[解決済み] TensorflowとKerasを使用して、学習精度よりも高い検証精度を実現。
2022-02-11 19:51:56
質問
出会い系サイトで自己申告した15の属性から、ディープラーニングを使って収入を予測しようとしています。
トレーニングデータよりも検証データの方が精度が高く、損失が少ないという、かなり奇妙な結果が出ています。これは、隠れ層の大きさが変わっても同じです。 これが我々のモデルです。
for hl1 in [250, 200, 150, 100, 75, 50, 25, 15, 10, 7]:
def baseline_model():
model = Sequential()
model.add(Dense(hl1, input_dim=299, kernel_initializer='normal', activation='relu', kernel_regularizer=regularizers.l1_l2(0.001)))
model.add(Dropout(0.5, seed=seed))
model.add(Dense(3, kernel_initializer='normal', activation='sigmoid'))
model.compile(loss='categorical_crossentropy', optimizer='adamax', metrics=['accuracy'])
return model
history_logs = LossHistory()
model = baseline_model()
history = model.fit(X, Y, validation_split=0.3, shuffle=False, epochs=50, batch_size=10, verbose=2, callbacks=[history_logs])
そして、これが精度と損失の例です。
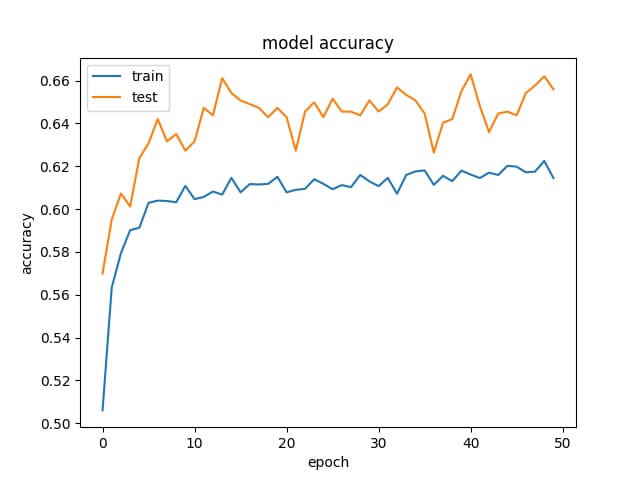 と
と
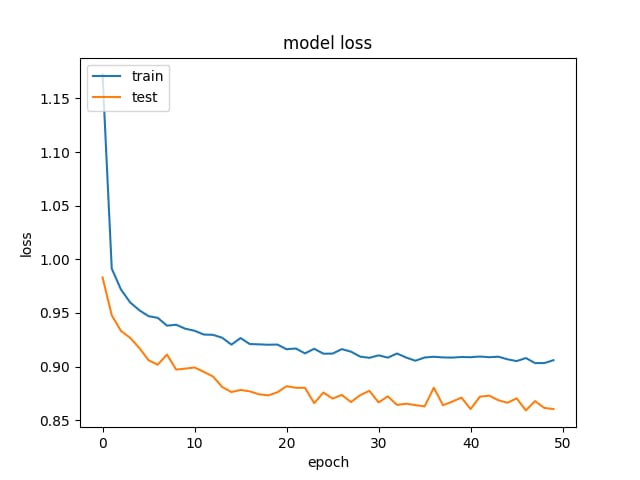 .
.
正則化とドロップアウトを除去してみましたが、予想通りオーバーフィッティングになってしまいました(学習acc:〜85%)。さらに、学習率を極端に下げてみたが、同様の結果となった。
同じような結果を見たことがある方はいらっしゃいますか?
解決方法は?
を使用すると、このようなことが起こります。
Dropout
というのは、学習時とテスト時の動作が異なるからです。
学習時には、一定割合の素性がゼロに設定されます(あなたの場合は
Dropout(0.5)
). テスト時には、すべての特徴が使用されます(そして、適切にスケーリングされます)。そのため、テスト時のモデルはより堅牢になり、テストの精度を高めることができます。
関連
-
[解決済み】Tensorflowは、Path変数が設定された状態でインストールされているにもかかわらず、「cudart64_90.dll」を見つけることができません。
-
[解決済み】Tensorflow: ImportError: libcusolver.so.8.0: cannot open shared object file: No such file or directory
-
[解決済み] tensorflowの名前スコープと変数スコープの違いは何ですか?
-
[解決済み] tf.train.shuffle_batchはどのように動作するのですか?
-
AttributeError: モジュール 'tensorflow'には属性がありません。
-
使用Amazon AWS搭建GPU版tensorflow深度学习环境
-
tensorflow CUDA_ERROR_ILLEGAL_ADDRESSの解決法(Windows版)。
-
[解決済み] Kerasでモデルウェイトを保存する:モデルウェイトとは?
-
[解決済み] TensorFlow SparseCategoricalCrossentropyはどのように機能するのですか?
-
エラーの解決 InvalidArgumentError: Can not squeeze dim[1], expected a dimension of 1, got
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】ImportError: 名前 'abs' をインポートすることができません。
-
[解決済み】Tensorflow: tf.expand_dimsはいつ使う?
-
[解決済み】Tensorflowは、Path変数が設定された状態でインストールされているにもかかわらず、「cudart64_90.dll」を見つけることができません。
-
[解決済み】TensorFlowでtf.get_collection()を理解する方法
-
[解決済み] tensorflowの名前スコープと変数スコープの違いは何ですか?
-
[解決済み] tensorflowの.pbと.pbtxtの違い?
-
解決方法 TensorFlowのネイティブランタイムのロードに失敗しました。
-
Solve ImportError: libcublas.so.10.0: 共有オブジェクト・ファイルを開くことができません。そのようなファイルまたはディレクトリがありません
-
pip installs tensorflow with an error ERROR: OSErrorのため、パッケージをインストールできませんでした。[Errno 2] そのようなファイルやディレクトリはありません。
-
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"] = "0"