'Tensor' オブジェクトには 'numpy' という属性がありません。
2022-02-26 21:31:38
多層パーセプトロンを実装する場合
import tensorflow as tf
import numpy as np
#implement a simple DataLoader class to read MNIST dataset data
class DataLoader():
def __init__(self):
mnist = tf.contrib.learn.datasets.load_dataset("mnist")
self.train_data = mnist.train.images
self.train_labels = np.asarray(mnist.train.labels,dtype=np.int32)
self.eval_data = mnist.test.images
self.eval_labels = np.asarray(mnist.test.labels,dtype=np.int32)
def get_batch(self,batch_size):
index = np.random.randint(0,np.shape(self.train_data)[0],batch_size)
return self.train_data[index,:],self.train_labels[index]
class MLP(tf.keras.Model):
def __init__(self):
super(). __init__()
self.dense1 = tf.keras.layers.Dense(units=100,activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self,inputs):
x=self.dense1(inputs)
x=self.dense2(x)
return x
def predict(self,inputs):
logits = self(inputs)
return tf.argmax(logits,axis=-1)
# Define some model hyperparameters
num_batches = 1000
batch_size = 50
learning_rate = 0.001
#Instantiate the model, data reading class and optimizer
model = MLP()
data_loader = DataLoader()
optimizer = tf.train.AdadeltaOptimizer(learning_rate = learning_rate)
# specific code
for batch_index in range(num_batches):
X,y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_logit_pred = model(tf.convert_to_tensor(X))
loss = tf.losses.sparse_softmax_cross_entropy(labels=y,logits=y_logit_pred)
print("batch %d:loss %d"%(batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads,model.variables))
# validation set to test the model performance
num_eval_samples = np.shape(data_loader.eval_labels)[0]
y_pred = model.predict(data_loader.eval_data).numpy()
print("test accuracy:%f"%(sum(y_pred == data_loader.eval_labels)/num_eval_samples))
次のようなエラーが報告されます。
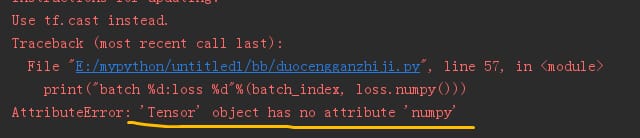
を追加することができます。
tf.enable_eager_execution(
config=None,
device_policy=None,
execution_mode=None
)
これは問題を解決する
---------- ---------- -----
20201218 更新しました。
どのコードがどこに掲載されているかわからない人がいるので、フルコードを掲載するように書き換える
import tensorflow as tf
import numpy as np
tf.enable_eager_execution(
config=None,
device_policy=None,
execution_mode=None
)
# Implement a simple DataLoader class to read MNIST dataset data
class DataLoader():
def __init__(self):
mnist = tf.contrib.learn.datasets.load_dataset("mnist")
self.train_data = mnist.train.images
self.train_labels = np.asarray(mnist.train.labels,dtype=np.int32)
self.eval_data = mnist.test.images
self.eval_labels = np.asarray(mnist.test.labels,dtype=np.int32)
def get_batch(self,batch_size):
index = np.random.randint(0,np.shape(self.train_data)[0],batch_size)
return self.train_data[index,:],self.train_labels[index]
class MLP(tf.keras.Model):
def __init__(self):
super(). __init__()
self.dense1 = tf.keras.layers.Dense(units=100,activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self,inputs):
x=self.dense1(inputs)
x=self.dense2(x)
return x
def predict(self,inputs):
logits = self(inputs)
return tf.argmax(logits,axis=-1)
# Define some model hyperparameters
num_batches = 1000
batch_size = 50
learning_rate = 0.001
#Instantiate the model, data reading class and optimizer
model = MLP()
data_loader = DataLoader()
optimizer = tf.train.AdadeltaOptimizer(learning_rate = learning_rate)
# specific code
for batch_index in range(num_batches):
X,y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_logit_pred = model(tf.convert_to_tensor(X))
loss = tf.losses.sparse_softmax_cross_entropy(labels=y,logits=y_logit_pred)
print("batch %d:loss %d"%(batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads,model.variables))
# validation set to test the model performance
num_eval_samples = np.shape(data_loader.eval_labels)[0]
y_pred = model.predict(data_loader.eval_data).numpy()
print("test accuracy:%f"%(sum(y_pred == data_loader.eval_labels)/num_eval_samples))
結果
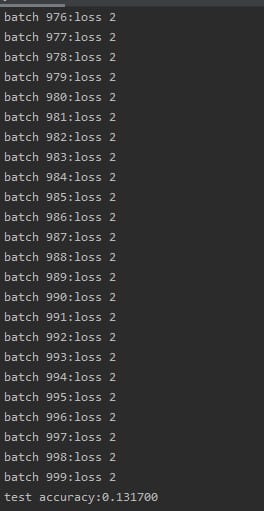
関連
-
[解決済み】TensorFlowでtf.get_collection()を理解する方法
-
[解決済み] tf.global_variables_initializerは何のためにあるのですか?
-
[解決済み] ModuleNotFoundError: tensorboard' という名前のモジュールはありません。
-
[解決済み] Tensorflowにおけるglobal_stepの意味とは?
-
AttributeError: 'list' オブジェクトには 'value' という属性がありません。
-
AttributeError: モジュール tensorflow には属性プレースホルダーがありません。
-
AttributeError: モジュール 'tensorflow' には 'placeholder' という属性がないことを解決する。
-
tf.convert_to_tensorを使用したときの値のエラーの解決方法
-
AttributeError: 'NoneType' オブジェクトに属性がない...... エラー解析
-
tensorflow-GPUのグラフィックカードのメモリ不足の問題
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Tensorflowのエラー.TypeError: ハッシュ化できない型:'numpy.ndarray'
-
[解決済み] 入力パイプラインは、keras.utils.Sequenceオブジェクトまたはtf.data.Datasetを使用しますか?
-
解決方法 TensorFlowのネイティブランタイムのロードに失敗しました。
-
モジュール 'matplotlib' には、解決すべき属性 'configure' がありません。
-
Tensorflowのエラーです。TypeError: 'NoneType'オブジェクトは呼び出し可能ではない
-
2021年最新。TensorFlow各GPUバージョン CUDAとcuDNN対応バージョン照合(最も簡潔なもの)。
-
tensorflow import error ModuleNotFoundError: モジュール名 '_pywrap_tensorflow_internal' がありません。
-
使用Amazon AWS搭建GPU版tensorflow深度学习环境
-
[解決済み] tf.train.latest_checkpoint はチェックポイントパスを渡すと none を返す。
-
[解決済み] Kerasでモデルウェイトを保存する:モデルウェイトとは?