CS231n コースワークの KNN の実装における問題: np.bincount() Location ValueError: object too deep for desired array.
cs231n post-course workのknnパートをやったときに、gods of knowledgeからコードを拝借しました https://zhuanlan.zhihu.com/p/28204173
主にブログ主が問題に遭遇した箇所を掲載
メインプログラムの一部
#**************** cross-validate ******************#
num_folds=5
k_choices=[1,3,5,9,11,13,15,20,50]
x_train_folds=[]
y_train_folds=[]
y_train=y_train.reshape(-1,1)
x_train_folds=np.array_split(x_train,num_folds) #1
y_train_folds=np.array_split(y_train,num_folds)
k_to_accuracies={} #2
for k in k_choices:
k_to_accuracies.setdefault(k,[])
for i in range(num_folds): #3
classifier=KNearestNeighbor()
x_val_train = np.vstack(x_train_folds[0:i]+x_train_folds[i+1:]) #3.1
y_val_train = np.vstack(y_train_folds[0:i] + y_train_folds[i + 1:])
y_val_train = y_val_train[:,0] # commas are important
classifier.train(x_val_train,y_val_train)
for k in k_choices:
y_val_pred=classifier.predict(x_train_folds[i],k=k) #3.2
num_correct=np.sum(y_val_pred==y_train_folds[i][:,0])
accuracy=float(num_correct)/len(y_val_pred)
k_to_accuracies[k]=k_to_accuracies[k]+[accuracy]
for k in sorted(k_to_accuracies): #4
sum_accuracy=0
for accuracy in k_to_accuracies[k]:
print('k=%d, accuracy=%f' % (k,accuracy))
sum_accuracy+=accuracy
print('the average accuracy is :%f' % (sum_accuracy/5))
## Curve of accuracy for different values of k
for k in k_choices:
accuracies=k_to_accuracies[k]
plt.scatter([k]*len(accuracies),accuracies)
accuracies_mean=np.array([np.mean(v) for k,v in sorted(k_to_accuracies.items())])
accuracies_std=np.array([np.std(v) for k ,v in sorted(k_to_accuracies.items())])
plt.errorbar(k_choices,accuracies_mean,yerr=accuracies_std)
plt.title('cross-validation on k')
plt.xlabel('k')
plt.ylabel('cross-validation accuracy')
plt.show()
#************ prediction calculation with the best k value
best_k = input("Please enter the best k-value \t")
best_k = 10
classifier=KNearestNeighbor()
classifier.train(x_train,y_train)
y_test_pred = classifier.predict(x_test,k=best_k)
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
Where the error was reported
def predict_labels(self,lists,k=1):
num_test=dists.shape[0]
y_pred=np.zeros(num_test)
for i in range(num_test):
closest_y[]=[]
y_indicies=np.argsort(lists[i,:],axis=0) #Sort lists by smallest to largest and return index
closest_y=self.y_train[y_indicies[: k]] # assign the nearest k values to closest_y
print(closest_y)
y_pred[i]=np.argmax(np.bincount(closest_y)) ### error here
return y_pred
help(numpy.bincount)
bincount(...)
bincount(x, weights=None, minlength=0)
Parameters
----------
x : array_like, 1 dimension, nonnegative ints
Input array.
def predict_labels(self,lists,k=1):
num_test=dists.shape[0]
y_pred=np.zeros(num_test)
for i in range(num_test):
closest_y=[]
y_indicies=np.argsort(lists[i,:],axis=0) #Sort lists by smallest to largest and return index
closest_y=self.y_train[y_indicies[: k]] # assign the closest_y to the k nearest values
if np.shape(np.shape(closest_y))[0] ! =1: ############ add procedure
closest_y=np.squeeze(closest_y) ############ add procedure
y_pred[i]=np.argmax(np.bincount(closest_y))
return y_pred
クロスバリデーションと指定されたk値での正答率はどちらも別々に動作しますが、まずクロスバリデーションで最適なkを見つけ、その最適なkを予測計算に使用すると、ValueError: object too deep for desired arrayという結果になります。
ヘルプファイルには、「xは1次元で、非負である。
help(numpy.bincount)
bincount(...)
bincount(x, weights=None, minlength=0)
Parameters
----------
x : array_like, 1 dimension, nonnegative ints
Input array.
これをプログラムでprint(close_y)と出力しています。
クロスバリデーションはこのように印刷されます。

テストセット呼び出し時、つまりエラー時の closest_y は次のようになります。
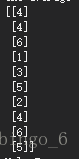
直感的には次元が深すぎるように見えますが。重要なのは、このコールで何が悪かったのか?以前の多くの呼び出しではエラーにならなかったという事実はどうでしょうか?朝からこれを元に修正しようとしたのですが、無駄だったので、まずはメモしておきます。
また、別の方法で実装しているブロガーさんのリンクも添付します。https://blog.csdn.net/stalbo/article/details/79281901。
5月6日更新 ******************************************** 5月6日更新 ************************************ 5月6日更新
今日、SVMの課題をやっているときに、以下のものに出会いました。 numpy.squeeze() この関数、ふと「いけるかも」と思ったのですが、次のようなことをします。 配列の形状から一次元のエントリを削除する、つまり形状から1の次元を削除する、ブログ参照 クリックするとリンクが開きます . そして、この関数を以下のコードで適応させた。
def predict_labels(self,lists,k=1):
num_test=dists.shape[0]
y_pred=np.zeros(num_test)
for i in range(num_test):
closest_y=[]
y_indicies=np.argsort(lists[i,:],axis=0) #Sort lists by smallest to largest and return index
closest_y=self.y_train[y_indicies[: k]] # assign the closest_y to the k nearest values
if np.shape(np.shape(closest_y))[0] ! =1: ############ add procedure
closest_y=np.squeeze(closest_y) ############ add procedure
y_pred[i]=np.argmax(np.bincount(closest_y))
return y_pred
一次元配列は2回整形した後に1を返し、多次元配列は1より大きいので、if選択文を追加し、1以外を返した時にnp.squeezeで次元を小さくし、その後にnp.bincount()を使えばエラーにならない。
関連
-
ResNetの紹介
-
py-faster-rcnn/lib の make でエラー: コマンドラインオプション '-Wdate-time' が認識されない
-
xx.exe の 0x00007FF7A7B64FB3 でスローされた例外: 0xC0000005: 場所 0x00 を読み取るアクセス違反
-
tensorflowをインポートしています。ImportError: libcublas.so.9.0: cannot open shared object file: No such file or director
-
ImportError: libSM.so.6: cannot open shared object file: そのようなファイルやディレクトリはありません
-
TypeError: 'module' object is not callable solution to [Keras] call "merge".
-
pytorchはエラーを報告します。ValueError: num_samples は正の整数値であるべきですが、num_samples=0 となりました。
-
AttributeError: 'tuple' オブジェクトには 'log_softmax' という属性がありません。
-
TensorFlow実行時エラー、AttributeError: モジュール 'pandas' には 'computation' という属性がない。
-
AttributeError: モジュール 'pandas' には 'core' という属性がありません。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[Tensorflow-Error】CUDA_ERROR_OUT_OF_MEMORY:メモリが不足しています。
-
Tensorflow 踩坑:ImportError: DLL のロードに失敗しました。指定されたモジュールが見つかりません。 TensorFlowのネイティブランタイムのロードに失敗しました。
-
トーチの取り付けと使用
-
参照用シークレットを呼び出す:BN層詳細解説
-
PackagesNotFoundError: 次のパッケージは、現在のチャンネルから利用できません ソリューション
-
Tensorflowのメタフィジカルエラーです。終了コード -1073741819 (0xC0000005)
-
U-netのソースコード解説(Keras編)
-
caffeのインストールで「error : too few arguments in function call」エラーが発生する。
-
ロジスティック回帰は2分法モデル
-
tensorflow experience code error Adding visible gpu devices: 0 , モジュール 'tensorflow' には 'Session' という属性がありません。