テーブル変数によるSQL実行効率低下の記録
シナリオ
最近仕事で、同期型のJOBが実行中にSQL実行タイムアウトをよく起こすことがわかり、ログを見ると、各SQLの実行時間が直線的に増加し、ループで50回実行すると実行時間が5分を超えることさえあることが判明した
JOB実行フロー解析
まず、JOBフローを解析し、JOB設計に問題がないかを確認します
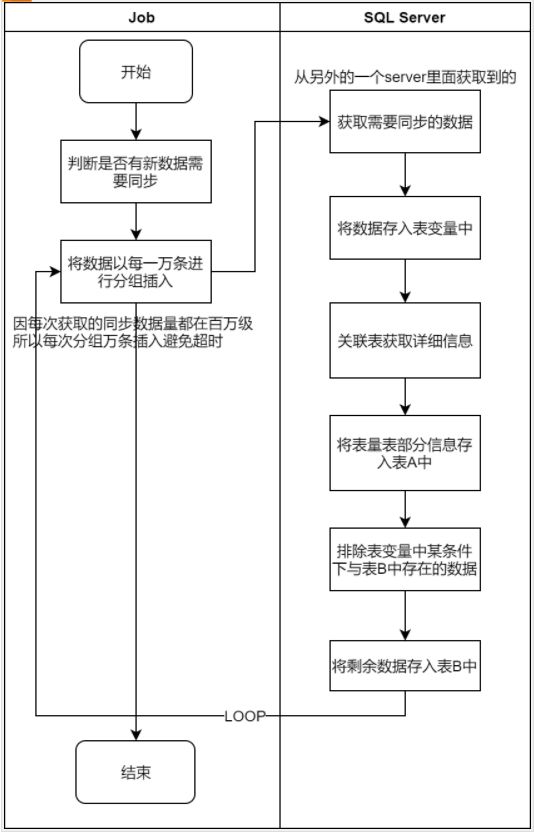
処理を解析した結果、同期が必要なデータ数は1回のフェッチで最大1万件程度であり、大きなデータの書き込みでタイムアウトが発生するような問題はないことがわかりました。
次に、詳細情報を取得する処理を分析すると、関連するテーブルのデータが最も多いもので億単位であり、これがSQL全体の実行速度を低下させていると思われます。これは怪しいポイント1といえるでしょう。
ループの実行に伴い、テーブルBのデータ量が増えているため、ループ下で実行時間が直線的に増加している主な理由ではないでしょうか?
問題を一つずつ解決していくトラブルシューティング
以前、JOBの実行フローを解析して怪しい点が2つ見つかったので、今度は具体的にSQLを解析する
CREATE TABLE #TableTemp (
Field A int null,
Field B int null,
Field C int null
)
INSERT INTO #TableTemp(
fieldA,
Field B
) SELECT
a.Field A,
fieldB
FROM ServerA.dbo.TableB a WITH(NOLOCK)
LEFT JOIN dbo.TableA b WITH(NOLOCK) a.Id = b.Id
UPDATE a
SET a.Field C = b.Field D
FROM #TableTemp a
LEFT JOIN dbo.TableC b WITH(NOLOCK) ON a.Field A = b.id
INSERT INTO dbo.TargetTableA(
Field A,
Field B
)
SELECT
fieldA,
Field B
FROM #TableTemp WITH(NOLOCK)
INSERT INTO dbo.TargetTableB(
fieldA,
Field B,
Field C
)
SELECT DISTINCT
a.fieldA,
a.fieldB,
a.Field C
FROM #TableTemp a WITH(NOLOCK)
LEFT JOIN dbo.TargetTableB b ON a.FieldA = b.FieldA AND a.FieldB = b.FieldB
WHERE a.PK IS NULL
まず、怪しい点1、ここに問題はないかを確認しましょう。というのも、TableCのデータはすでに数億円ですが、SQLの実行だけではインデックスがあるため特に遅くはないので、問題を除外することができるのです
では、怪しい点2を見てみましょう
INSERT INTO dbo.TargetTableB(
fieldA,
Field B,
Field C
)
SELECT DISTINCT
a.fieldA,
a.fieldB,
a.Field C
FROM #TableTemp a WITH(NOLOCK)
LEFT JOIN dbo.TargetTableB b ON a.FieldA = b.FieldA AND a.FieldB = b.FieldB
WHERE a.PK IS NULL
あなたは、SQLは、同じデータが条件の下で存在するかどうかもクエリ自体を同時に挿入することがわかりますが、テーブルをチェック対象TableBは、テーブルが主キーもインデックスを持っていないことがわかったし、DBA側が提供するSQL分析を通じて、このSQLのdbo。 TableBフルテーブルのスキャン1w回、より多くのデータ、実行時間は長く、長くなっているテーブルのサイクルの実行として、それはここに実行時間の線形増加の主因のようだ。

問題を解決する
上記のトラブルシューティングから、1wのフルテーブルスキャンを行うとSQLの実行に時間がかかりすぎるため、あまり多くのフルテーブルスキャンを行わないことが問題解決のポイントであることがわかりました。つまり、最も直接的な解決策は、フルテーブルスキャンを回避するためのインデックスを作成することです
1. テーブル変数の代わりにテンポラリテーブルを使用することで
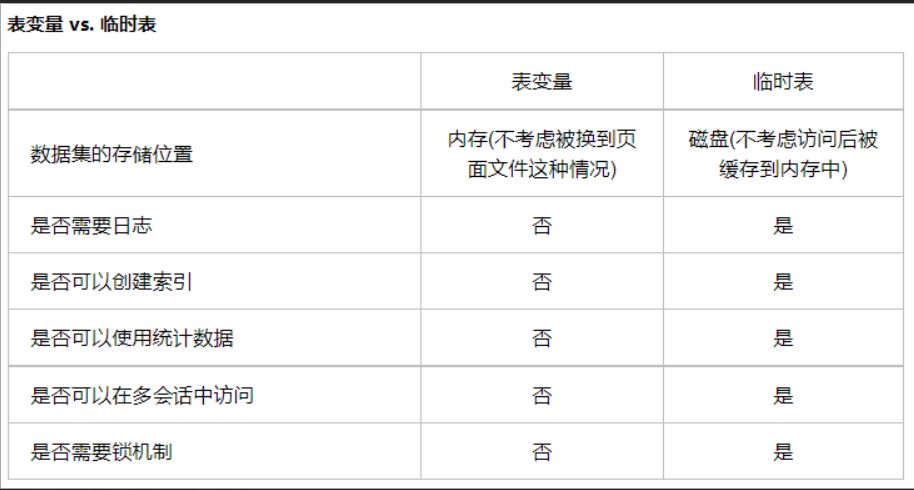
まず、テーブル変数とテンポラリテーブルの違いについて見てみましょう。テーブル変数はインデックスを使用できないことがわかります。したがって、フルテーブルスキャンを避けるためにインデックスを使用したい場合は、テーブル変数を置き換える必要があり、次にテンポラリテーブルのフィールドAにインデックスを作成します。
2. 対象TableBへの書き込みロジックを変更する
既存の書き込みロジックは、まずターゲットTableBに存在するかどうかを判断し、存在しない場合はテーブルに書き込まれますが、ビジネスケースを考慮して、書き込み前にターゲットTableBのデータを除外し、残りのデータをテーブルに書き込むようにロジックを若干修正し、ターゲットTableBのテーブルクエリを1W回繰り返すことを回避できるようにします。
この2つの変更後、JOBを再度実行すると、問題は完全に解決しました。
概要
テーブル変数によるSQLの実行効率低下については、この記事が全てです。テーブル変数によるSQL実行効率低下については、スクリプトハウスの過去記事を検索していただくか、引き続き以下の関連記事をご覧ください。
関連
-
DataGrip データエクスポート/インポート実装例
-
MySQLとRedisがデータの一貫性を確保する方法について説明します。
-
Navicat for SQLite インストールチュートリアル(インストールキット付き
-
DeepinV20 Mariadbのクイックインストールを詳しくご紹介します。
-
SQLインジェクションの実装と防止事例を解説
-
SQL実行エンジンを自作する方法
-
SQLyogダウンロード、インストール超詳細チュートリアル(プロテスト永久保存版)
-
Dbeaverを使ったHiveへのリモート接続の詳細方法
-
Navicat Premium 12でOracleに接続する際にoracle library is not loadedと表示される問題の解決
-
SQLにおけるwhereとhavingの違いについて解説します
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
JetBrains DataGripのインストールと使用に関する詳細なチュートリアル
-
ナビカット15のインストールチュートリアルを超詳しく解説(一番信頼できるのはこれ)
-
JMeterデータベースクエリ操作手順詳細説明
-
データベース管理ツール「Navicat」と「DBeaver」を一挙に読む
-
SQLインジェクションの例とその解決方法
-
CentOS 8.2上のCouchDB 3.3データベースを展開する方法
-
データベースクエリタイムアウト最適化問題の実践記録
-
SQLリレーショナルモデルの知識まとめ
-
タイプインジェクションとコミットインジェクションのSQLインジェクションチュートリアル
-
ユニークSQLの原理と応用を解説