[解決済み】Spark StandaloneクラスタのWorker、Executor、Coreとは何ですか?
質問
読む クラスター・モードの概要 の処理の違いについて、まだ理解できていません。 Sparkスタンドアロンクラスタ と並列化されています。
WorkerはJVMプロセスなのかどうか?を実行しました。
bin\start-slave.sh
を実行すると、Workerがスポーンされることがわかりましたが、これは実際にはJVMです。
上記のリンクにあるように、エグゼキュータとはワーカーノード上でアプリケーションのために起動され、タスクを実行するプロセスのことです。エクゼキュータはJVMでもあります。
以上が私の質問です。
-
エグゼキュータはアプリケーション単位です。では、ワーカーの役割は何でしょうか。ワーカーはエクゼキュータと協調して、その結果をドライバに伝えるのでしょうか? それとも、ドライバが直接エクゼキュータに話しかけるのでしょうか?もしそうなら、ワーカーの目的は何でしょうか?
-
アプリケーションのエグゼキューター数を制御するには?
-
エグゼキュータ内部でタスクを並列に実行させることはできますか?その場合、エクゼキュータのスレッド数はどのように設定するのですか?
-
ワーカー、エグゼキュータ、エグゼキュータコア(-total-executor-cores)の関係は?
-
ノードあたりのワーカー数が多いとはどういう意味ですか?
更新
例題を挙げて、理解を深めていきましょう。
例1: 5つのワーカーノードを持つスタンドアロンクラスタ(各ノードは8コアを持つ) デフォルトの設定でアプリケーションを起動すると
例2 例1と同じクラスタ構成ですが、以下の設定でアプリケーションを実行します。 --エグゼキュータコア 10 -total-executor-cores 10.
例3 例1と同じクラスタ構成ですが、以下の設定でアプリケーションを実行します。 --エグゼキュータコア 10 -total-executor-cores 50.
例4 例1と同じクラスタ構成ですが、以下の設定でアプリケーションを実行します。 --エグゼキュータコア 50 -total-executor-cores 50.
例5 例1と同じクラスタ構成ですが、以下の設定でアプリケーションを実行します。 --エグゼキュータコア 50 -total-executor-cores 10.
それぞれの例で エクゼキュータの数は?各エクゼキュータあたりのスレッド数は?コア数は? アプリケーションごとに実行者の数はどのように決められますか?ワーカーの数と常に同じですか?
どのように解決するのですか?
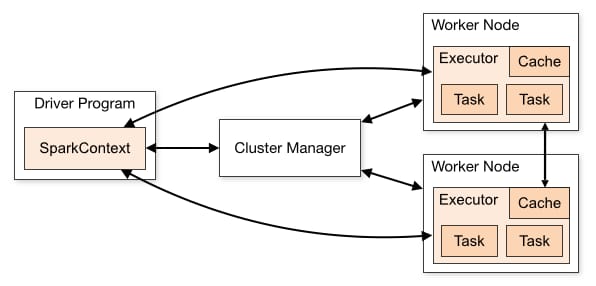
Sparkはマスター/スレーブアーキテクチャを採用しています。図にあるように、1つの中央コーディネータ(Driver)があり、多数の分散ワーカー(Executor)と通信します。ドライバと各エクゼキュータは、それぞれ独自のJavaプロセスで実行されます。
ドライバ
ドライバは、メインメソッドが実行されるプロセスである。まず、ユーザープログラムをタスクに変換し、その後、タスクをエグゼキュータにスケジューリングします。
エクセキューター
エグゼキュータは、Sparkジョブ内の個々のタスクの実行を担当するワーカーノードのプロセスです。Sparkアプリケーションの開始時に起動され、通常、アプリケーションのライフタイム全体にわたって実行されます。タスクが実行されると、その結果をドライバに送ります。また、ブロックマネージャーを通じてユーザープログラムによってキャッシュされるRDDのインメモリーストレージを提供します。
アプリケーション実行フロー
これを踏まえて、spark-submitでアプリケーションをクラスタに投入すると、内部では次のようなことが行われます。
-
スタンドアロン・アプリケーションは、起動とインスタンス化により
SparkContextインスタンスを作成します(そして、このとき初めてアプリケーションをドライバと呼ぶことができるようになります)。 - ドライバプログラムは、クラスタマネージャにリソースを要求し、エグゼキュータを起動します。
- クラスタマネージャがエグゼキュータを起動する。
- ドライバプロセスは、ユーザーアプリケーションを介して実行されます。RDD上のアクションと変換に応じて、タスクがエグゼキュータに送信されます。
- エグゼキュータはタスクを実行し、結果を保存する。
- ワーカーがクラッシュした場合、そのタスクは別のエグゼキュータに送られ、再度処理されます。書籍「quot;Learning Spark: Lightning-Fast Big Data Analysis"では、SparkとFault Toleranceについて述べられています。
Sparkは、故障したマシンや遅いマシンに自動的に対処し、故障したタスクや遅いタスクを再実行します。例えば、map()操作のパーティションを実行しているノードがクラッシュした場合、Sparkはそれを別のノードで再実行します。また、ノードがクラッシュせず、単に他のノードよりはるかに遅い場合でも、Sparkは他のノードでタスクの「投機的」コピーを先取りして起動し、それが終了したらその結果を取得することができます。
