[解決済み] データフレームにGroupbyの値カウントを行う pandas
2022-03-02 06:54:42
質問
以下のようなデータフレームがあります。
df = pd.DataFrame([
(1, 1, 'term1'),
(1, 2, 'term2'),
(1, 1, 'term1'),
(1, 1, 'term2'),
(2, 2, 'term3'),
(2, 3, 'term1'),
(2, 2, 'term1')
], columns=['id', 'group', 'term'])
でグループ化したい
id
と
group
で、このid, groupのペアの各項目の数を計算する。
だから、最終的にはこんな感じになるんです。
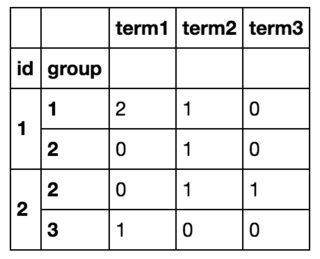
ですべての行をループさせることで、やりたいことを実現できました。
df.iterrows()
を作成し、新しいデータフレームを作成する必要がありますが、これは明らかに非効率的です。(役に立つなら、私は事前にすべての用語のリストを知っていて、それらのうちの〜10があります)。
グループ化してから値をカウントする必要があるようなので、試しに
df.groupby(['id', 'group']).value_counts()
という理由でうまくいきません。
値_回数
は、dataframe ではなく groupby 系列に対して操作します。
どうにかしてループさせずに実現できないでしょうか?
どのように解決するのですか?
私は
groupby
と
size
df.groupby(['id', 'group', 'term']).size().unstack(fill_value=0)
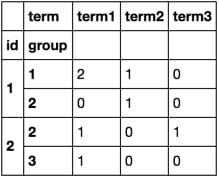
タイミング
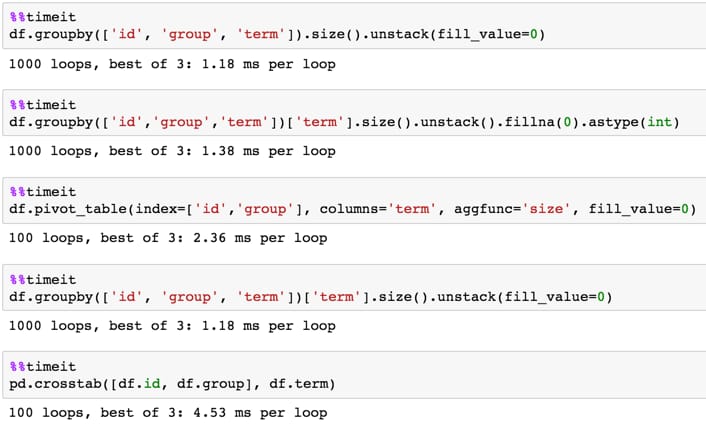
1,000,000行
df = pd.DataFrame(dict(id=np.random.choice(100, 1000000),
group=np.random.choice(20, 1000000),
term=np.random.choice(10, 1000000)))
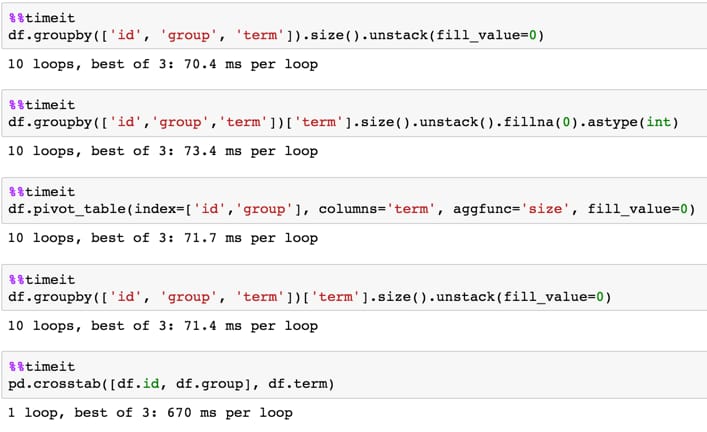
関連
-
python call matlab メソッドの詳細
-
[解決済み】numpy: true_divide で無効な値に遭遇
-
[解決済み] PandasでDataFrameの行を反復処理する方法
-
[解決済み] 列の値に基づいてDataFrameから行を選択するにはどうすればよいですか?
-
[解決済み] Pandasのカラム名のリネーム
-
[解決済み] Pandas DataFrameからカラムを削除する
-
[解決済み] Pandasのデータフレームで複数の列を選択する
-
[解決済み] Pandas DataFrameの行数を取得する方法は?
-
[解決済み] 既存のDataFrameに新しい列を追加する方法は?
-
[解決済み】Pandas DataFrameのカラムヘッダからリストを取得する。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Pythonコンテナのための組み込み汎用関数操作
-
pythonを使ったオフィス自動化コード例
-
Python 可視化 big_screen ライブラリ サンプル 詳細
-
Pythonの学習とデータマイニングのために知っておくべきターミナルコマンドのトップ10
-
Pythonコードの可読性を向上させるツール「pycodestyle」の使い方を詳しく解説します
-
風力制御におけるKS原理を深く理解するためのpythonアルゴリズム
-
[解決済み】「RuntimeError: dictionary changed size during iteration」エラーを回避する方法とは?
-
[解決済み] builtins.TypeError: strでなければならない、bytesではない
-
[解決済み】"No JSON object could be decoded "よりも良いエラーメッセージを表示する。
-
[解決済み】syntaxError: 'continue' がループ内で適切に使用されていない