します。
select * from t1 where id = ? ;
GaussDBカーネルは、上記のすべての形式のSQL文の統計情報を集約し、ビューを通じてユーザーに提示します。このようにして、いくつかの無関係な定数値の干渉を除外し、特定のクラスのSQL文の統計情報を得ることができ、性能分析や問題の局所化のための数値的な根拠を提供することができます。
Unique SQL IDの計算では、定数値のみが除外され、他の分散は除外されないことに注意してください。例えば、 "select * from t2 where id = 1;" というSQL文は、上記のSQLと同じUnique SQLには含まれませんし、異なるユーザー、異なるCNノードから実行された同じSQL文は、同じUnique SQLの一部には含まれません。
2. ユニークSQLのカウント方法
SQLリクエストを受信すると、GaussDBカーネルはまずそのUnique SQL IDを計算します。Unique SQL IDがすでに存在する場合、関連統計情報を直接更新します。もしIDが存在しない場合は、以下のようにUnique SQLを作成し、統計情報を更新します。
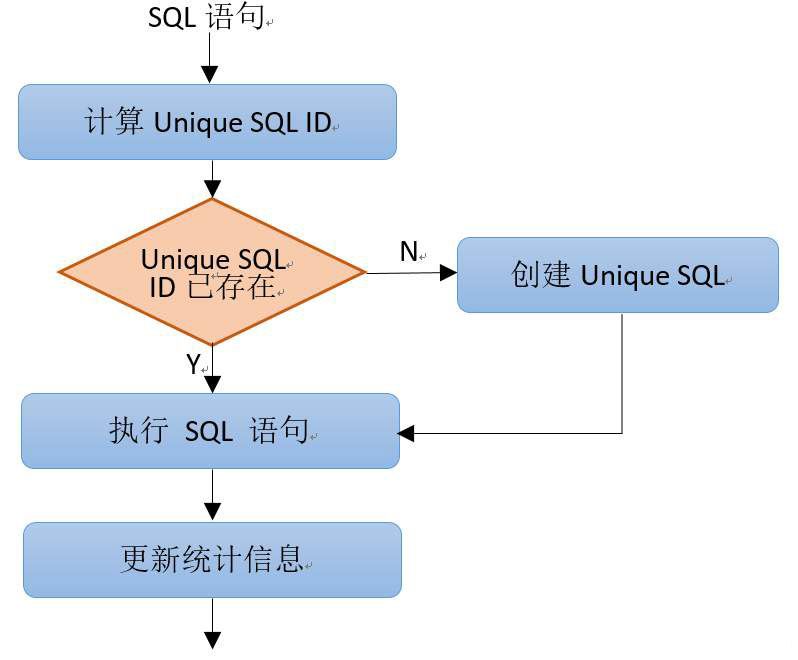
実行回数、応答時間、Cache/IO 数、行数、時間分布などの情報を含むユニークな SQL 統計は、以下の 2 つのビューで照会できます。
- gs_instr_unique_sql
- pgxc_instr_unique_sql
前者は現在のCN(Coordinator Node)ノード(現在のSQLコマンドを実行するノード)のUnique SQL情報を表示し、後者はシステム内の全CNノードのUnique SQL情報を表示します。どちらのビューも同じフォーマットで、以下のテーブルのフィールドで構成されています。

3. ユニークなSQLの使い方
Unique SQL機能を使用するためには、以下の変数スイッチをONにする必要があります。
- enable_resource_check (デフォルトはon)
- track_counts (デフォルトはオン。行のアクティビティとCache/IO関連フィールドに影響します)
また、instr_unique_sql_countに正の整数を設定する必要があります。この変数はデフォルトで0であり、gsqlセッションで変更することはできません。
gs_guc reload -Z coordinator -D /path/to/coordinator1/ -c "instr_unique_sql_count=20" > /dev/null
instr_unique_sql_countパラメータは、システムによって収集されるユニークなSQLの数を決定します。収集されたユニーク数がこの数に達すると、新しいsqlは収集されなくなります。この値を大きくすると、元のユニークSQL情報が保持され、新しいユニークSQLの収集が始まります。この値を小さくすると、現在のCNノードに対して収集されたすべてのユニークSQL情報がクリアされ、新しいユニークSQLの収集が始まります。
上記の変数を設定すると、Unique sql statisticsビューは、通常のビューのように、例えば、次のように問い合わせることができます。
postgres=# select node_name,query,n_calls from pgxc_instr_unique_sql;
node_name | query | n_calls
--------------+------------------------------------------------------------+---------
coordinator2 | select node_name,query,n_calls from pgxc_instr_unique_sql; | 0
(1 row)
システム関数reset_instr_unique_sqlは、ユニークSQL情報をクリーンアップするもので、以下の意味を持つ3つの引数を持つ。
1.スコープ:"GLOBAL"であれば、すべてのCNノードのデータをクリアし、"LOCAL"であれば、現在のCNのデータのみをクリアする。
2. タイプ: "ALL" ならば全てのデータをクリアし、"BY_USERID" ならば指定したユーザーの固有SQLのみをクリアし、"BY_CNID" ならば指定した CNの固有SQLのみをクリアします。SQLです。
3. 値:type="ALL"の場合、このパラメータは無意味です。type="BY_USERID"の場合、このパラメータは指定したユーザーのIDです。type="BY_CNID"の場合、このパラメータは指定したCNのIDになります。
