Python正規表現(推奨)
1 序文
正規表現とは、通常の文字(aからzまでの文字)と特殊文字(メタ文字と呼ばれる)の文字列を、あらかじめ定義された特定の文字の集合とその組み合わせによって、quot;正規文字列として操作する論理式です。正規表現は、テキストを検索する際にマッチさせる1つまたは複数の文字列を記述したテキストパターンです。
上記は公式の説明ですが、ブログ管理人自身の理解(あくまで参考)では、いくつかの特殊文字のマッチングルールをあらかじめ指定しておき、その文字を組み合わせることで、様々な複雑な文字列のシナリオにマッチングさせるというものです。例えば、クローラーやデータ解析、文字列照合など、いずれも正規表現を使ってデータを処理する必要がある。
pythonの正規表現はreモジュールです。
- re モジュールは Python 言語に完全な正規表現の機能を与えます。 は、その
- また、reモジュールは、パターン文字列を第一引数とするこれらのメソッドと完全な互換性を持つ関数を提供します。
2 基本的な構文
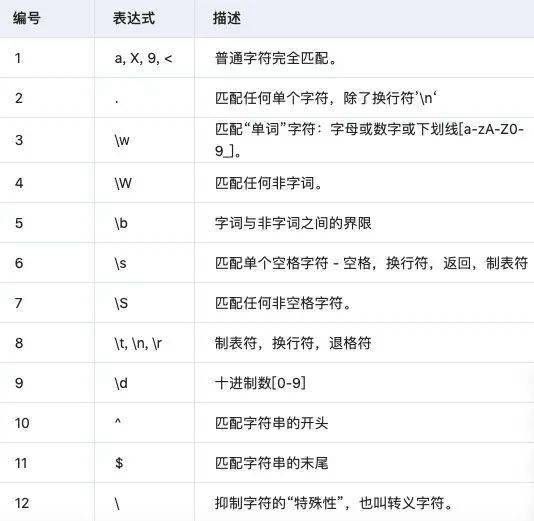
2.1 マッチ機能
以下は、文字列の先頭からのパターンのみにマッチする関数の構文である。
re.match(pattern, string, flags = 0)
以下は、パラメータの説明です。
- p attern - 一致させる正規表現です。
- string - これは、文字列の先頭でパターンにマッチするように検索される文字列です。
- flags - ビット単位のOR(|)で異なるフラグを指定することができる。これらは、以下の表に示すような修飾子である。
- re.match関数は、成功するとマッチを、失敗するとNoneを返します。オブジェクトのマッチにはmatch(num)関数またはgroups関数を使用して、マッチング式を取得します。

例
# 初期位置からマッチしない、Noneを返す import re line = 'i can speak good english' matchObj = re.match(r(w*)s(w*). *',line) if matchObj:print('matchObj.group :',matchObj.group)print('matchObj.group :',matchObj.group(1))print('matchObj.group :',matchObj.group(2))print('matchObj.group :',matchObj.group(3))else:print('no match!'))。

# match from initial positionimport re line = 'i can speak good english' matchObj = re.match(r'(i)s(w*)s(w*). *',line) if matchObj:print('matchObj.group :',matchObj.group)print('matchObj.group :',matchObj.group(1))print('matchObj.group :',matchObj.group(2))print('matchObj.group :',matchObj.group(3))else:print('no match!'))マッチしません。

2.2 検索機能
検索機能は、matchと同じように動作しますが、最初からマッチするのではなく、どの位置からでも最初にマッチするものを探します。この関数の構文は次のとおりです。
re.match(pattern, string, flags = 0)
以下は、パラメータの説明です。
- pattern - マッチする正規表現です。
- string - これは、文字列の先頭でパターンにマッチするように検索される文字列です。
- flags - ビット単位のOR(|)で異なるフラグを指定することができる。これらは、以下の表に示すような修飾子である。
- re.search関数は、成功すればマッチを返し、そうでなければNoneを返します。マッチした式を得るには、マッチオブジェクトのgroup(num)またはgroups関数を使用します。最後に、あなたの時間は非常にタイトではない、とすぐにパイソンを改善したい場合は、最も重要なことは、苦しむことを恐れていない、それはあなたがラックマイクロ♥文字をすることができますことをお勧めします。762459510 、その本当に良い、多くの人々が非常に迅速に進行し、あなたがああ苦しむことを恐れていない必要があります! 誰もが〜を参照してくださいに追加するために行くことができます。

