ERR_CONTENT_LENGTH_MISMATCH問題
2022-02-27 18:11:25
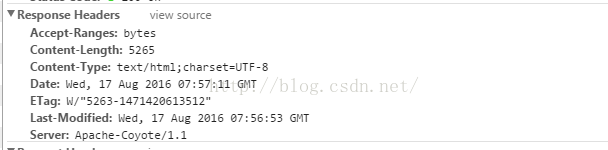
jspの開発過程で、ERR_CONTENT_LENGTH_MISMATCHの問題に何度も遭遇し、Google Chromeがアクセス時に必ずコンテンツ長の不一致を報告します。様々な可能性のある原因を分析しましたが、解決には至りませんでした。リクエストされたhtmlとエラーとして報告された情報を比較すると、リクエストされたhtmlファイルのサイズは5263バイト、レスポンスヘッダの情報は5265バイトと、バイト数が一致しないのです。
Google Chromeで見たレスポンスヘッダ情報(Content-Length: 5265)です。
要求されたhtmlファイルの属性。
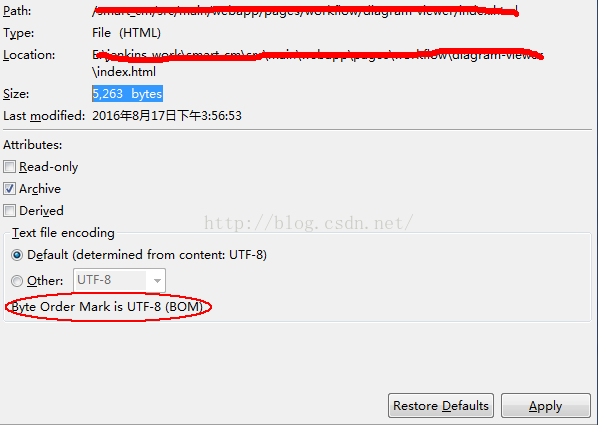
赤丸で囲った段落(Byte Order Mark is UTF-8 (BOM))を見て、ふとUTF-8のBOMを思い出しましたが、このBOMの問題で、Byte Order Markが複数個あるのでしょうか?そこで、このファイルをメモ帳++で開き、フォーマット ---> を選択して、UTF-8 no BOM 形式でエンコードして保存し、再掲載すると、OKです。
詳細な解析では、プロパティで見るファイルサイズと、ブラウザへのレスポンスのサイズが一致しないのはなぜですか?コンテナ(私のはtomcat)がBOM計算時にサイズを計算し、送信時には無視しているのでしょうか?それとも、送信時には無視せず、ある時点(ブラウザの統計情報を無視する場合など)で無視するのでしょうか?これは、より根本的な質問を含んでいるかもしれません、誰か知っている人が答えを与えてください。
BOMの説明付き。
BOM - バイトオーダーマーク、つまりByte Order Mark。
UCSのエンコーディングには"ZERO WIDTH NO-BREAK SPACE"という文字があり、これはFEFFとエンコードされています。そしてFFFEはUCSでは存在しない文字なので、実際の伝送では登場しないはずです。UCS仕様では、バイトストリーム伝送する前に "ZERO WIDTH NO-BREAK SPACE" という文字を送ることが推奨されています。NO-BREAK SPACE"です。こうすることで、受信者がFEFFを受信すれば、バイトストリームがビッグエンディアンであることを示し、FFFEを受信すれば、バイトストリームがリトルエンディアンであることを示す。このように、quot;ZERO WIDTH NO-BREAK SPACE"という文字は、BOMとも呼ばれます。
UTF-8では、バイトオーダーを示すBOMは必要ありませんが、エンコーディングのスタイルを示すためにBOMを使用することは可能です。ZERO WIDTH NO-BREAK SPACE"というキャラクタのUTF-8エンコーディングはEF BB BFです。したがって、受信者がEF BB BFで始まるバイトストリームを受信した場合、それがUTF-8でエンコードされたものであることを知ることができます。
UTF-8でエンコードされたファイルでは、BOMは3バイトを占めます。メモ帳でテキストファイルをUTF-8で保存した場合、UEでファイルを開き、16進数編集に切り替えると、オープニングのFFFEを確認することができます。これはUTF-8でエンコードされたファイルを識別する良い方法です。ソフトウェアはBOMを使ってファイルがUTF-8でエンコードされているかどうかを識別しますし、多くのソフトウェアはリードインファイルがBOMを持っていなければならないことを要求しています。
ボ・ブログのwikiにもあるように、同じくPHPを使っているボ・ブログも同じBOM問題に悩まされています。また、「COOKIE送信の仕組みに制約があり、これらのファイルではすでにファイルの先頭にBOMがあるため、COOKIEを送信できず(PHPがCOOKIE送信前にファイルヘッダを送信しているため)、ログインやログアウト機能が失敗する」という問題も挙げられています。COOKIEとSESSIONに依存する関数はすべて無効です。" これは、Wordpressのバックエンドで空白ページが表示される理由であるはずで、実行されるすべてのファイルがBOMを含むため、これらの3つの文字が送り出され、クッキーとセッションに依存する関数が失敗する原因となる。
utf-8はbomに追加されるべきではなく、エディタにutf-8であることを知らせるだけです。実際、エディタは、それほど多くないエンコーディングフォーマット間の機能に基づいて、ファイルのエンコーディングを判断する能力が十分にありますし、自動的に判断しないとしても、エディタにはエンコーディングを設定する場所があるはずです。だから、utf-8の場合はBOMは冗長だと思う。
utf-16はユニコード順でエンコードされており、BMPの範囲ではバイナリであるため、ビッグバイト順かリトルバイト順かを認識する必要があるため、ボムは必要なだけです。
実際、utf-8にサイズバイトオーダーの概念を導入するのは愚かなことだと思います。あの標準化委員会は何を考えていたのでしょうかね。サイズバイトオーダーの要点は、CPUがそれをどう処理するかということです。CPUが大バイト順の処理であれば、小バイト順の場合は変換を何重にも行わなければならず、効率の低下をもたらす。しかし、実際のアプリケーションでは、誰がサイズバイトオーダーを気にするのでしょうか?テキストエンコードに起因するバイトオーダーの概念は、規格を策定する側が厳しすぎるとしか言いようがありません。utf-16の場合、全世界が一つのバイトオーダーに従う限り、BOMでマークアップする必要はないと思います。
とはいえ、PHPはutf-16でエンコードされたファイルには対応していません。なぜなら、例えば$マークもutf-8では2バイトであり、PHPのデコーダではパースできないからです。PHP6で内部処理にunicodeの概念が導入されたときに対応するかどうかはわからない。
コーディングの問題は、簡単なようで面倒なことです。多くのプログラム、は階層的なコーディングの概念を持っています。MySQLのように、クライアント-> 接続-> ストレージとストレージ-> 接続-> 結果これらの概念に分けられる。ここまで複雑にする必要があるのかと思うこともありますが、TNNDもMySQLと同じで、これらの機能を使う人はいないのでしょうか?2つのクライアントを異なるコーディング環境で動作させるのでなければ、クライアントのコーディングを分離する必要はないでしょう。ほとんどの場合、バイナリイン/バイナリアウトだけで良いのです
関連
-
リスト解決にリスト("str "ではない)を連結することだけができる
-
Pythonではbreak文とcontinue文はifとしか使えないのでしょうか?
-
hibernate の遅延ロード例外分析: ロールのコレクションの遅延初期化に失敗しました。
-
ubuntu nohupコマンド
-
operator=' にマッチしない(オペランドの型が 'std::vector<float>' と 'float' である)。
-
socket.gaierror: [Errno 8] nodenameまたはservnameが提供されない、またはわからない
-
PL/SQL使用時にORA-06550エラーが発生しました。
-
C/C++学習メモ-アクティブな例外なしで呼び出されるterminate
-
python+opencv cv2.VideoCapture は動画の取得に失敗した Solution
-
新ソナーコードのレビュー課題のまとめ
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
発生: collect2 の原因の 1 つ: error: ld returned 1 exit status
-
Build Record 2-CSS file not loaded-Solved-Resource interpreted as Stylesheet but transferred with MIME type text/plain
-
エラーです。アクセス制限です。タイプ 'OperatingSystemMXBean'はAPIではありません(必要なライブラリに制限があります)。
-
eclipseを起動中、エラー。スレッド "main" で例外発生 java.lang.
-
c++のエラーエラー: "***"の前に期待される初期化子
-
IntelliJ maven プロジェクト pom ファイル エラー xx.jar の成果物記述子の読み込みに失敗した問題 解決方法
-
javaは起動したが、終了コード=-805306369を返した。
-
[UE4公式ドキュメント翻訳】Unreal Engine 4 For Unity Developers (UE4、ユニティデベロッパーズ向け)
-
Pygameでタイマーを使う
-
C# 指定されたキーが辞書に存在しない。