例
postgres=# select reset_instr_unique_sql('global','all',0);
reset_instr_unique_sql
------------------------
t
(1 row)
また、データベースプロセスを再起動すると、それまでに収集した固有SQL情報もクリアされることになります。
4、問題箇所を特定するためのユニークなSQL
ユニークなSQLビューは、ユーザーが必要に応じて使用し、有用な情報を選択することができる豊富な情報を提供します。このセクションでは、お客様が実稼働環境で遭遇する実際の状況において、パフォーマンスの最適化のためにこのビューを使用するいくつかの方法を例示しています。
4.1 異常な行の動きによるディスクの競合を調べるクエリ
行の異常な動きはディスクの競合を引き起こし、業務に遅れをもたらす可能性があります。スキャンされた行数、返された関数、変更された行数、およびその他の指標の変動を調べることで、異常な行の動作を特定し、原因を突き止めることができます。
postgres=# select sum(n_returned_rows) n_returned_rows, sum(n_tuples_fetched) n_tuples_fetched,
sum(n_tuples_returned) n_tuples_returned, sum(n_tuples_inserted) n_tuples_inserted,
sum(n_tuples_updated) n_tuples_updated, sum(n_tuples_deleted) n_tuples_deleted from pgxc_instr_unique_sql;
n_returned_rows | n_tuples_fetched | n_tuples_returned | n_tuples_inserted | n_tuples_updated | n_tuples_deleted
-----------------+------------------+-------------------+-------------------+------------------+------------------+------------------
234 | 0 | 0 | 0 | 0 | 0
(1 row)
4.2 リソースの使用状況をトップSQLに問い合わせる
ユニークSQLビューのSQL文は、実行時間、CPU時間、スキャン行数、物理リード/論理リードなどを基準にソートして、最もリソースを消費するSQL文を見つけ出し、そのパフォーマンスへの影響や原因をターゲットにして、問題の発見と特定を支援することができます。例えば
SQLの実行時間順、または逆順でソートします。
SELECT user_name, unique_sql_id, query, total_elapse_time FROM pgxc_instr_unique_sql ORDER BY total_elapse_time ASC or DESC;
SQLの実行によって消費されたCPU時間を、順次または逆順にソートします。
SELECT user_name, unique_sql_id, query, cpu_time FROM pgxc_instr_unique_sql ORDER BY cpu_time ASC or DESC;
SQL順、スキャン行順、逆順でソートします。
SELECT user_name, unique_sql_id, query, n_tuples_returned FROM pgxc_instr_unique_sql ORDER BY n_tuples_returned ASC or DESC;
SQLスキャンされた総行数の多い順に並べ替えるか、逆順に並べ替えてください。
SELECT user_name, unique_sql_id, query, n_tuples_fetched + n_tuples_returned FROM pgxc_instr_unique_sql ORDER BY n_tuples_fetched + n_tuples_ returned ASC or DESC.ユーザ名とクエリ番号、クエリ番号、n_uples_fetched + n_tuples_returnedを指定します。
SQL実行時間順にソート、または逆順にソートします。
SELECT user_name, unique_sql_id, query, execution_time FROM pgxc_instr_unique_sql ORDER BY execution_time ASC or DESC;
SQL実行の物理的な読み込み順または逆順にソートします。
SELECT user_name, unique_sql_id, query, n_blocks_fetched FROM pgxc_instr_unique_sql ORDER BY n_blocks_fetched ASC or DESC;
SQL実行の論理読み込み順、または逆順にソートします。
SELECT user_name, unique_sql_id, query, n_blocks_hit FROM pgxc_instr_unique_sql ORDER BY n_blocks_hit ASC or DESC;
4.3 論理的読み取り/物理的読み取り回数の問い合わせ
論理読み込み/物理読み込みが多すぎると、SQL文のCPU時間がより長くかかる場合があります。SQLステートメントの論理リード/物理リードブロック数は、ユニークなSQLビューを照会することで取得でき、レスポンス低下の原因究明の一助とすることができます。
物理的な読み取りブロック数を問い合わせる。
SELECT n_blocks_fetched FROM pgxc_instr_unique_sql;
論理的な読み取りブロックの数を問い合わせます。
SELECT n_blocks_hit FROM pgxc_instr_unique_sql;
4.4 メモリクォータ不足による低パフォーマンスの診断
データベースバッファが小さく設定されていると、各SQL文の実行結果をキャッシュすることができず、現在のSQLの実行が終了した後、別のSQLの実行があった場合、メモリ上に前回または数回のSQLキャッシュ実行結果を絞り込み、次のラウンドで現在のSQLを再度実行すると、キャッシュから直接データを取得せず、ディスクからデータを読み出して物理IOする必要があります。この結果、SQLの実行性能が低下します。
バッファークォータが十分に大きいかどうかは、ヒット率で判断することができます。バッファヒット率 = n_blocks_hit/n_blocks_fetched であり、ユニークSQLを照会してメモリクォータが不足しているかどうかを診断することができます。
SELECT (n_blocks_hit/ n_blocks_fetched) AS hit_ratio from pgxc_instr_unique_sql.SELECT (n_blocks_hit/ n_blocks_fetched) AS Hit_ratio from pgxc_instr_unique_sql;
以上、Unique SQLの原理と応用について詳しく説明しましたが、Unique SQLの原理と応用については、スクリプトハウスの他の関連記事にもご注目ください。
関連
-
DataGripでクリックハウスの時間フィールドが正しく表示されない
-
データベースシステムの構造詳細説明 3レベルのスキーマ構造
-
gaussDBデータベース共通操作コマンド詳細
-
Navicat sqlファイルのインポートとエクスポートを素早く行う方法
-
SQLyogダウンロード、インストール超詳細チュートリアル(プロテスト永久保存版)
-
Navicat Premium 15データベース接続フラッシュバックの問題を解決する
-
NavicatでMySqlデータベースへの接続が遅い問題
-
SQLリレーショナルモデルの知識まとめ
-
タイプインジェクションとコミットインジェクションのSQLインジェクションチュートリアル
-
SQLにおけるwhereとhavingの違いについて解説します
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Navicat 15アクティベーションチュートリアル
-
ツリー構造データベースのテーブルのスキーマ設計のための2つのオプション
-
JetBrains DataGripのインストールと使用に関する詳細なチュートリアル
-
Linuxシステム用Navicatアクティベーションチュートリアル
-
DeepinV20 Mariadbのクイックインストールを詳しくご紹介します。
-
Navicat for Mac システムチュートリアルのインストールと使用方法
-
Dbeaverを使ったHiveへのリモート接続の詳細方法
-
データベース管理ツール「Navicat」と「DBeaver」を一挙に読む
-
Navicat Premium 12でOracleに接続する際にoracle library is not loadedと表示される問題の解決
-
SQLインジェクションについて詳しく話すいくつかの散在する知識のポイント