Longxinの新しい自律型命令セットの強みは何ですか?
今週の火曜日、CSDN の友人に応えて、NVIDIA の最初の CPU チップである Grace について記事を書きました。 インテルに呼びかけ、Nvidiaは"3つのコア"を揃えました。
人民日報に掲載されたNvidia初のCPUチップ「Grace」についての記事を書きましたが、その言葉が出る前にLongxinのニュースが発表されました。

しかし、私はLongcore 3を構築した物理的なホストを見たことがないので、読者の参考のためにLongcoreの公式資料から辛口の内容を解読してみるしかない。
MIPSがLongcoreに教えてくれたこと
Longcoreの命令セットLA64への新しい自律的な知識生産は、現在独自のスタイルを進化させていますが、LA64とMIPSの間の継承はまだ非常に明白です。 "キーアイデアは、ハードウェアロックを使用せずにパイプラインで問題を回避するためにソフトウェアアプローチを使用しようとすることである。また、今回のLongxinのイノベーションの1つは、遅延命令スロットの廃止ですが、提案された遅延スロットは、2、30年前はまだ非常に頼りにされていましたので、紹介します。
1981年、フォン・ノイマン賞とチューリング賞をダブル受賞したスタンフォード大学第10代学長ジョン・ヘネシー教授は世界初のMIPSアーキテクチャプロセッサを作り、現在ヘネシー教授はグーグルの親会社アルファベットの会長になり、業界からも認められるレベルの実力を持ち、あまり知られていませんが、インテルの現在のCEO、パットキッシンジャーは世界中に人がいることが長所といえます。このように、インテルは、その高い技術力により、世界的に高い評価を得ています。
MIPSが、世界で初めて合理化命令の考え方を実際に実践したプロセッサであることに異論はないだろう。MIPSを傘下に収めたRISC-Vが誕生したのは30年後の2010年、MIPSと30年間競合してきたARMが登場したのは4年後である。
MIPSは、まずプレイステーションに搭載され、その性能が高く評価されました。その後、ワークステーション、つまりサーバーに登場し、1997年のNECのスーパーコンピュータ「Cenju-4」は、MIPSを核とした非常に高度な設計が数多く採用された最高峰のものでした。

MIPSシリーズのチップの衝撃を受けて、インテルは2000年頃にサーバークラスCPUのItaniumシリーズのIntel Architecture 64アーキテクチャを打ち出しましたが、歴史的な理由でX86シリーズのCPUは常に下位互換性を保たなければならず、286用に書いたプログラムが486上で完全に動作しなければならなかったことが分かっています。X86シリーズのCPUは、様々なプロテクトモードとリアルモードを行き来することが多く、強い技術力がないと、X86のシステムがどのようにブート用にロードされているのかを理解することは非常に難しい。
しかし、Longcoreが宣伝資料で述べているように、Anthemアーキテクチャはこれまで失敗しており、同じ会社の命令セットが後方および前方互換性を持たないという結果は、破滅的なものだろう。そこで、LongXinはMIPSとの互換性をあきらめず、MIPS、Arm、X86のアプリケーションを、ネイティブプログラムの100%、90%、80%以上の性能を持つLongXin命令に翻訳することをサポートするバイナリ翻訳命令セットまで導入していることがわかる。
それを踏まえて、ここではLongXinの販促資料で公開されているアセンブリコードを用いて、対応するARMのコードと比較しながら、LongXinを詳しく見ていくことにしよう。
Longcore 64を間近で見る
このDragon Coreのリリース資料では、以下のコードが公開されています。
Int a;
Int test(void){
Return a;
}
対応するアセンブリ言語です。
Longcore命令セットの理解を深めるために、HuaweiのKunpengプラットフォームでARM版のgccを使って上記のコードをコンパイルしてみました。
1. まず、以下のように逆アセンブルツールobjdumpコマンドをインストールします。
yum install -y binutils
2. ソースファイル test.c に以下の入力を行ってください。
Int a;
Int test(void){
return a;
}
3. .a ライブラリファイルをコンパイルする
aarch64-redhat-linux-gcc -g -o test test.c
4. 対応するアセンブリファイルを表示する
objdump -S test
対応するコードは以下の通りです。
00000000 <test>:
int a;
int test(void)
{return a;}
0: e52db004 push {fp} ; (str fp, [sp, #-4]!)