例
import re line = 'I can speak good english' matchObj = re.search('(. ) (. ?) (. *)',line)if matchObj:print('matchObj.group :',matchObj.group)print('matchObj.group :',matchObj.group(1))print ('matchObj.group :',matchObj.group(2))print('matchObj.group :',matchObj.group(3))else:print('no match !')
2.3 サブ関数
正規表現のreモジュールを使う上で、最も重要なものの1つがsubです。
re.sub(pattern, repl, string, max=0)
このメソッドは、REパターンの文字列のすべての出現箇所をreplで置き換え、maxが提供されない限りすべての出現箇所を置き換えます。このメソッドは、変更された文字列を返します。
例
import re line = 'I can speak good english' speak = re.sub(r'can','not',line) print(speak) speak1 = re.sub(r's',',line) # すべてのスペースを置換する print(speak1)
3 特殊クラスの構文
3.1 文字クラス
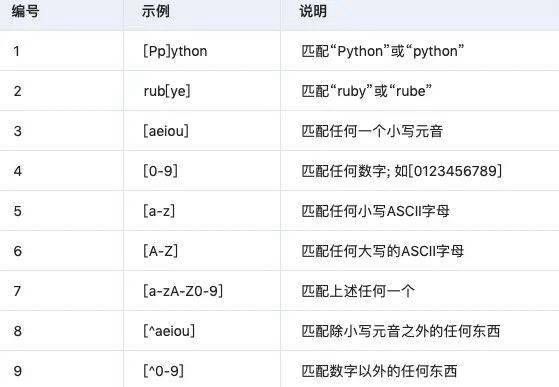
3.2 特殊文字クラス
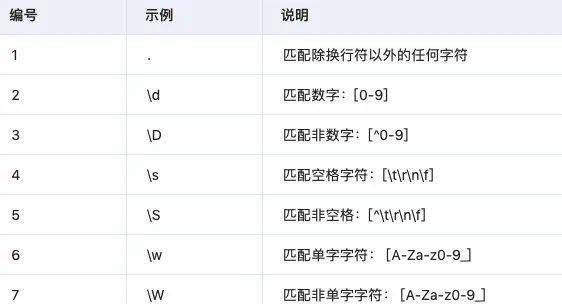
3.3 リピートマッチ
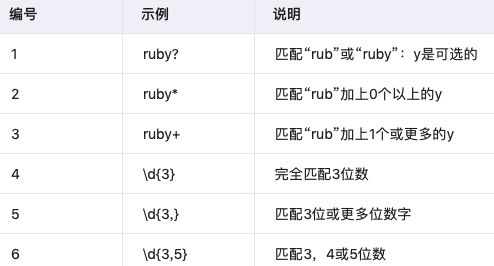
3.4 欲張らない繰り返し
最小限の繰り返し回数と一致します。
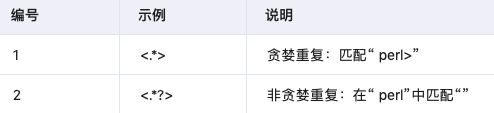
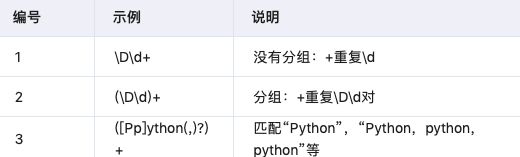
3.5 ラウンドブラケットグルーピング
3.6 逆引きリファレンス
以前にマッチングしたグループと再度マッチングする
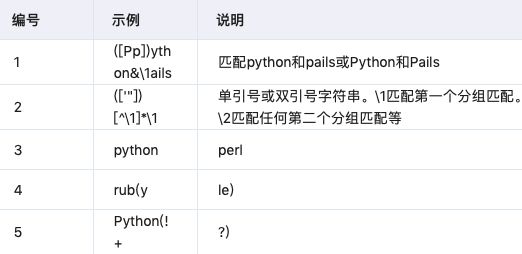
3.7 アンカーポイント
一致する位置を指定する必要がある。
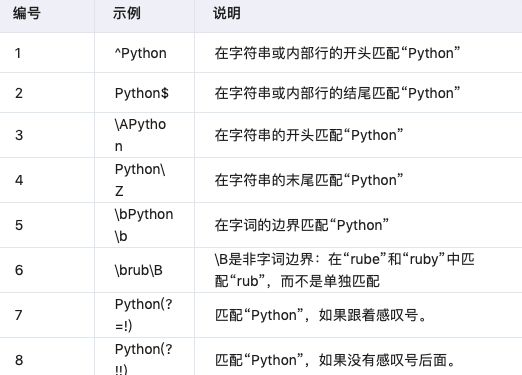
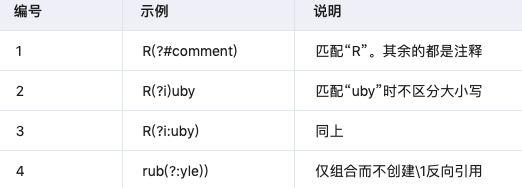
3.8 括弧を使った特殊な構文
Pythonの正規表現に関する記事は以上です。Python Regular Expressionsの詳細については、過去の記事を検索するか、引き続き以下の記事を参照してください。
関連
-
[解決済み】 AttributeError("'str' object has no attribute 'read'")
-
[解決済み】ImportError: libcuda.so.1: 共有オブジェクトファイルを開くことができない
-
[解決済み】setオブジェクトがJSONシリアライザブルでない【重複あり
-
[解決済み] Node.jsの依存性のためにWindowsでPythonを実行する
-
[解決済み] TypeError: 'zip' オブジェクトは添え字を付けることができません。
-
[解決済み] Matplotlibで散布図の点を線に接続する - Python
-
[解決済み] SyntaxError 無効なトークン
-
[解決済み] データフレームを複数のデータフレームに分割する
-
[Python] TypeError: 'NoneType' オブジェクトは添え字を付けられません。
-
100万語のテキストから100ミリ秒のフィルタリングで無効化された単語を検出
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】TypeError: re.findall()でバイトのようなオブジェクトに文字列パターンを使用することはできません。)
-
[解決済み】TypeError: 文字バッファオブジェクトを期待する
-
[解決済み】Pytesseract : "TesseractNotFound Error: tesseract is not installed or it's not in your path", how do I fix this?
-
[解決済み】 AttributeError: 'str' オブジェクトには 'items' という属性がない
-
Python データ可視化 JupyterLab ユーティリティ拡張 Mito
-
[解決済み] CSVへの書き込みで、空白文字列に「Error: need to escape」と表示される。
-
[解決済み] TensorFlow:変数の初期化で「初期化されていない値を使おうとしています。
-
[解決済み] Pythonで末尾のゼロを削除する [重複]。
-
python numpy.randomの詳細説明
-
Pythonのエラーです。TypeError: 'str' と 'int' のインスタンス間でサポートされていません。