- ドライバから SparkContext.stop() を実行するか、メインメソッドが終了/クラッシュすると、すべてのエグゼキュータが終了し、クラスタリソースはクラスタマネージャによって解放されます。
ご質問
-
実行者は起動時にドライバに登録し、それ以降は直接通信を行います。Worker はクラスタマネージャに自分のリソースが利用可能かどうかを伝える役割を果たします。
-
YARNクラスタでは、--num-executorsでそれを行うことができます。スタンドアロンクラスタでは、spark.executor.cores を使って Worker が複数の executor を保持するのに十分なコアを持たない限り、1 ワーカーにつき 1 つの executor が取得されます。(@JacekLaskowski が指摘したように、YARN では --num-executors は使われなくなりました。 https://github.com/apache/spark/commit/16b6d18613e150c7038c613992d80a7828413e66 )
-
エグゼキューターごとにコア数を割り当てるには、--executor-coresを使用します。
-
-total-executor-coresは、アプリケーションごとの実行コアの最大数です。
-
Sean Owenがこの中で言っているように スレッド : "1台のマシンに複数のワーカーを実行する良い理由はありません" 。たとえば、1台のマシンに多数のJVMがあるような場合です。
アップデイト
このシナリオをテストできていないのですが、ドキュメントによると
例1: Sparkはスケジューラから提供されたコアとエグゼキュータを貪欲に獲得していきます。そのため、最終的には8コアずつの5つのエグゼキュータを取得することになります。
例2~例5 Spark は 1 つのワーカーに要求されただけのコアを割り当てることができないため、エグゼキュータが起動しません。
関連
-
[解決済み] SparkでcreateOrReplaceTempViewはどのように動作するのですか?
-
[解決済み] Spark が "java.net.URISyntaxException" を報告するのはなぜですか?DataFrameを使用する際に「java.net.URIStyntaxException: Relative path in absolute URI」と表示されるのはなぜですか?
-
[解決済み] format("kafka") で "Failed to find data source: kafka." とエラーになるのはなぜですか?(uber-jarを使用しても)失敗しますか?
-
[解決済み] Sparkクラスタがハートビートのタイムアウトでいっぱいになり、エグゼキュータが勝手に終了してしまう。
-
[解決済み] Sparkのバージョンを確認する方法【終了しました
-
[解決済み] スパークジョブとは?
-
[解決済み] 実行中のSparkアプリケーションを終了させるには?
-
[解決済み] Spark - repartition() vs coalesce()
-
[解決済み】Spark StandaloneクラスタのWorker、Executor、Coreとは何ですか?
-
[解決済み] 複数のテキストファイルを1つのRDDに読み込むには?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】spark.driver.maxResultSizeとは何ですか?
-
[解決済み] スパーク "プランの文字列表現が大きすぎたため、切り捨てました。" 手動で作成した集計式を使用した場合の警告
-
[解決済み] Spark が "java.net.URISyntaxException" を報告するのはなぜですか?DataFrameを使用する際に「java.net.URIStyntaxException: Relative path in absolute URI」と表示されるのはなぜですか?
-
[解決済み] Apache SparkとAkkaの比較【終了しました
-
[解決済み] spark 2.4.4 をインストールした後に pyspark を実行しようとすると、「TypeError: an integer is required (got type bytes)」というエラーが発生するのを修正する方法
-
[解決済み] Sparkのバージョンを確認する方法【終了しました
-
[解決済み] spark checkpointとpersist to a diskの違いは何ですか?
-
[解決済み] TypeError: 'Column' オブジェクトは WithColumn を使用して呼び出すことができません。
-
[解決済み】Spark Dataframeで列の内容をすべて表示するにはどうすればよいですか?
-
[解決済み] 複数のテキストファイルを1つのRDDに読み込むには?