4: e28db000 add fp, sp, #0
8: e59f3010 ldr r3, [pc, #16] ; 20 <test+0x20>
c: e5933000 ldr r3, [r3]
10: e1a00003 mov r0, r3
14: e28bd000 add sp, fp, #0
18: e49db004 pop {fp} ; (ldr fp, [sp], #4)
1c: e12fff1e bx lr
20: 00000000 .word 0x00000000
上記の大まかな処理をアセンブリ言語で解析すると、以下のようになります。
まずpush {fp} ; (str fp, [sp, #-4]!) SPはスタックレジスタで、まずfpにスタックの一番上のアドレス(sp-4)を渡し、fpをスタックに乗せます。次にfp, sp, #0を足してspをセットし、pcの後の16ビットアドレスにr3を渡してmov r0,r3 これはリターンaです。 add sp, fp, #0 and pop {fp} ; (ldr fp, [sp], #4) は実はスタックの先頭Zhen設定の逆、つまり呼び出し先が復元されていることになるのですが、その逆をやってみましょう。
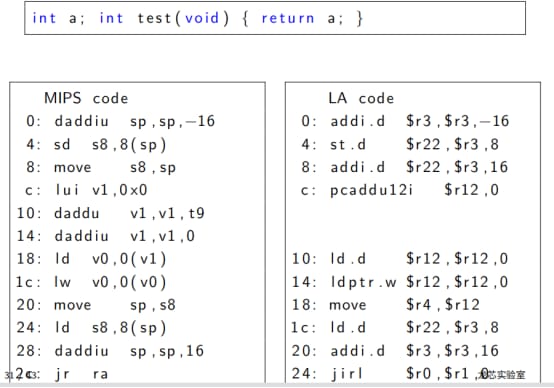
このcコードとドラゴンアセンブリ言語のコードは次のように対応する。
LAコード
0 : addi . d $r3 , $r3 ,-16
4 : s t . d $r22 , $r3 , 8
8 : addi . d $r22 , $r3 ,16
c : pcaddu12i $r12 , 0
10: l d . d $r12 , $r12 , 0
14: l d p t r .w $r12 , $r12 , 0
18: move $r4 , $r12
1c : l d . d $r22 , $r3 , 8
20: addi . d $r3 , $r3 ,16
24: j i r l $r0 , $r1 , 0
Longcoreの公式ドキュメントによると、R3レジスタはspレジスタ、R22はfpレジスタとなっています。つまり、その実装ロジックは、MIPS互換であると同時に、他のRISCスタイルの長所にとっても魅力的であると言えるのです。また、MIPSは将来のSIMDなど他の命令セットへの拡張に備え、命令空間には実に気を遣っている。
継承、最適化、アップグレード
Longcoreの紹介によると、RISCスタイルを維持したストレージ、利用可能なレジスタの増加など、その他の特徴は実物を見るまで評価が難しく、唯一言えるのは遅延命令スロットの廃止で、この点がより特徴的でしょうか。

遅延命令スロットの作成は、命令パイプラインから始まります。一般に、マシン命令を実行するには、フィンガーフェッチ、デコード、オペランドフェッチ、実行、演算結果のフェッチなど、タスクをいくつかのステップに分ける必要があり、それぞれのステップを進めるために水晶発振が必要で、パイプライン技術以前は、命令を実行するのに最低5~6サイクルの水晶発振が必要だったのですが......。

その後、このような問題のためにチップ設計者は、指をフェッチするため、工場パイプライン機構を参照するアイデアを思い付いた、これらのモジュールをデコードすると、実際に独立している、完了は、複数の命令の関連するステップが同じ瞬間に実行されている限り、その後、指、命令2デコード、命令3フェッチオペランドのようなステップで、同じ瞬間に実行されている命令1として。
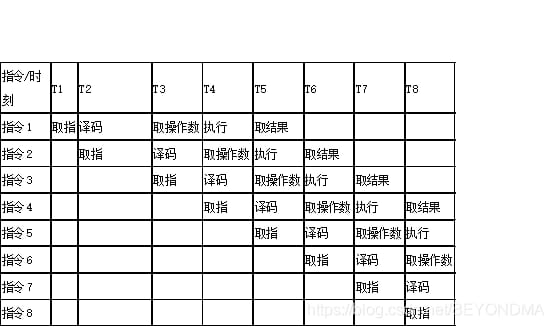
命令パイプラインが確立されると、それ以降は1発振周期Tごとに1命令の結果を取り出すことができるため、平均して1命令あたり1発の発振周期で完了することになる。これにより、CPUの演算速度を大幅に向上させることができる。しかし、この場合、CPUは各命令の実行順序を知る必要があり、パイプライン上の命令の実行順序を誤って予測した場合、次のように命令パイプライン上に大量のバブルが発生するという欠点がある。
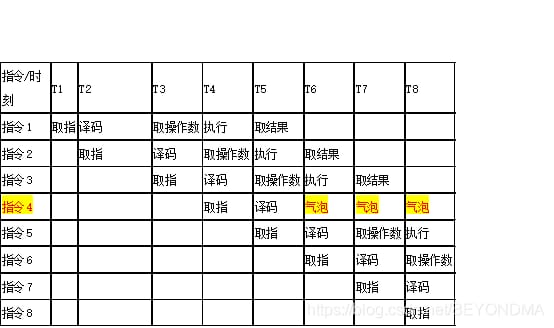
例えば、CPUが命令4を実行すべきでないことをT6の時点で知ると、T6からT8までの命令4に関する演算は泡のような無駄な演算となり、CPUの実行効率を極端に低下させることになる。
MIPSのディレイスロットが行っているのは、命令間の相関関係を分析し、命令をジャンプする際に判定ジャンプに影響されない実行命令を見つけることで、例えばint b=0とした以下のコードは、その後の条件判定に関係しない代表的なものである。
Int test(void){
Int b=0//conditionally jumping irrelevant code
If (a>0){
//Do some thing without b;
}
else{
//Do some thing else with out b;
}
MIPSでは、パイプラインをできるだけ遅延スロット命令で埋めて、バブルが増えすぎないようにしていますが、最近のCPUのソリューションでは、分岐予測がかなり進んでいることがわかります。c言語でも、like modifierを提供して、CPUの分岐予測を助けています。like modifierを使っても、ロジックは何も変わらず、この分岐は実行されそうだとCPUに伝えるだけになります。したがって、現在のディレイスロットは、すでにちょっとした無駄な動作になっている。Longcoreがこのピースを取り出すには、ちょうどいいタイミングなのです。
これらは、私が得られる重要な情報の一部であり、参考のために必ずしも正確ではありません。
関連
-
gitアップロードファイルのエラーを修正する方法 [rejected] master -> master (fetch first) error: failed to push some refs to '.
-
Pyproj のインストールに問題があり、コマンド ' cl.exe' が失敗しました。そのようなファイルやディレクトリはありません
-
python reports an error: 'list' object has no attribute 'shape'
-
sourceTree solution マージする前に、変更をコミットするか、隠しておいてください。
-
簡単な操作でprotobufのバージョンの問題を解決するために、コピーして貼り付けることができます。
-
test dword ptr [eax],eax ;プローブページです。
-
unity build はエラーを報告します。 名前 'XXX' は現在のコンテキストに存在しません。
-
关于Uncaught TypeError: Cannot read property 'toLowerCase' of undefined的问题
-
adb shell prompt device not foundについて
-
sql server の int から datetime への変換
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Uncaught SyntaxError: 位置1でJSONの予期しないトークンoは、問題が解決されました。
-
error unable to access jarfile Solution
-
socket.gaierror: [Errno 8] nodenameまたはservnameが提供されない、またはわからない
-
ページを開いてメソッドを呼び出した後 $(function() {}); Uncaught ReferenceError: ブラウザコンソールで $ が定義されていません。
-
python :TypeError: 'builtin_function_or_method' オブジェクトに '__getitem__' 属性がない。
-
"2021-01-30T16:00:00.000Z": 期待されるフォーマット "yyyy-MM-dd HH:mm:ss" タイムスタンプのフォーマット
-
mscorlib.dll で "TargetInvocationException" 型の例外が発生するが、ユーザーコードで処理されない
-
Application_Webservice の Global.asax ファイルの開始をトリガーすることはできません。
-
エラーの解決策 xmlのこの行に複数のアノテーションが見つかりました。
-
モジュール 'numpy' に 'array' 属性がない問題の解決