[解決済み] ShuffledRDD、MapPartitionsRDD、ParallelCollectionRDDの違いは何ですか?
2022-03-04 18:27:39
質問
Spark RDDを生成するために2つの異なる方法を使用しています。そして、Spark UI DAGチャートの結果はかなり異なっています。
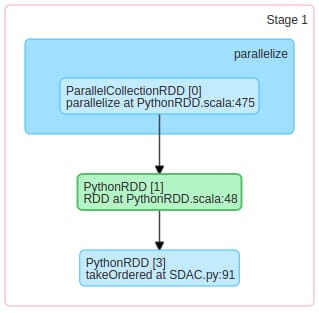
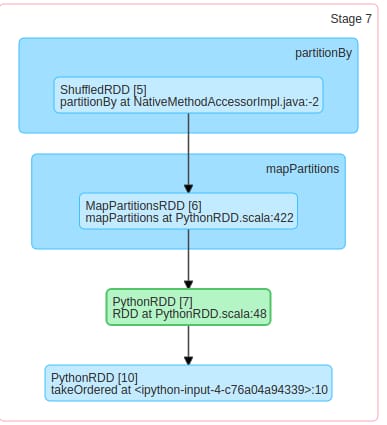
どなたか違いを教えてください。私の仕事では、同じような操作で1番目の方が2番目の方より速いのです。
どのように解決するのですか?
1ステージのDAGでは、単にコレクションでRDDを作成し、2番目のRDDでは、partitionByを使ってRDDをシャッフルして、データをクラスタ上でシャッフルしています。そのため、データをシャッフルするため、2ステージ目の処理が遅くなります。
との違い シャッフルRDD , MapPartitionsRDD と パラレルコレクションRDD :
シャッフルRDD : ShuffledRDDは、データがクラスタ上でシャッフルされる際に作成されます。データをシャッフルするような変換(join, groupBy, repartitionなど)を行うと、shuffledRDDが作成されます。
MapPartitionsRDD : MapPartitionsRDDは、mapPartition変換を使用するときに作成されます。
パラレルコレクションRDD
: ParallelCollectionRDDは、以下のように
RDD
をコレクション・オブジェクトとする。
もっと詳しく知りたい方は、こちらをご覧ください。 https://github.com/JerryLead/SparkInternals
関連
-
[解決済み] spark.sql.autoBroadcastJoinThresholdは、Datasetの結合演算子を使用して結合するために動作しますか?
-
[解決済み] スパーク "プランの文字列表現が大きすぎたため、切り捨てました。" 手動で作成した集計式を使用した場合の警告
-
[解決済み] Spark コンテキスト 'sc' が定義されていない
-
[解決済み] format("kafka") で "Failed to find data source: kafka." とエラーになるのはなぜですか?(uber-jarを使用しても)失敗しますか?
-
[解決済み] ShuffledRDD、MapPartitionsRDD、ParallelCollectionRDDの違いは何ですか?
-
[解決済み] スパークジョブとは?
-
[解決済み] spark checkpointとpersist to a diskの違いは何ですか?
-
[解決済み] Spark - repartition() vs coalesce()
-
[解決済み】SparkコンソールにINFOメッセージを表示させないようにするには?
-
[解決済み] 複数のテキストファイルを1つのRDDに読み込むには?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】spark.driver.maxResultSizeとは何ですか?
-
[解決済み] SparkでcreateOrReplaceTempViewはどのように動作するのですか?
-
[解決済み] PySparkのデータフレームで、各キーのパーセンタイルはどのように計算されますか?
-
[解決済み] Spark: 2つのDataFrameを減算する
-
[解決済み] sparkでsaveAsTextFileするときのファイル名の付け方は?
-
[解決済み] Sparkのバージョンを確認する方法【終了しました
-
[解決済み] プロパティspark.yarn.jars - どのようにそれに対処するのですか?
-
[解決済み】mapとflatMapの違いと、それぞれの良い使用例について教えてください。
-
[解決済み】Spark Dataframeで列の内容をすべて表示するにはどうすればよいですか?
-
[解決済み] 複数のテキストファイルを1つのRDDに読み込むには?