10分で始める正規表現 Next
画像
この記事では、一般的なEREのパターン記号を中心とした拡張知識と、シェルスクリプトでの正規表現の例について説明します。
I. よく使われる正規表現記号
この章の例では、gawkプログラムスクリプトでより一般的なEREパターンシンボルを取り上げます。
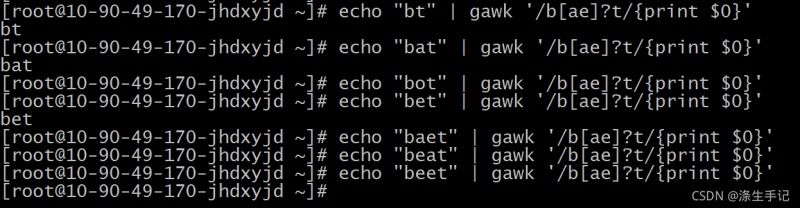
1.1 クエスチョンマーク [?
は、そのクエスチョンマークはアスタリスクに似ていますが、いくつかの細かい違いがあります。クエスチョンマークは、直前の文字が0回または1回だけ現れる可能性があることを示します。ある文字が複数回出現した場合にはマッチしません。例では、次のようになります。

スクリプトの説明です。
eという文字が本文中にない場合、または本文中に1回だけ現れる場合は、このパターンにマッチします。
アスタリスクと同様に、クエスチョンマークも文字グループと一緒に使用することができます。

スクリプトの説明です。
文字群に含まれる文字が0回または1回出現すれば、パターンマッチは成立する。ただし、両方の文字が出現する場合、またはどちらかの文字が2回出現する場合は、パターンマッチは成立しない。
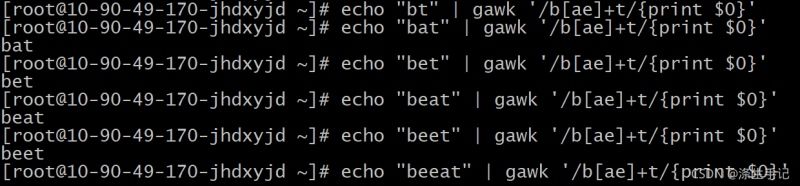
1.2 プラス記号[+]について
プラス記号もアスタリスクに似たパターン記号であるが、クエスチョンマークとは異なる。プラス記号は、直前の文字が1回以上出現してもよいが、少なくとも1回は出現しなければならないことを示す。もしその文字が現れなければ、そのパターンはマッチしません。
解説の例
eという文字が表示されない場合は、パターンマッチは無効です。プラス記号は文字グループにも適用され、アスタリスクやクエスチョンマークと同じように使用される。

スクリプトの解釈
文字セットで定義された文字のいずれかが出現した場合、テキストは指定されたパターンにマッチします。
1.3 括弧{}について
EREの括弧は、繰り返し使える正規表現に上限を指定することを可能にします。これはしばしばインターバルと呼ばれます。インターバルは2つの形式で指定することができます。
- m: 正規表現がちょうどm回出現する。
- m, n: 正規表現が少なくともm回、多くてもn回出現する。
この機能は、ある文字または文字セットがパターン内に何回現れるかを正確に調整するものです。
ハイライト
デフォルトでは、gawk プログラムは正規表現の間隔を認識しません。正規表現のインターバルを認識するには、gawkプログラムの--re- intervalコマンドラインオプションを指定する必要があります。
例
解釈例です。
は、パターンにマッチする文字列中にその文字が出現する回数を1間隔で制限し、その文字が複数回出現した場合はパターンマッチが成立しないことを示します。
上限と下限を指定することもできます
画像
解釈例です。
e という文字が 1 回または 2 回現れるとパターンにマッチし、そうでない場合はマッチしない。
以下は、文字グループの例です。

解釈例です。
文字aまたはeがテキストパターン中に1~2回しか出現しない場合、正規表現パターンはマッチし、それ以外の場合はパターンマッチに失敗する。
1.4 パイプ記号[|]について
はパイプ記法では、データストリームをチェックする際に正規表現エンジンが論理和で使用するパターンを2つ以上指定することができます。パターンのいずれかがデータストリームのテキストと一致すれば、そのテキストはテストに合格します。一致するパターンがない場合、データフローテキストは不合格となる。
形式を使用します。
expr1 |expr2|...です。
例

解釈例です。
この例では、データストリームの中から正規表現catまたはdogを探します。正規表現とパイプ記号の間にはスペースを入れてはいけません。さもないと、正規表現パターンの一部とみなされます。
パイプ記号の両側の正規表現は、任意の正規表現パターン(文字グループを含む)を使って定義することができます。次の例を参照してください。

解釈例です。
この例では、ストリームテキスト中のcat、hat、dogにマッチします。
1.5 括弧()
正規表現パターンは、括弧の中でグループ化することもできます。正規表現パターンをグループ化する場合、グループは標準文字として扱われます。グループには通常の文字と同様に特殊文字を使用することができます。
例

解釈例です。
末尾の urday グループとクエスチョンマークにより、このパターンは完全な土曜日または省略形の Sat にマッチします。
グループ化とパイプ表記を併用して、パターンマッチの可能性のあるグループを作るのが一般的である。例は以下の通りです。

解釈例です。
パターン (c|b)a(b|t) は、第1グループの任意の文字の組み合わせと、第2グループの任意の文字の組み合わせにマッチします。
次に、正規表現の実践例
例1.
以下は、環境変数PATHで定義されたディレクトリにある実行ファイルをカウントする機能を持つスクリプトになります。
スクリプトの内容は以下の通りです。
#! /bin/bash
# count number of files in your PATH
mypath=$(echo $PATH | sed 's/:/ /g') # Replace the colon with a space to split the path
count=0
for directory in $mypath
do
check=$(ls $directory)
for item in $check
do
count=$[ $count + 1 ]
done
echo "$directory - $count"
count=0
done
実行結果

例2.
メールアドレスを解析するための正規表現
メールアドレスの基本的な書式は、ユーザー名@ホスト名
ユーザー名の値には、英数字のほか、以下の特殊文字を使用することができます。(ドット、シングルダッシュ、プラス、アンダースコア)
有効な電子メールユーザー名では、これらの文字はどのような組み合わせで表示されてもかまいません。メールアドレスのホスト名部分は、1つまたは複数のドメイン名とサーバー名から構成されます。サーバー名とドメイン名も厳格な命名規則に従う必要があり、英数字と以下の特殊文字のみが使用可能です。(ドット、アンダースコア)
サーバー名とドメイン名はドットで区切り、サーバー名を最初に指定し、その後にサブドメイン名を指定し、最後にドットなしで指定します。
トップレベルドメインです。
かつてはトップレベルドメインの数が限られていたため、正規表現のパターン作成者はすべてのドメインを検証パターンに加えようとした。
しかし、残念ながら、インターネットの発展とともに、利用可能なトップレベルドメインの数も増えてきました。この方法は、もはや実現不可能なのです。
この正規表現パターンを左から構築する。
ユーザー名での表現パターンをフィルタリングする。
^([a-zA-Z0-9_tex-. \+]+)@.
このグループ分けは、ユーザー名に使用できる文字を指定するもので、プラス記号は少なくとも1つの文字がなければならないことを示す。次の文字は当然@です。
ホスト名パターンでは、サーバー名やサブドメインにマッチするように、同じ手法で
([a-zA-Z0-9_inta-] +)
トップレベルドメインの正規表現パターン。
\. ([a-zA-Z]{2,5})$.
全体の組み合わせパターン
^([a-zA-Z0-9_JPY. \+]+)@([a-zA-Z0-9_JPY.] +)\. ([a-zA-Z]{2,5})$.
スクリプトに巻き込む。
cat isemail.sh
#! /bin/bash
# script to filter out bad phone numbers
awk --re-interval '/^([a-zA-Z0-9_\-\. \+]+)@([a-zA-Z0-9_\-\-\.] +)\. ([a-zA-Z]{2,5})/{print $0}'
注意: awk プログラムで正規表現のインターバルを使用する場合、 --re-interval コマンドラインオプションを使用する必要があります。
テストスクリプトの例です。

解釈例です。
ルールに合致するメール名は画面に出力され、合致しないものはフィルタリングされ、内容は出力されない。
正規表現を始めて10分程度のこの記事は、より関連する正規表現を、BinaryDevelopの過去記事を検索するか、以下の関連記事を引き続き閲覧してください!BinaryDevelopをもっと応援していただけると幸いです。
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン