正規表現の量詞の使い方と欲張りな説明
0. 前面に書く
で 前の記事 は、レギュラーの基本的なメタキャラクタを学びましたが、これはかなり忘れていると思いますので、上のリンクをクリックして、リフレッシュしてください。
今日は、regularの量詞の3つのマッチングモード、greedyモード、non-greedyモード、exclusiveモードを学びます。これらのモードは、regularの量詞のマッチング動作を変更します、それは毎回よりマッチするように貪欲ですか、それを見て貪欲ではない、我々はこれらを理解していない場合、我々は正規は間違っているとさえ深刻なオンラインパフォーマンス問題を引き起こす可能性があります書かれています。
1. 量詞
この記事で扱う内容は、量詞とより密接に関連するもので、まず、「量詞」の復習から始めます。
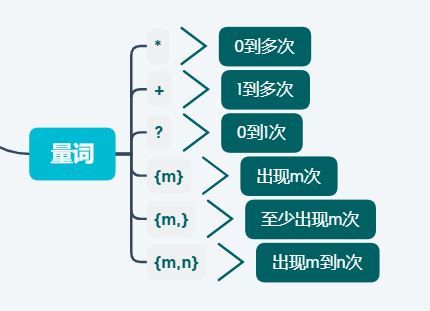
また {m,n} とする。 を表現するために * + ? 3つのメタキャラクタ。
<テーブル メタキャラクタ 同義語表現 例 * {0,} ab*
に一致させることができます。
a または abb + {1,} ab+
に一致させることができます。
ab または abb
にはマッチしませんが ? {0,1} ab?
aまたはabにマッチすることができる
にはマッチするが、abb にはマッチしない
2. 貪欲モード前日譚
レギュラーでは、回数を示す量詞はデフォルトで greedy になっています。greedyモードでは、対象の文字列に対して可能な限りの長さをマッチングさせるため、レギュラーの a+ と a * 文字列にマッチするように aaabb テストしてみてください。
2.1 a+を使ったマッチング
1つの結果だけがaaaにマッチしていることがわかります。
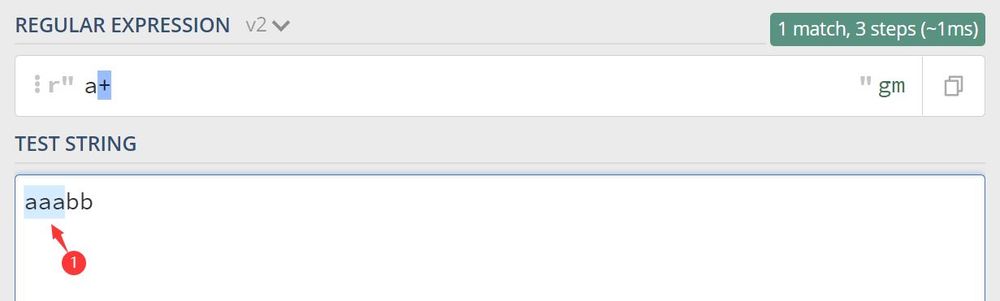
対応するPythonのコードは以下の通りです。
import re
print(re.findall(r'a+', 'aaabb'))
Output: ['aaa']
2.2 a*を用いたマッチング
4つの結果がマッチし、そのうち3つは空の文字列であることがわかります。
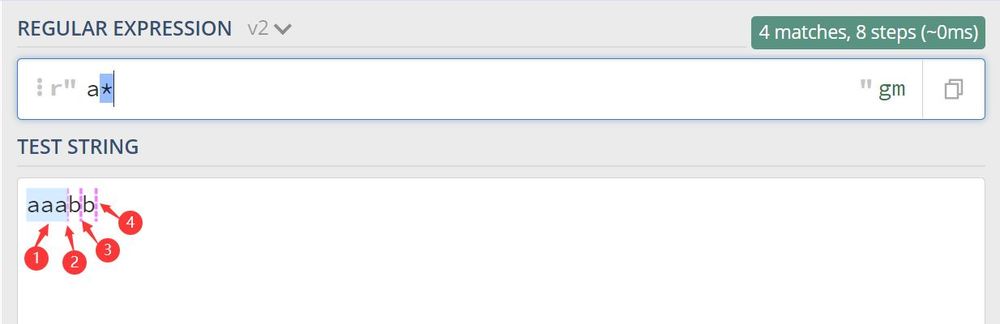
対応するPythonのコードは以下の通りです。
import re
print(re.findall(r'a*', 'aaabb'))
Output: ['aaa', '', '', '']
なぜ空の文字列にマッチするのですか?アスタリスク(*)は0~多数のマッチを意味し、0マッチは空文字列だからです。では、なぜaaaとaaaの間の空文字列はマッチしないのでしょうか?
