データフレームの基本
2022-02-10 03:43:41
空のDataFrameを初期化する
import pandas as pd
empty_df = pd.DataFrame(columns=['A','B','C','D'])
4つのカラムが作成され、それぞれのカラムには空のコンテンツがあります。

データサイズを表示する
1. 行数および列数
df.shape
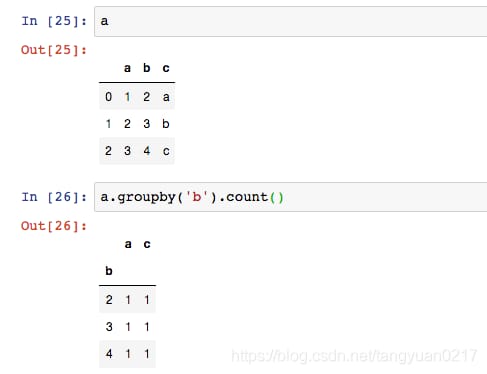
df.groupby('column_name').count()
a=pd.DataFrame({'a':[1,2,3],'b':[2,3,4]})
b=pd.DataFrame({'a':[11,22,33],'c':[22,33,44]})
c=pd.merge(a,b)
c
2. 特定の列名による統計
c=pd.merge(a,b,how='outer',on='a')
c
pd.concat(a,b)
# Horizontal stitching
pd.concat([a,b], axis=1)
# Vertical stitching
pd.concat([a,b], axis=0)
<イグ
DataFrameデータのスティッチング・マージ
pd.merge()
TypeError: first argument must be an iterable of pandas objects, you passed an object of type "DataFrame"
<イグ
同名のaリストとbリストはマージされますが、両方とも空です。これはデフォルトの結合形式が内側結合であること、つまり、両方ともデフォルトで同じカラム名をルックアップ条件として持ち、同じ値が見つからない場合はnullを返すことを表しています。
結合条件を追加する
pd.concat([a,b])
<イグ
pd.concat()
d=pd.concat([a,b])
d.index=list(range(0,6))
d
エラーの報告
e=pd.Series(list('abc'))
a['c']=e
a
a.join(b)
pandas.concat(a,b)をマージに使う場合、リスト形式にする必要があります。
ValueError: columns overlap but no suffix specified: Index(['a', 'c'], dtype='object')
<イグ
これは2つのテーブルa,bを完全に結合します。デフォルトの結合形式は連結ですが、パラメータを変更することで結合モードと結合方向を変更できますし、インデックスの再作成も可能です。

ウェイトの更新
inp = [{'c1':10, 'c2':100}, {'c1':11, 'c2':110}, {'c1':12, 'c2':123}]
df = pd.DataFrame(inp)
df
<イグ
課題
assignment文は、1列のデータのスティッチングを可能にします。
for index, row in df.iterrows():
print(index, row['c1'], row['c2'])
0 10 100
1 11 110
2 12 123
<イグ
データフレーム.join()
for row in df.itertuples():
print(getattr(row, 'c1'), getattr(row, 'c2'))
10 100
11 110
12 123
エラーを報告する。
for index, row in df.iteritems():
print(index, row[0], row[1], row[2])
c1 10 11 12
c2 100 110 123
<イグ
リストには、重複した名前を入れることはできません
DataFrameを行単位でトラバースする
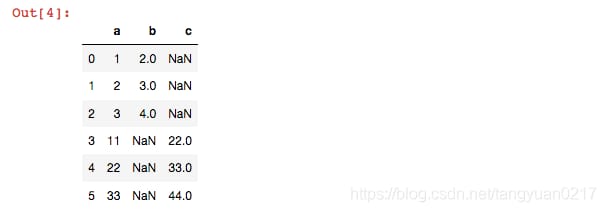
- iterrows(): DataFrameの各行を(index, Series)のペアとして反復処理し、要素のrow[name]でアクセスできるようにします。
- itertuples(): 行に対して反復処理する。DataFrame の各行を祖先として反復処理し、row[name] によって要素にアクセスする。iterrows() よりも効率的である。
- iteritems(): DataFrameを列単位で反復処理する。DataFrameの各列を(列名, Series)のペアとして反復処理し、row[index]を介して要素にアクセスすることができるようにする。
inp = [{'c1':10, 'c2':100}, {'c1':11, 'c2':110}, {'c1':12, 'c2':123}]
df = pd.DataFrame(inp)
df
<イグ
1. 行ごとの iterrows()
行['name']の
for index, row in df.iterrows():
print(index, row['c1'], row['c2'])
0 10 100
1 11 110
2 12 123
2. 行ごとの itertuples()
getattr(行, '名前')
for row in df.itertuples():
print(getattr(row, 'c1'), getattr(row, 'c2'))
10 100
11 110
12 123
3. 列ごとの iteritems()
行[インデックス]の
for index, row in df.iteritems():
print(index, row[0], row[1], row[2])
c1 10 11 12
c2 100 110 123
https://blog.csdn.net/sinat_29675423/article/details/87972498
DataFrameのインデックス
pandasはDataFrameのインデックスを作成するための特別なメソッドを提供しています。できれば、ラベルを使用している場合はlocメソッドを、添え字を使用している場合はilocメソッドを使用することをお勧めします。

関連
-
[解決済み】SyntaxError: デフォルト以外の引数がデフォルトの引数に続く
-
sklearn インターフェースがエラーを報告する Input contains NaN, infinity or value too large for dtype('float64')
-
[解決済み】__getitem__メソッドの理解
-
[解決済み] RuntimeError: モジュールは API バージョン 0xc に対してコンパイルされたが、numpy のこのバージョンは 0xb である。
-
[解決済み] Python リストの ndim 配列への再形成
-
[解決済み] グループ化されたPandasデータフレームをループオーバーする方法は?
-
[解決済み] CygwinでのPip-3.2のインストール
-
[解決済み] Flask がコンソールにプリントされない
-
[解決済み] 2つのファイルを比較し、共通する行を削除する
-
解決済みのエラーです。ModuleNotFoundError: tflite_runtime' という名前のモジュールはありません。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Pythonコンテナのための組み込み汎用関数操作
-
[解決済み] '_pywrap_tensorflow_internal' という名前のモジュールはありません。
-
[解決済み】Python: ValueErrorです。反復処理と読み込みメソッドを混在させるとデータが失われる
-
[解決済み】pytestでコンソールに印刷する方法は?
-
Python正規表現(推奨)
-
Pygame Timeコントロールの具体的な使用方法について説明します。
-
[解決済み] UnicodeDecodeError: 'ascii' コーデックはポジション 1 のバイト 0xef をデコードできません。
-
[解決済み] 'WSGIRequest' オブジェクトに 'user' 属性がない Django 管理者
-
python3 実行エラー。TypeError: タイプ 'type'のオブジェクトは、JSONシリアライザブルソリューションではありません。
-
TypeError: 'float' オブジェクトは整数として解釈できません。