正規表現でよく使われる4つのマッチングパターンのまとめ
0. 前に書き込む
今日は、レギュラーの中の、いわゆるマッチパターンについて学びますが、このマッチパターンは、いくつかの メタ文字のマッチング動作を変更する のように、大文字と小文字を区別せずにマッチします。
第2回で学んだgreedy、non-greedy、exclusiveパターンは、正規表現の中の数量詞のマッチング動作を変更するものであることを思い出してください。今日は数量詞に関係ないマッチングパターンを見てみましょう。その中には、case-insensitive、ドット付きワイルドカード、複数行マッチング、注釈付きパターンの4つがあります。
1. 大文字小文字を区別しないモード
大文字小文字を区別しないモードとは、その名の通り、対象の文字列に含まれるCatにマッチさせたい、大きな猫CATでも小さな猫CATでも構わないから、とにかくマッチさせてくれという意味です。
パターンモディファイアは (?パターン識別子) で、対応するレギュラーの前にpattern modifierを置くだけで、指定されたパターンが使えるようになります。
大文字小文字を区別しない英語はCase-Insensitive、パターン識別子を小文字の頭文字で表すと (?i) 先ほどの栗のルールは、次のように書くことができます。 (?i)cat , 見てください。
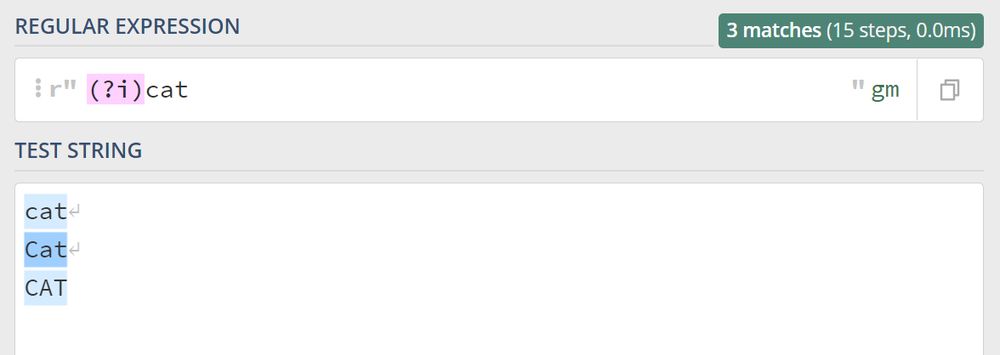
前の記事 の中で、グループ化と参照について学びましたが、もし2匹の猫をマッチングさせるのが (?i)(cat) ୧⃛(๑⃙⃘⁼̴̀꒳⁼̴́๑⃙⃘) :
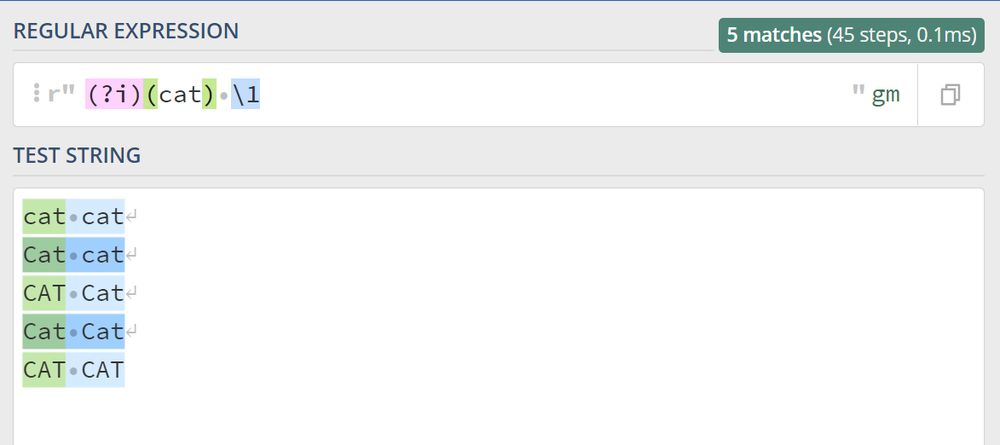
対応するPythonのコードは以下の通りです。
import re
result = re.findall(r"(?i)(cat) (\1)", "cat cat CAT Cat")
print(result)
Output: [('cat', 'cat'), ('CAT', 'Cat')]
ご覧のように、前後の2匹の猫は同じケースにマッチしませんが、マッチさせることもできます。同じケースにマッチさせたい場合は、外側にあるブラケットを重ねます。 , 見てください。
テストリンク
https://regex101.com/r/tPXuGX
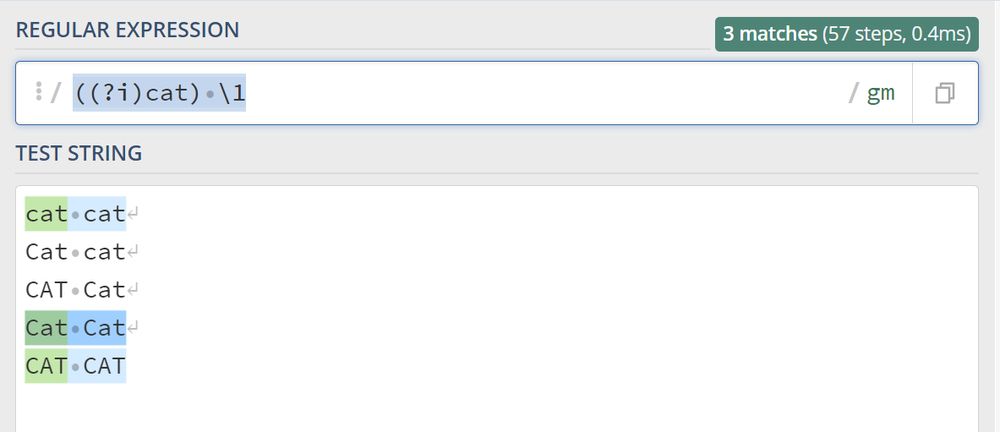
注:Pythonでは、reライブラリを使用して上記のregularを呼び出すと、以下の例外が発生します。regexライブラリに置き換えると動作しますが、大文字小文字を区別した2つのcatに正確にマッチしません。
DeprecationWarning: フラグが式の先頭にない
import regex
result = regex.findall(r"((?i)cat) (\1)", "cat cat CAT Cat")
print(result)
Output: [('cat', 'cat'), ('CAT', 'Cat')]
2. 点線のワイルドカードパターン
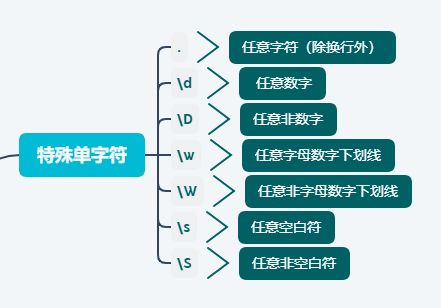
で 最初の投稿 メタキャラクタについて学び、また、英語のポイントも覚えました。 . どんな文字にもマッチしますが、改行はできません。本当に任意の文字にマッチさせたい場合は、[˶‾᷄ -̫ ‾᷅˵ ]や[˶‾᷅˵ ]、[˵w˵]などで対応します。
しかし、これではエレガントに書けないので、規則性から、英語のモード . このパターンをドット付きワイルドカードパターンと呼ぶ。
点線のワイルドカードパターンは、多くの場所でSingle Lineパターンと呼ばれ、Single Lineの頭文字で表されるため、Single Lineパターンに対するモディファイアは (?s) 例えば
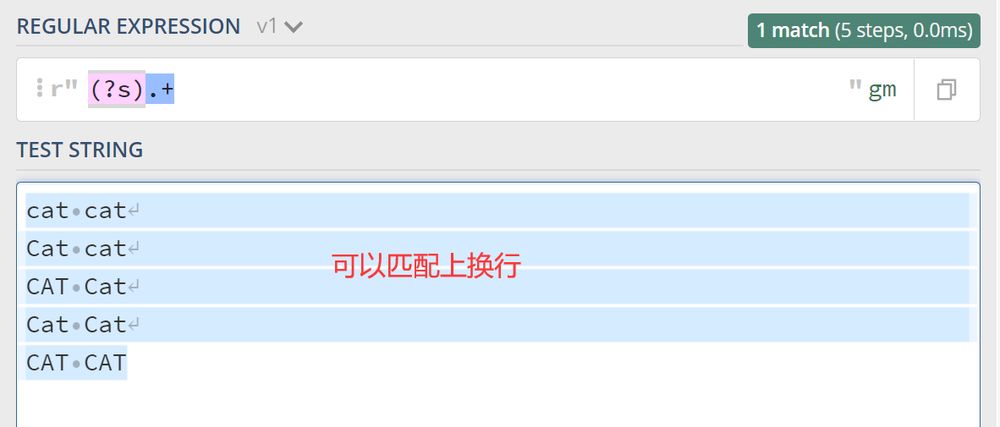
3. 複数行マッチングパターン
レギュラーでは ^ は対象文字列全体の先頭にマッチさせるために使用されます。 $ ユーザーが対象文字列全体の末尾にマッチさせる場合。
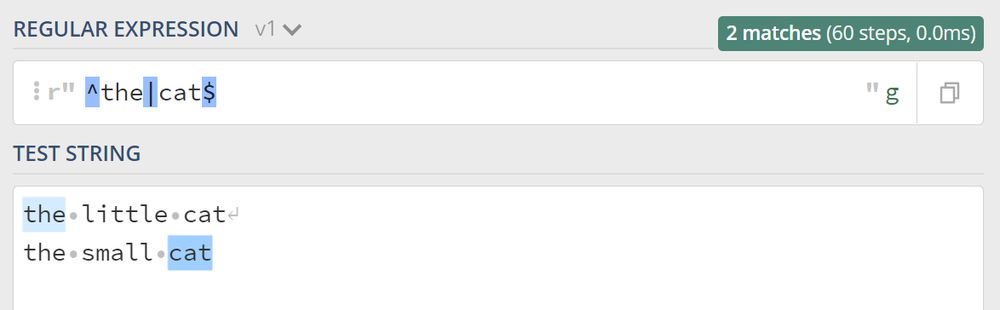
各行の先頭と末尾にマッチさせたい場合は、複数行マッチングパターンが登場します。複数行を表す英語は Multiline なので、複数行パターンのモディファイアは (?m) という効果があります。
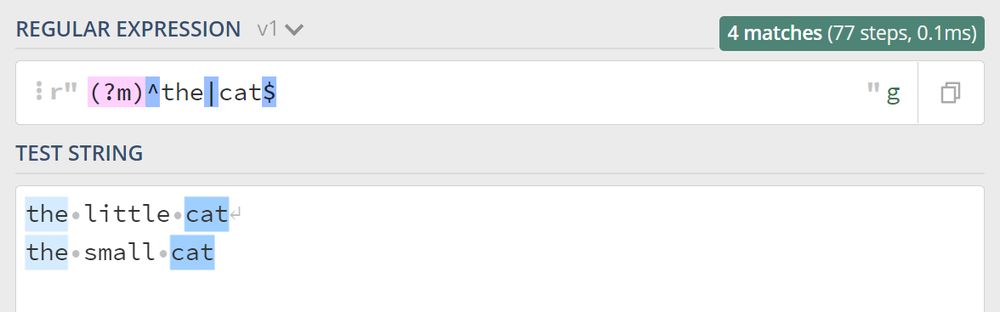
4. コメントモード
長い表現の羅列を書いたところで、その時の意味はあなたと神様しかわからないかもしれないし、半年後には神様しかわからないかもしれない。
コメントを表す英語はCommentなので、コメントパターンに対応するモディファイアは (? #comment) 頭文字がないことと、余分な#記号に注意してください。先ほど書いたIPv4アドレスのマッチングルールを例にしてみましょう。
また、多くのプログラミング言語では、Pythonのようにコメントを兼ねた正規表現を記述するためのxパターンが用意されています。
{{コード
xモードでは、改行や空白はすべて無視されます。一致させるには、改行や空白をエスケープするか、文字グループに入れてください。
import re
regex = r'''(?mx) # Use multiline mode and x mode
^ # Start with
(\d{4}) # year
(\d{2}) # month
$ # Ending
'''
result = re.findall(regex, '202006\n202106')
print(result)
Output: [('2020', '06'), ('2021', '06')]
5. 最後に書く
最後に、上記の内容をまとめると。
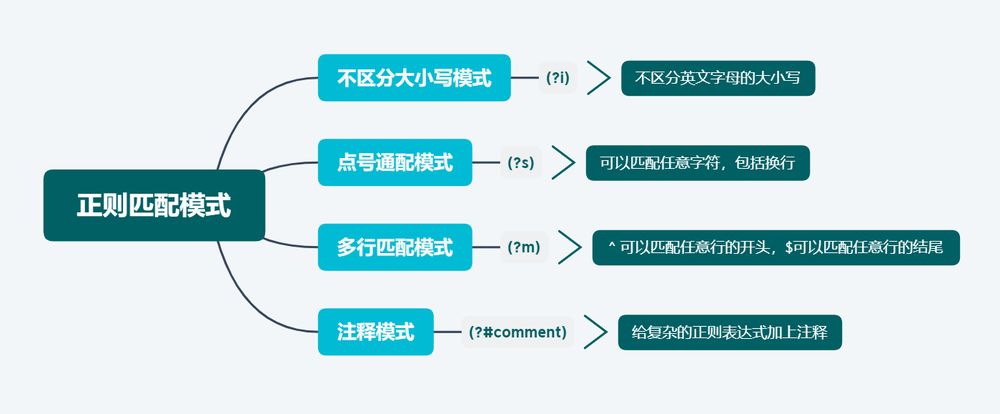
正規表現オンライン検証ツール。 https://regex101.com
正規表現の4つの一般的なマッチングパターンについて、この記事では、より関連する正規表現、マッチングパターンを紹介しています、スクリプトの家の過去の記事を検索してくださいまたは次の関連記事を閲覧し続けるあなたは、将来的にもっとスクリプトの家をサポートすることを願っています
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン