tensorflowの学習における問題点
<スパン 1. tensorflow.python.framework.errors_impl.permissiondeniederror /path 権限拒否問題の解決法
<スパン Linux 環境で Python プログラムを実行する場合、上記の問題が発生することがあります。この問題の解決策は、パスを絶対パスに変更することです、例えば
'/path/to/MNIST_data/' です。
<スパン に変更します。
"/home/yangjy/path/to/MNIST_data/"。
そして、問題を解決することができます
2. 出力されるログメッセージをマスクするためのtensorflowメソッド
環境変数 'TF_CPP_MIN_LOG_LEVEL' の値は、tensorflow が通知メッセージ、警告、エラー報告などの出力メッセージをブロックするかどうかを制御するために、tensorflow で設定することができます。
<スパン 使用法: import os import tensorflow as tf os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # または任意の {'0', '1', '2'} }. tf_cpp_min_log_level
値0を取る: 0はデフォルトでもあり、すべてのメッセージを出力する TF_CPP_MIN_LOG_LEVEL
値1:通知メッセージTF_CPP_MIN_LOG_LEVELをマスクします。
値 2: 通知および警告メッセージのマスク TF_CPP_MIN_LOG_LEVEL
値3:通知メッセージ、警告メッセージ、エラーメッセージをマスクする ------------------------。
この記事は -Makino- の CSDN ブログから引用したもので、記事全文は以下のサイトでご覧になれます。 https://blog.csdn.net/dcrmg/article/details/80029741?utm_source=copy
<スパン 3. tf.nn.conv2d関数とtf.nn.max_pool関数の紹介
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
導入パラメータです。
input: 畳み込みに必要な入力パラメータを指し、その形状は [batch, in_height, in_width, in_channels] で、それぞれ [batch images, in_height per image, in_width per image, in_channels] となっています。
filter: 畳み込みに使用するフィルタ。もちろん、フィルタにも対応するパラメータが必要で、フィルタの形状は [filter_height, filter_width, in_channels, out_channels] で、 [filter_height, filter_width, 受け入れ画像チャンネル数, 畳み込み後のチャンネル数] に対応し、3番目のパラメータ in_channels は [filter_height, filter_width, in_channels, out_channels] でなければならない。3 番目のパラメータ in_channels は input の 4 番目のパラメータ in_channels と一致させる必要があります.out_channels は最初に見てしまうとちょっとわかりにくいですが,例えば rgb 入力が 3 チャンネルグラフの場合,フィルタの out_channels は 1 となり,3 チャンネルの対応値が加算されて最後に畳み込みカーネルが出力されることを意味します.
strides: ステップを表し、値は直接デフォルトの数字か、[1,2,1,1]のような4次元の数字になります。つまり、水平方向の畳み込みステップは第2パラメータの2、垂直方向のステップは1です。 第1と第4パラメータがよく分からないので、正しい方向を示してください。チャンネルと関連しているようです。
SAMEはVALIDより1列多い。例えば、3*3の画像を2*2のフィルターで畳み込んだ場合、ステップサイズを2に設定すると、1列が欠落し、2回目の畳み込みを行ったときに、VALIDは残りのウィンドウが2*2より小さいと判断し、直接3列目を削除します。SAMEはその後、1列を充填値0で充填する。
use_cudnn_on_gpu: bool 型、cudnnアクセラレーションを使うかどうか、デフォルトはtrueです。
name: 返されるテンソルに名前をつける。出力される特徴マップに名前をつける。
tf.nn.max_pool(value, ksize, strides, padding, name=None)
value: プーリングへの入力。通常、プーリング層は畳み込み層に続くので、出力は通常、特徴マップになる。特徴マップはまだ [batch, in_height, in_width, in_channels] といったパラメータである。
ksize: プーリング窓の大きさ, パラメータは4次元ベクトル, 通常は [1, height, width, 1], バッチとチャンネルでプールしたくないので、この2次元は1に設定されている. ps: tf.nn.conv2d のstriesの4値は同じ意味を持つと推定されている.
stries: ステップサイズ、やはり4次元ベクトル。
padding: 今回も2つのpaddingメソッドのみが繰り返されない。
<スパン 4.tensorflow.python.framework.errors_impl.InvalidArgumentError: Cannot assign a device for operation 'TensorArray_3': ノードは互換性のないデバイス '/device:GPU:0' を必要とするノードグループとコロケートされていたため、明示的なデバイス指定 '' を満たすことができませんでした。
config = tf.ConfigProto()
config.gpu_options.allocator_type = 'BFC' です。
config.gpu_options.allow_growth = True
#セス
sess = tf.Session(config=config)
<スパン 5. Successfully solvedYour CPU supports instructions that this TensorFlow binary was not compiled to use.あなたのCPUは、このTensorFlowバイナリが使用するためにコンパイルされていない命令をサポートしています。AVX AVX2
先頭行に追加
インポート os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' です。
6. Ubuntuでプロセスが見つからないのに、GPUのメモリがいっぱいになる問題を解決する
Ubuntuシステム がある場合があります。 GPU グラフィックメモリ ディスプレイは満杯ですが、topコマンドもnvidia-smiコマンドもプロセスを見つけることができません。
fuser -v /dev/nvidia* (フューザー)。
前のコマンドでプロセスを検索し、次に
sudo 殺す - 9 PID
プロセスを終了させます。
7. Adversarial-Learning-for-Neural-Dialogue-Generation-in-Tensorflow-revert-10-master プロジェクトの実行に遭遇しました。
まずコードはgithubからフォークされ、誰かからダウンロードされたものです https://github.com/yangjingyingGo/Adversarial-Learning-for-Neural-Dialogue-Generation-in-Tensorflow
彼のreadmeを見てpy2だと思ったのですが、実はpy3なんですね。py3でyangjypyのリモートアカウントにドラッグしても問題ないのですが、py2でyangjypy2にドラッグすると、utilsパッケージのdata_utils.pyファイルが見つからないようなエラーが報告されました。
コードを実行し、多くのバグを発見、これはtensorflowのバージョンの問題である。
8. xrangeなし、py2にはあり、py3はrangeに変更。
9.AttributeError: モジュール 'tensorflow.python.ops.rnn_cell' に属性 '_linear' がない。
ウィル from tensorflow.python.ops import core_rnn_cell
に変更する。 from tensorflow.contrib.rnn.python.ops import core_rnn_cell
10.AttributeError: モジュール 'tensorflow' には 'select' という属性がありません。
tf.selectはtf.whereに変更され、パラメータもすべて同じになりました。
11.AttributeError: モジュール 'tensorflow.python.ops.rnn_cell' に属性 'EmbeddingWrapper' がない。
ウィル rnn_cell.EmbeddingWrapper を core_ に変更する。 rnn_cellを使用します。 エンベッディングラッパー
12.AttributeError: モジュール 'tensorflow.python.ops.nn' に属性 'rnn_cell' がない。
rnn_cell を core_rnn_cell に変更する。
<スパン 13. AttributeError: モジュール 'tensorflow.python.ops.rnn' には属性 'rnn' がありません。
rnn.rnn を rnn.static_rnn に変更する。
14.TypeErrorです。期待されたのは int32 で、代わりに '_Message' 型のテンソルを含むリストが表示されました。
コンソールによると、エラーのある行を探し、パラメータをペアにしてください(関数に間違ったパラメータの位置と型の不一致の問題があるかどうかを確認するために、Ctrl+マウスクリックを試すことができます)。
15.AttributeError: モジュール 'tensorflow' には 'sub' という属性がありません。
subは減算、mulは乗算
16.AttributeError: モジュール 'tensorflow.nn.rnn_cell' に属性 'multiplytiRNNCell' がない。
これは、前回の問題のmulを、一気にmultiplyに置き換えた結果、もともとMultiRNNCellだったのを、multiplytiRNNCellに変更したためで、ワンクリック置換が適さない場合があることを示しています、他のコードに影響を与えず新しい問題を持ち込まないためには一つ一つ変更した方が良いのでしょう
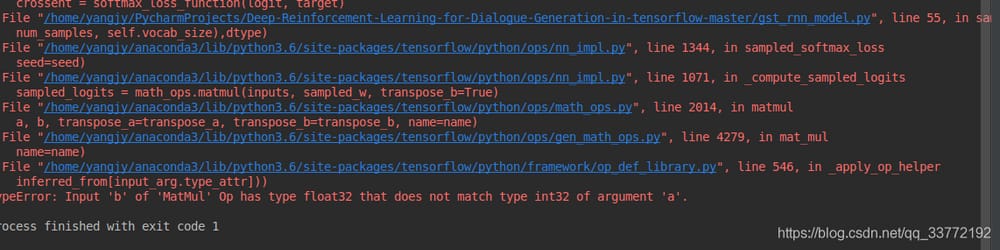
17.TypeError: MatMul' Op の入力 'b' は float32 型ですが、引数 'a' の int32 型と一致しません。
これは問題7と似ていますが、関数の引数の型が一致していないので、引数の位置を入れ替えて、gen_model.pyを変更します。 tf.nn.sampled_softmax_loss メソッドは、ラベルと local_inputs の位置を入れ替える。
18. 特定のgpuで実行するプログラムを指定する方法
インポート <スパン os
os .エンバイロン[ ](英語 CUDA_VISIBLE_DEVICES"。 ] = <スパン "1"
またはGpuの使用率をパーセントで制限する
config = tf.ConfigProto()
config.gpu_options.allow_growth = 1. 真
config.gpu_options.per_process_gpu_memory_fraction = (プロセスごとのgpuメモリの割合) 0.1
19.TypeError。期待されたのは int32 で、代わりに '_Message' 型の Tensor を含むリストを得ました。
エラーのある行を探し、関数のパラメータを入れ替えてください。
<スパン 20.
.
横線の部分をクリックして、コードを見つけ(自分で書いたものであることに注意してください、一般的には何も変更しないでください)、メソッドの2つの変数のうちの1つを入れ替えます、もっと自分で試すことができます。
21.ValueError。Tensor._shapeは代入できません。代わりにTensor.set_shapeを使用してください。
元はcand_symbols._shapeですが、cand_symbolsに変更しました。
22
.
![]()
は、その
![]()
に変更する。
![]()
<スパン 23.tf.nn.raw_rnn AssertionError(アサーションエラー
24.TypeError: type <class 'method'> のオブジェクトをTensorに変換するのに失敗しました。内容: <bound method BeamSearchHelper.loop_fn of <grl_ beam_decoder.BeamSearchHelper object at 0x7f160c40a828>>. 要素をサポートされている型にキャストすることを検討してください。
25.AttributeError: モジュール 'tensorflow.contrib.linalg' には属性 'LinearOperatorTriL' がありません。
LinearOperatorTriL を LinearOperatorLowerTriangular に変更する。
26.'Tensor' オブジェクトには 'to_proto' という属性がありません。
27.TypeError: type <class 'list'> のオブジェクトをTensorに変換するのに失敗しました。内容は以下の通りです。[なし、1]。要素をサポートされている型にキャストすることを検討してください。

position_ind = tf.tile(tf.expand_dims(tf.range(T), 0), [N, 1]) ' を ' position_ind = tf.tile(tf.expand_dims(tf.range(T), 0), [tf.shape(inputs)[0], 1]) ' に変更します.
28.except 例外、e:
<スパン ^
SyntaxError: 構文が無効です。
この問題は、python2 と python3 で構文が異なるためです。
python2 と 3 では except 節の扱いが少し異なるので、注意が必要です。
Python2
try:
print ("hello world")
except ZeroDivisionError, err: # , add the name of the reason parameter
print ('Exception: ', err)
Python3
try:
print ("hello,world")
except ZeroDivisionError as err: # as add the name of the reason argument
print ('Exception: ', err)
if isinstance(h, Variable):
互換性があればasは使えそうですね、シックリきます。 https://blog.csdn.net/DarrenXf/article/details/82957268
29.TypeError:0-dテンソルに対する反復処理
repackage_hiddenでtypeの代わりにisinstanceofを使用するのが答えだと思います。
元の if 文を次のように置き換えます。
if isinstance(h, Variable):
30.IndexError: 0-dimのテンソルのインデックスが無効です。0-dimのテンソルをPythonの数値に変換するにはtensor.item()を使用します。
追加 .item()
31.tensorflow.python.framework.errors_impl.InternalError: セッションの作成に失敗しました。
GPUメモリがない
32. AttributeError: モジュール 'string' には 'maketrans' という属性がありません。
string.maketrans() を str.maketrans() に変更し、もし str.maketrans() が translate() の引数であれば、他の引数には
33. 無効な引数です。TensorSliceReaderのコンストラクタに失敗しました。model/modelでマッチングファイルの取得に失敗しました。見つかりませんでした。FindFirstFile failed for: model : ϵͳ Ҳ ָ - ; No such process
学習パラメータが正しく設定されていないため、プログラムが学習モデルではなく、テストモデルを行っていると判断している可能性があります。例えば、いくつかのパラメータをpredict=trueからpredict=trueに変更し、train関数とmain関数を見てみてください。
34. TypeError: __init__() は予期しないキーワード引数 'tensor_type' を受け取りました。
torchtext のバージョンを 0.2.3 にダウングレードしました。
35. TypeError: stack(): argument 'tensors' (position 1) must be tuple of Tensors, not Tensor
出力を置く = torch.stack(outputs)
へ
outputs = torch.stack(list(outputs))
36.AttributeError: 'module' オブジェクトには 'BufferedIOBase' という属性がありません。
このパッケージをファイルの最初の数行に追加します。
インポート io
元のimport ioパッケージを削除する
37.InvalidArgumentError (トレースバックは上記を参照): indices[14,21] = 608 は [0, 603] に含まれない。
このエラーは、インデックス「608」がエンベッディングマトリックスのエンベッディングにないためです。おそらく「vocab_size」語彙のサイズが間違っています。語彙のサイズが正しいかどうか、エンベッディングレイヤーの最初の次元は語彙のサイズ、2番目はembedding_sizeになります。
38. tensorflowのバージョンをアップグレードする
gpuのバージョン。
pip install --upgrade tensorflow-gpu
cpuのバージョンです。
pip install-upgrade tensorflow
40.ZeroDivisionError: 分数(0, 0)
<スパン 41. ARNING:tensorflow:Issue encountered when serializing global_step.
<スパン maxseqやbatch_numなど他の変数やdataloader.pyを確認する必要があります。
42. 2つの異なるシステムで実験を行うことが多く、それらの間で繰り返しデータを転送する必要があるため、linuxのコマンドであるscp
ファイルのコピー
ローカルファイルをリモートへコピー
scp ファイル名 - ユーザー名@コンピュータのIPまたはコンピュータ名:リモートパス
リモートロケーションからローカルロケーションにファイルをコピーして戻す
scp -username@computer IPまたはコンピュータ名:ファイル名 ローカルパス
コマンドの書式
scp local_file remote_username@remote_ip:remote_folder
または
scp local_file remote_username@remote_ip:remote_file。
または
scp local_file remote_ip:remote_folder
または
scp local_file remote_ip:remote_file
ディレクトリの複製
ローカルディレクトリをリモートにコピーする
scp -r ディレクトリ名 username@computer IP またはコンピュータ名:リモートパス
ディレクトリをリモートからローカルにコピーする
scp -r ユーザー名@コンピュータ IPまたはコンピュータ名:ディレクトリ名 ローカルパス
コマンドの書式
scp -r local_folder remote_username@remote_ip:remote_folder
または
scp -r local_folder remote_ip:remote_folder
43.トレーニング時の損失=NaN
1.学習率が高すぎる、下げてみてください、0まで下げても良いので
2. 学習率を下げたり、ナンならシード設定をランダムにして、ネットワークそのものを
3.学習回数を5000回に増やしてみて、パラメータを1つだけにして、手動でkill offして、微調整することができる
44.tf.map_fn
0次元の要素から展開されたテンソルのリストに対するマッピング。
map_fn(
fnを使用します。
elems,
dtype=None です。
parallel_iterations=10,
back_prop=Trueです。
swap_memory=False とする。
infer_shape=Trueを指定します。
名前=なし
)
fn:呼び出し可能な実行。その出力はdtypeと同じ構造でなければなりません(提供された場合)、そうでなければそれはelemsと同じ構造を持っている必要があります。
elems: テンソルまたはテンソルの(入れ子になった可能性のある)シーケンス。生成されたスライスのネストされたシーケンスは fn に適用される。
使用方法
1. map_fn の最も単純なバージョンは、呼び出し可能な fn を最初から最後までの一連の要素に繰り返し適用します。これらの要素は elems で展開されたテンソルからなる。たとえば
elems = np.array([1、2、3、4、5、6])
squares = tf.map_fn(lambda x: x * x, elems)
# squares == [1, 4, 9, 16, 25, 36].
elems = (np.array([1, 2, 3]), np.array([-1, 1, -1]))
alternate = tf.map_fn(lambda x: x[0] * x[1], elems, dtype=tf.int64)
# alternate == [-1, 2, -3].
elems = np.array([1、2、3])
alternates = tf.map_fn(lambda x: (x, -x), elems, dtype=(tf.int64, tf.int64))
# alternates[0] == [1, 2, 3].
# alternates[1] == [-1, -2, -3].
2.
def integrate(integrate_input):
Xy = integrate_input[0] です。
Yx = integrate_input[1] です。
assert dimensions_equal(Xy.shape, (max_len, dim,))
assert dimensions_equal(Xy.shape, (max_len, dim,))
出力 = tf.concat([Xy,Yx],1)
出力を返す
#imputs1,inputs2 の形状が [batch_size,max_len,dim] である場合。
#map_fn は inputs1,inputs2 を次元 0 で展開する。
#Xy の形状は integrate が実行されるたびに [max_len, dim] となります。
出力 = tf.map_fn(integrate, (inputs1, inputs2))
元の記事 https://blog.csdn.net/u013250410/article/details/84727641
45.tf.scatter_nd
scatter_nd(indices,updates,shape,name=None)
インデックスに基づく新しい(最初はゼロの)テンソルに更新を散布します.
与えられた形状のゼロテンソル内の単一の値またはスライスに、インデックスに基づく疎な更新を適用することによって、新しいテンソルを作成する。この演算子は tf.gather_nd 与えられたテンソルから値またはスライスを抽出する演算子の逆数である。
警告 更新の適用順序は非決定的であるため、インデックスに重複する項目がある場合、出力は不定になる。
indicesは新しいshapeテンソルを形成するインデックスを含む整数テンソルである。indicesの最後の次元はshapeの最上位であることができる。
indices.shape[-1] <= shape.rank
indicesの最後の次元は、indices.shape[-1]次元の形状に沿った要素のインデックス(indices.shape[-1] = shape.rank の場合)またはスライスのインデックス(indices.shape[-1] < shape.rank の場合)に相当する。 updatesは以下の形状を有するテンソルである。
indices.shape[:-1] + shape[indices.shape[-1]:]である。
分散の最も単純な形は、個々の要素をインデックスごとにテンソルに挿入することである。例えば、8個の要素からなるレベル1テンソルに4個の分散要素を挿入したいとする。

Pythonでは、このscatterの操作は次のようになります。
インデックス = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
形状 = tf.constant([8])
scatter = tf.scatter_nd(indices, updates, shape)
をtf.Session()をsessとした場合。
print(sess.run(scatter))
結果として、テンソルは次のようになる。
[0, 11, 0, 10, 9, 0, 0, 12]
また、高次のテンソルのスライス全体を一度に挿入することも可能である。例えば、行列の3次元テンソルに2つのスライスを挿入し、新しい値を2つ挿入したい場合。
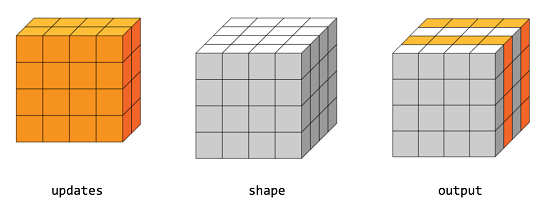
Pythonでは、このscatterの操作は次のようになります。
インデックス = tf.constant([[0], [2]])
updates = tf.constant([[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]],
[[5, 5, 5, 5], [6, 6, 6, 6],
[7, 7, 7, 7], [8, 8, 8, 8]]])
shape = tf.constant([4, 4, 4])
scatter = tf.scatter_nd(indices, updates, shape)
をtf.Session()をsessとした場合。
print(sess.run(scatter))
結果として、テンソルは次のようになる。
[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
[[0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0]],
[[5, 5, 5, 5], [6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8]],
[[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0]]]
関数パラメータ
indices: Tensor; int32, int64 のいずれかである必要がある。
updates: a Tensor; 更新を出力するために散在している。
shape: テンソル; indicesと同じ型でなければならない; 1-d; 結果として得られるテンソルの形状を表す。
name: 操作の名前(オプション)。
関数の戻り値
この関数は、updateと同じ型のTensorを返す。与えられた形状を持つ新しいTensorと、indexにしたがって適用されるupdateである。
元記事 https://blog.csdn.net/zlrai5895/article/details/80551056
46.tensorflow.python.framework.errors_impl.InvalidArgumentError: 操作 tower_0/encoder/num_blocks_0/ multihead_attention/dense/Tensordot/GatherV2 に対してデバイスを割り当てることができません。デバイス指定 '/device:GPU:0' を満たせませんでした。登録されたカーネルに対応したカーネルがないためです。
回避策:セッションは、allow_soft_placement=Trueを重視して、sessとしてtf.Session(config=tf.ConfigProto(allow_soft_placement=True))で読み取ります。
47. osという名前のモジュールがない
.bashrc ファイル内の以前のインストールから残っている Python パスを削除またはコメントアウトし、最新のインストールからのパスだけを残します。
RuntimeError: CUDAデバイス上でオブジェクトのデシリアライズを試みていますが、torch.cuda.is_available()がFalseです。もしCPUのみのマシンで動作しているのであれば、torch.load with map_location=torch.device('cpu') を使ってストレージをCPUにマップしてください。
コード内のすべてのcudaコードをコメントアウトし、torch.load()メソッドを見つけ、そこにmap_location=torch.device('cpu')を追加してください。
49.RuntimeError: groups=1, weight of size 64 1 3 3 が与えられたとき、input[1, 3, 521, 694] が 1 チャンネルであると期待したが、代わりに 3 チャンネルを得た。
入力データのコード部分を探し、データの寸法(通常は[width, height, channels])を表示し、channelsの値がエラーで要求されたものと同じでないかを確認し、変更する。
関連
-
[解決済み】Tensorflowは、Path変数が設定された状態でインストールされているにもかかわらず、「cudart64_90.dll」を見つけることができません。
-
[解決済み】Cuda 9.0とcudnn 7.1と互換性のあるtensorflowのバージョンはありますか?
-
[解決済み] Tensorflowです。tf.expand_dimsはいつ使うの?
-
[解決済み] モジュール 'tensorflow' には 'logging' という属性がありません。
-
[解決済み] ModuleNotFoundError: tensorboard' という名前のモジュールはありません。
-
[解決済み] TensorflowとKerasを使用して、学習精度よりも高い検証精度を実現。
-
解決方法 TensorFlowのネイティブランタイムのロードに失敗しました。
-
ImportError: cannot import name 'get_config' How to solve this problem?
-
AttributeError: モジュール 'tensorflow'に属性 'placeholder' がない問題
-
Bishopの問題2: tf-pose-estimation-master, last ModuleNotFoundError: tensorflow.contrib'という名前のモジュールがありません(解決済み)。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] tensorboard: コマンドが見つかりません。
-
[解決済み] なぜtf.name_scope()を使うのか?
-
[解決済み] WSL2- $nvidia-smi コマンドが実行されない
-
[解決済み] tf.nn.reluの "relu "とは何の略ですか?
-
デバイスから 18.41M (19300352 bytes) の割り当てに失敗しました。CUDA_ERROR_OUT_OF_MEMORY
-
AttributeError: 'list' オブジェクトには 'value' という属性がありません。
-
tensorflow ステップピットシェア。AttributeError: モジュール 'tensorflow' には属性 'xxx' がありません。
-
AttributeError: モジュール 'tensorflow' には 'placeholder' という属性がないことを解決する。
-
Tensorflowは、'_pywrap_tensorflow_internal'という名前のモジュールがないことを解決する。
-
tf.convert_to_tensorを使用したときの値のエラーの解決方法