ここで、本日のテーマである「欲張りパターン vs. 非欲張りパターン」の話になるのですが、文字通り、欲張りパターンはできるだけ多くの回数をマッチングし、非欲張りパターンはできるだけ少ない回数をマッチングする、という単純なものです。
3. 貪欲なパターン
上記のレギュラーを分解してみましょう a * のマッチング処理を行います。
<テーブル 文字列 a a a b b 空の文字列 添え字 0 1 2 3 4 5
<テーブル 一致 開始 終了 説明 適合するコンテンツ 初回 0 3 最初の文字bに移動して不一致を見つけ、aaaを出力する aaa 2番目 3 3 bbの残りにマッチ、マッチしない場合、空文字列を出力する 空の文字列 3番目 4 4 bの残りにマッチ、マッチしない場合、空文字列を出力する 空の文字列 第四 5 5 残りの空文字列にマッチし、空文字列を出力する 空の文字列
a* 文字列 aaabb にマッチする場合、最初の b にマッチせず、3 つの a にマッチし、それ以降のマッチはそれぞれ空文字列になるまで、できるだけ多くの先行する a にマッチします。
できるだけ最大長でマッチングするのが特徴のGreedyパターンについては、皆さんもよくご存知だと思いますが、その真逆のパターンも一緒に見ていきましょう。
4. 非グリーディパターン
greedyパターンについて話した後、greedyパターンは可能な限り最大長のマッチ、non-greedyパターンは可能な限り最小長のマッチで、量詞の後にクエスチョンマーク(?)を付けるとnon-greedyパターンになり、例えばa*?
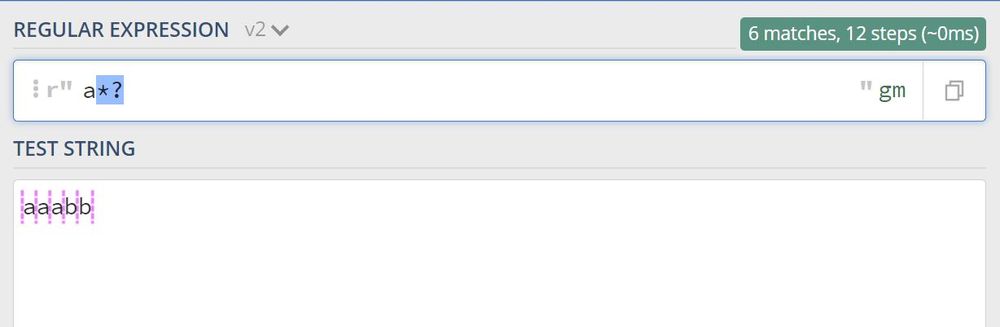
対応するPythonのコードは以下の通りです。
import re
// greedy match
print(re.findall(r'a*', 'aaabb'))
Output: ['aaa', '', '', '']
// Non-greedy matching
print(re.findall(r'a*?' , 'aaabb'))
Output: ['', 'a', '', 'a', '', 'a', '', '', '', '']
欲張りパターン、非欲張りパターンについて学んだ後、どのような場面でそれらを使えばいいのか、と聞かれることがあります。
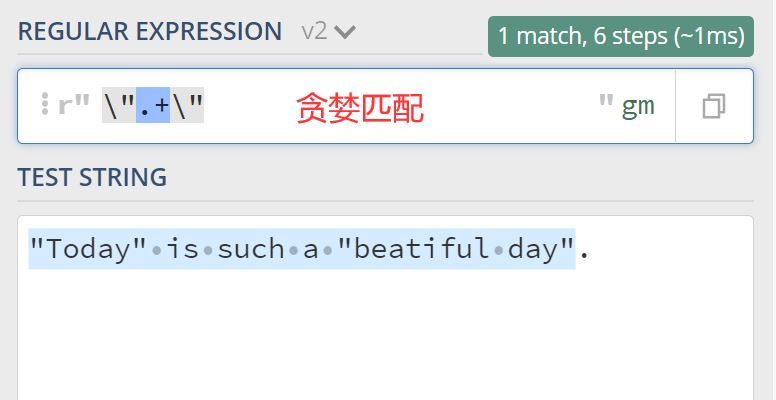
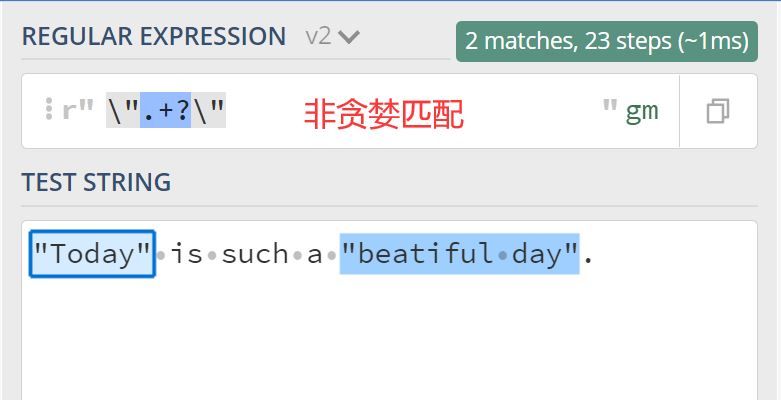
要件は、文字列中のダブルクォートで囲まれた内容をすべて見つけることであり、上記の欲張りマッチングと非欲張りマッチングを使えば、その違いは明らかでしょう?
5. 排他的モード
バックトラックは必要ないが、マッチしない場合は失敗を返せばよいというシナリオもある。そこで、レギュラー・マッチングには排他的という別のパターンがある。これは greedyと非常によく似ているが、マッチング中にバックトラックを行わないので、シナリオによってはこちらの方がよい。
まず、バックトラックとは何かということから、正規表現と対象文字列を見て、3つのマッチング・モードそれぞれでどうなるかを見てみましょう。
5.1 欲張りマッチング処理
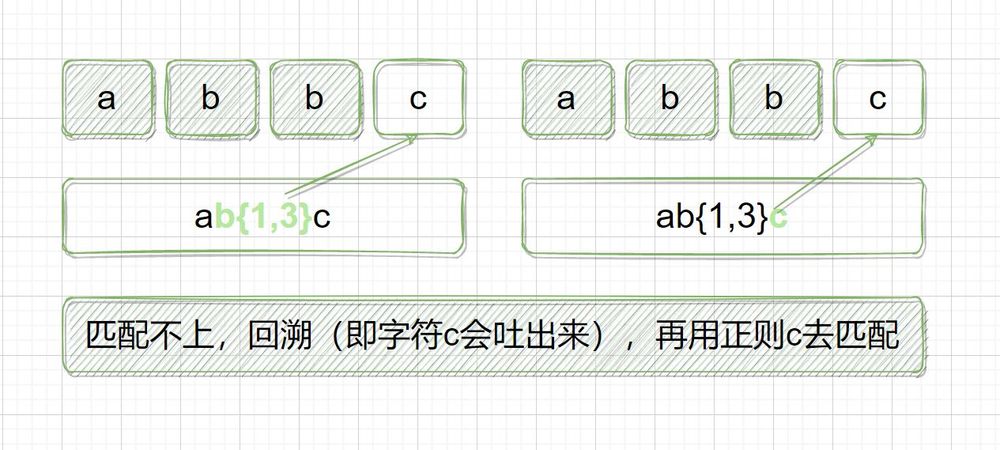
<ブロッククオート正規表現:ab{1,3}c
対象文字列:abbc
マッチングの際、b{1,3}は対象の文字列とマッチするために可能な限り長く進みます。abbとマッチした後、可能な限り長く(3つのb)マッチするために、対象の文字列のcはマッチしません。このとき、フォワードバックトラックが起こり、現在の文字cを吐き出し、マッチするように通常のcを使って、マッチは成功するのです。
import regex
print(regex.findall(r'ab{1,3}c', 'abbc'))
Output: ['abbc']
5.2 非欲求型マッチング処理
正規表現:ab{1,3}?c
対象文字列:abbc
マッチングの際、b{1,3}は対象文字列をできるだけ短くマッチングし、abをマッチングした後、対象文字列の残りのbを直接正規のcとマッチングし、マッチしなかった場合、バックトラックして対象文字列の残りのbを正規b{1,3}とマッチし、正規cは残りcとマッチし、マッチングは成功します。

import regex
print(regex.findall(r'ab{1,3}?c', 'abbc'))
Output: ['abbc']
5.3 排他的論理和処理
量詞に+をつけると排他的パターンになります。
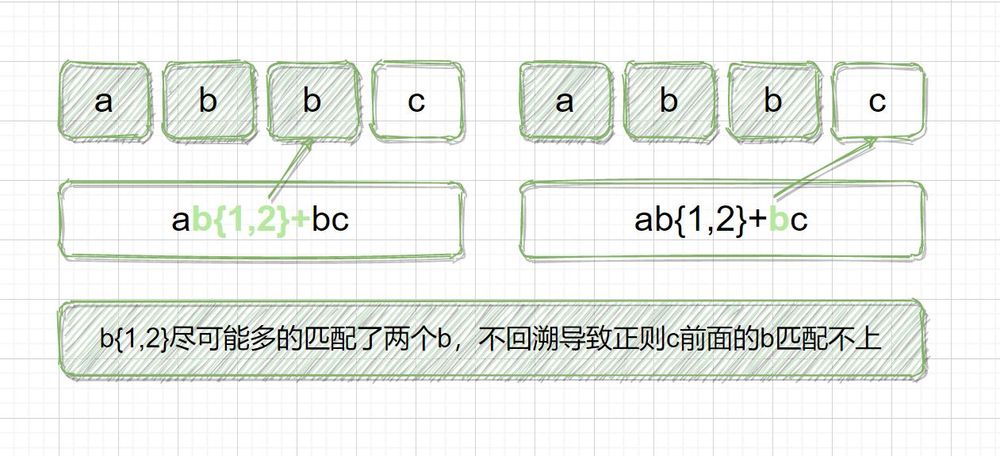
正規表現:ab{1,2}+bc
対象文字列:abbc
マッチングの際、b{1,2}は対象の文字列を可能な限り長くマッチングし、abbにマッチした後、対象の文字列の残りのcを正規のbでマッチングし、マッチしない場合は後戻りせず、マッチングは失敗します。
import regex
print(regex.findall(r'ab{1,2}+bc', 'abbc'))
Output: []
6. 最後に書く
最後に、上で言われたことをまとめると。
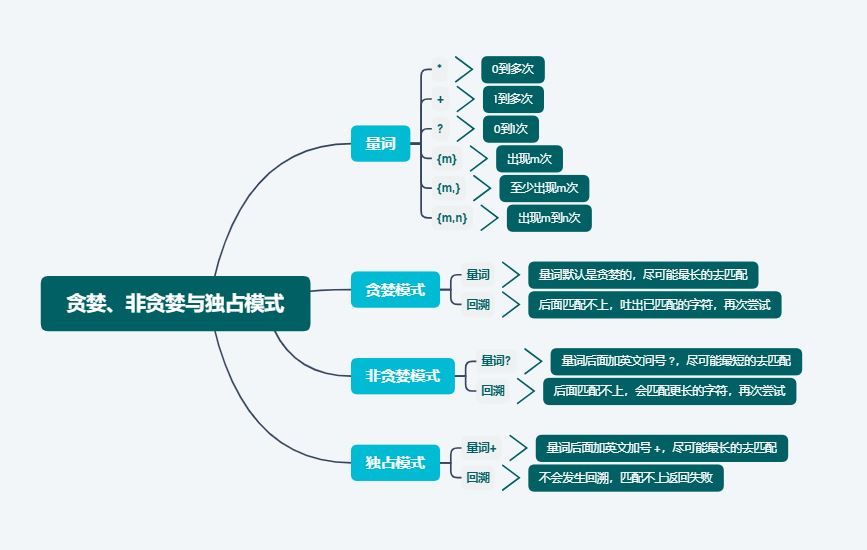
これで量詞と欲の正規表現は終わりです。もし質問があれば、私にコメントを残してください、ありがとうございます。
正規表現オンライン検証ツール。 https://regex101.com/
正規表現の量化子と貪欲の使用に関するこの記事がすべてです、より関連する正規表現の量化子と貪欲のコンテンツは、スクリプトハウスの過去の記事を検索するか、次の関連記事を参照してください、あなたは将来的にもっとスクリプトハウスをサポートすることを望みます
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン