redis永続化原則、キャッシュ問題処理ソリューション
レディス
赤の永続性
redisの電源が入ると ->永続化ファイルを読み込む(最初の電源投入時ではない) ->起動する ->何らかのデータを書き込む
->redisはある時点でメモリからディスクにデータを書き込みます(永続化ファイルを生成します)。
1. RDB永続化の原則
この原則は、redisが現在のスレッドとまったく同じように別の子プロセスを作成(フォーク)し、この子プロセスにすべてのデータを永続化することです。
(変数、環境変数、プログラムカウンタなど)は元のプロセスと全く同じで、データはまず一時ファイルに書き込まれ、永続化が完了した時点で
メインプロセスは全行程でio操作を一切行わないため、高いパフォーマンスを確保することができます。
- この永続化ファイルはどこにあるのですか?
- ディレクション . / (デフォルトでは起動の場所に基づいていますが、設定するのがベストです)
- dump.rdb ファイルを生成する
- いつ子プロセスをフォークするのか、いつrdbの永続化機構を離脱させるのか。
- 1.aofがオンになっていないとシャットダウンが発生します。
- 2. 設定ファイル内のデフォルトのスナップショット設定
- save 900 1 (タイマー900秒、トリガーとなる変更があります)
- セーブ300 100
- save 60 10000 (最適化ソリューション、300, 60を削除。クラスタ環境では、rdbは削除不可)
- 3. execute save(メインプロセス実行、ブロックする)、bgsave(フォークプロセス、バックグラウンドで非同期にスナップショットを実行する)。
- 4. flushallを実行、メモリデータを空にするが、空っぽで意味がない。(ディスクのデータも空にしておかないと、データが消えてしまいます)。
rdbのデメリット。
1. 予期せぬダウンタイム、データ損失が発生する。これは、rdbの永続化メカニズムが起動できないためです。
2. AOF永続化原則
redisの操作ログはファイルに追記するのが原則で、読み取り操作はログに残らない。
- この永続化ファイルはどこにあるのですか?
- appendonly yesはaofがオンになっていることを意味します。
- ディレクトリ . / (デフォルトでは起動した場所になります。設定するのがベストです)
- appendonly.aof ファイルを生成します。
- トリガー機構(プロファイル設定項目に基づく)
- appendfsync no means wait for OS to synchronize data to disk (bulk operation) (fast efficiency, no guarantor of persistence)
- appendfsyncは、データの変更が発生するたびに、常にディスクへの永続性と記録を同期させる(低効率、安全)。
- appendfsync everysec は 1 秒に 1 回の同期を意味します (デフォルト、高速ですが、1 秒以内にデータが失われる可能性があります)
- データパスの流れ:メインプロセス -> バッファ -> Aofファイル(ディスク)
- データは、まずメインプロセスからバッファに移動し、最終的にaofファイルに書き込まれることになります。
- noは、データがバッファに入り、aofファイルに書き込む前にバッチで待機することを意味します。
- always は、データがバッファに入り、直ちに aof ファイルに書き込まれることを意味します。
- everysec は、データがバッファに入り、1秒に1回実行され、aof ファイルに書き込まれることを意味します。
- aofの書き換え機構(aofが常に大きくなってしまう問題を解決するため)
- 子プロセスをフォークするように書き換えた。現在のメモリデータに基づいてaofスナップショットを生成します。
- redis4.0は、書き換えのさらなる最適化であるハイブリッドパーシステンスを可能にします。
- aof-use-rdb-preamble yes (rewrite-aofファイル機構をオンにするかどうか)
- bgrewriteaof, (rdbデータ形式のaofファイルに保存)コマンドを手動で実行する。
- 自動で書き換えをトリガーする
# Growth percentage (100%)
auto-aof-rewrite-percentage 100
# When the aof file grows to a certain size, redis will call bgrewriteaof to rewrite the log file.
auto-aof-rewrite-min-size 64mb (optimization point, must be changed for production environments, usually 5G or more)
Example.
First trigger: 64mb , second trigger: 64mb + 64mb * 100% = 128mb
概要
<テーブル タイプ 子プロセスをフォークするかどうか 欠陥 プロス RDB 子プロセスをフォークする 最後に書き込んだデータが失われる可能性がある redis起動時にディスクから永続データをロードすると非常に高速になる アオフ 子プロセスをフォークしない 2秒以上のデータ損失はありません redis起動時にディスクから永続的なデータを読み込むのはrdbに劣る 書き換え回数 子プロセスをフォークするredisキャッシュの問題
1. キャッシュの浸透
データベースにもキャッシュにも存在しないデータに対する問い合わせのことを指す
解決策
- 1. 空のオブジェクトをキャッシュする (シンプルなコード、悪い結果)
- デメリット
- 1. 同じキーに対してのみ制限可能で、多数のキーに対しては制限できない。
2. redisに大量の空データが存在し、redisのメモリを占有するという問題が発生する可能性があります。
//from the cache
obj = redis.getkey(id);
if(obj ! = null){
//(cache empty object)
if(obj instanceOf empty object){
return "Check no data";
}
return "Query successful"+obj;
}
try{
//from database
obj = dao.select(id);
if(obj ! = null){
redis.setKey(id, obj);
return "query successful"+obj;
}else{
// (cache the empty object)
redis.setKey(id, empty object);
}
}
return "Check for no data";
- 2. ブルームフィルタ(複雑なコード、素晴らしい結果)
//Bloom filter
if (!bloomFilter.mightContain(id)) {
//Not present
return "Check for no data";
}
//fetch from cache
obj = redis.getkey(id);
if(obj ! = null){
return "query successful"+obj;
}
try{
//from the database
obj = dao.select(id);
if(obj ! = null){
//add a bloom filter
bloomFilter.put(id);
return "query successful"+obj;
}
}
return "Check no data";
- 行方不明
- 1. ブルームフィルタはメンテナンスが面倒で、削除することができず、新しいものにリファクタリングするだけです。
- 2. ブルームフィルターは最初に初期化する必要があり、そうしないと最初にクエリーを実行したときに存在すらしません。
- 原理
ビット配列の場合、1つのキーが複数のハッシュアルゴリズムでハッシュ値を取得し、ビット配列に格納します。
複数のハッシュアルゴリズムで得られたハッシュ値は、対応するインデックスの上位にデータがあり、誤判定する場合がある。
- 分散型ブルームフィルタ
//guava dependencies
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
private static int size = 1000000;
/**
* size how much data is expected to be inserted
* fpp error tolerance ---> what is the probability of a miscalculation
* list is created as an object array
* bit array
*
* bit array 2.1 billion JVM memory Data will not be persisted 256M
* redis 4.2 billion redis memory persistent data for redis 512M
*/
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.001);
public static void main(String[] args) {
for (int i = 1; i <= size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<>(10000);
// Deliberately take 10000 values that don't exist in the filter and see how many will be considered in the filter
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
//misjudge (clearly not present, misjudge as present)
list.add(i);
}
}
System.out.println("Number of misclassifications: " + list.size());
}
2. キャッシュスレッディング
は、データベースにデータがあり、キャッシュにない(誰もこのデータにアクセスしていない、データがたまたま無効だった)ことを意味します。同時アクセスでは、すべてのクエリーがデータベースへアクセスすることになります
キャッシュヒットとは、キャッシュにないデータがデータベースにある場合(通常はキャッシュの時間切れの場合)、多くの同時使用者が同時にキャッシュを読み、データを読まず、同時にデータベースにアクセスしてデータを取得するため、データベースの圧力が一気に高まり、過度のストレスが発生します
キャッシュでは、取得できない場合は、データベースに取りに行くことが分かっています。しかし、ホットキーであれば、アクセスが非常に多いため、データベースがキャッシュを再構築する際に、同時に再構築するスレッドが多数発生します。再構築のホットキーの数が多いために引き起こされる高い並行輸入は、まだ完了していない、常にキャッシュを再構築する作業を行うためにスレッドの数が多いために、サーバーの速度低下をもたらすのプロセスです。
解決策
<ブロッククオート- 1. 相互排除ロック
最初にキャッシュを取得すると、ロックが追加され、データベースに問い合わせが行われ、その後キャッシュの再構築が行われます。この時点で、キャッシュをフェッチするために別のリクエストがやってきて、ロックを見つけ、待ちに入り、そして、再構築が完了し、ロックが解除され、キャッシュヒットが再びフェッチされるまで、すべて一つの待ち時間となります。
public String getKey(String Key){ [キー]を取得します。 文字列値 = redis.get(key)。 if(値==null){。 String mutexKey = "mutex:key:"+key; //ミューテックスロックのキーを設定します。 if(redis.set(mutexKey,"1","ex 180","nx"){ // このキーにロックをかける、exは1スレッドのみ実行可能で、有効期限は180秒。 value = db.get(key)です。 redis.set(key,value)。 redis.delete(mutexKety)。 }else{ // 他のスレッドは100ミリ秒休んでから再試行する Thread.sleep(100); getKey(キー); } 値を返します。 }相互排他的ロックの利点は、考え方が非常にシンプルで一貫性があることですが、相互排他的ロックには、多数のスレッドが待機する問題というのがあります。デッドロックが発生する可能性がある。
<ブロッククオート
- 2. 分散ロック
redissonフレームワークが提供するredis分散ロックを使用することができます。
3. キャッシュなだれ問題
キャッシュなだれとは、マシンがダウンしたり、キャッシュを設定したときに同じ有効期限を使用したために、ある時点で同時にキャッシュが切れ、リクエストがすべてDBに転送され、DBが一瞬にして雪崩を打ってオーバーストレスになることです。
解決方法
<ブロッククオート
- 1. キャッシュが無効になった後にロックやキューを追加することで、データベースの読み込みやキャッシュの書き込みを行うスレッドの数を制御する。例えば、あるキーに対してデータを照会し、キャッシュを書き込むことができるのは1つのスレッドのみで、他のスレッドは待機する。
- 2. A1はオリジナルキャッシュ、A2はコピーキャッシュ、A1の有効期限が切れるとA2にアクセス可能、A1のキャッシュの有効期限は短期、A2は長期に設定
- 3. キーごとに異なる有効期限を設定し、できるだけ均等なタイミングでキャッシュを失効させる。
- 4. キャッシュデータベースが分散配置の場合、ホットデータを異なるキャッシュデータベースに均等に分散させる。
4. キャッシュとデータベースのデータ整合性の問題
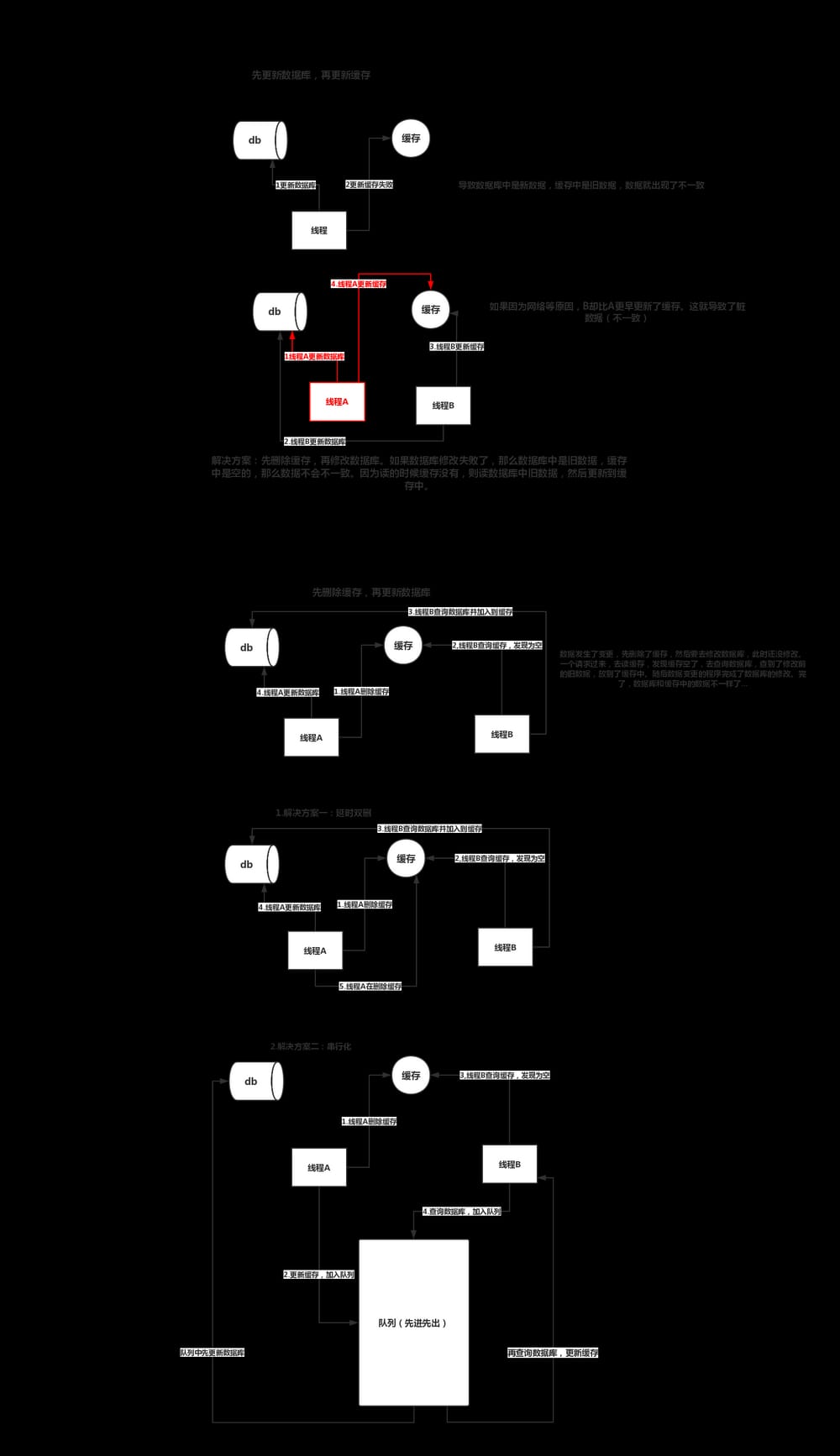
5. キャッシュの粒度制御
平たく言えば、キャッシュの粒度の問題は、キャッシュを使うときにデータの全部をキャッシュするか、一部をキャッシュするかということである。
<テーブル データの種類 一般的な スペースフットプリント(メモリ容量+ネットワークコードレート) コードのメンテナンス 全てのデータ 高い 大きい シンプル 部分的なデータ 低い 小さい より複雑キャッシュの粒度は見落としがちな問題で、使い方を誤ると、無駄なスペース、無駄なネットワーク帯域、コードの汎用性の低さなど、多くの問題を引き起こす可能性があります。データの汎用性、スペース消費率、コードの保守性などのトレードオフを評価することを学ばなければなりません。
redisクラスタ構築
1. redisを/opt/myredis/redisにインストールする。
2. redis7000,redis7001,redis7002,redis7003,redis7004,redis7005 フォルダを新規に作成する。
3.redis7000の下にredis.confファイルをコピーします。
4. 各ディレクトリのredis.confファイルを個別に修正する
vi redis7000/redis.conf
1.bind 127.0.0.1 Specify the local ip (intranet ip)
2.port 7000
3.daemonize yes
4.pidfile /opt/myredis/redis7000/redis_7000.pid
5.logfile /opt/myredis/redis7000/redis_7000.log
6.dir /opt/myredis/redis7000
7.requirepass 123456
(cluster environment parameters)
8.cluster-enabled yes (start cluster mode)
9.cluster-config-file nodes-7000.conf (here 800x better correspond to the port)
10.cluster-node-timeout 15000
11.appendonly yes
4. redis7000/redis.conf ファイルを redis7001,redis7002,redis7003,redis7004,redis7005 にコピーする。
Copy the redis7000/redis.conf file to redis7001 and replace the 7000 characters with 70001 in bulk
sed 's/7000/7001/g' redis7000/redis.conf > redis7001/redis.conf
sed 's/7000/7002/g' redis7000/redis.conf > redis7002/redis.conf
sed 's/7000/7003/g' redis7000/redis.conf > redis7003/redis.conf
sed 's/7000/7004/g' redis7000/redis.conf > redis7004/redis.conf
sed 's/7000/7005/g' redis7000/redis.conf > redis7005/redis.conf
5. 7000,7001,7002,7003,7004,7005インスタンスをそれぞれ起動する
/opt/myredis/redis/bin/redis-server /opt/myredis/redis7000/redis.conf
/opt/myredis/redis/bin/redis-server /opt/myredis/redis7001/redis.conf
/opt/myredis/redis/bin/redis-server /opt/myredis/redis7002/redis.conf
/opt/myredis/redis/bin/redis-server /opt/myredis/redis7003/redis.conf
/opt/myredis/redis/bin/redis-server /opt/myredis/redis7004/redis.conf
/opt/myredis/redis/bin/redis-server /opt/myredis/redis7005/redis.conf
# Check if it started successfully
ps -ef | grep redis
6. クラスタの構築、マスター・スレーブの割り当て、スロットの割り当て
/opt/myredis/redis/bin/redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
Here there are 6 ip's, which means the first 3 ip's are master nodes and the next 3 are slave nodes
1, means the ratio of master to slave is 1:1 (3:3)
2, which means the master-slave ratio is 2:4 (2:4), but the master node must have more than 3, then an error will be reported here
The slots here are equally distributed: 16384
7. クラスターを検証する
1. Just connect to any client: (-c is redis-cli can help us automatically calculate the slot and redirect to the corresponding redis)
/opt/myredis/redis/bin/redis-cli -c -h 127.0.0.1 -p 7000 (-c means cluster mode, specify ip address and port number)
2. To verify.
cluster info (view cluster information), cluster nodes (view node list)
3. verify the data operation
set key llsydn
4. To shut down the cluster, you need to shut down one by one, using the command
/opt/myredis/redis/bin/redis-cli -c -h 127.0.0.1 -p 700* shutdown
Redisコンテンツエクステンション
1. パイプライン
注:Pipelineを使用した操作は非原子的である
2. ジオ
GEOADDの場所 116.419217 39.921133 北辰
GEOPOSロケーションズ 北神
GEODIST ロケーション 天津市北辰区 km 算出距離
GEORADIUSBYMEMBER ロケーション 北辰 150キロメートル 距離で都市を計算する
注:削除コマンドはなく、基本的にzset(locationsと入力)です。
つまり、zrem key member を使って要素を削除することができます。
zrange key 0 -1 means all 指定されたセット内の全ての値を返します。
3. ハイパーログログ
Redis はバージョン 2.8.9 で HyperLogLog 構造体を追加しました。
RedisのHyperLogLogは基本統計量を行うためのアルゴリズムです。HyperLogLogの利点は、入力要素の数やサイズが非常に大きい場合、基底を計算するのに必要なスペースが常に一定で小さいということです。
Redisでは、ほぼ2^64種類の要素の基本数を計算するために、各HyperLogLogキーはわずか12KBのメモリしか必要としません。これは、より多くの要素が基底を計算する際により多くのメモリを消費するコレクションとは対照的です。
PFADD 2017_03_06:taibai 'はい' 'はい' 'はい' 'いいえ'
PFCOUNT 2017_03_06:taibai 何種類の値をカウントするか
1.PFADD 2017_09_08:taibai uuid9 uuid10 uu11
2.PFMERGE 2016_03_06:taibai 2017_09_08:taibai マージしました。
注:本質はまだ文字列である 、フォールトトレランスで、公式の数値は0.81%である
4.ビットマップ
setbit taibai 5000 0(taibaiのキーの5000bitを0に設定する。)
getbit taibai 5000(taibaiをキーとするデータの5000bitビットをセットする)
bitcount taibai(1が何個あるか数える)
ビットマップは基本的に文字列であり、連続した2進数(0または1)の文字列で、各ビットの位置はオフセットである。
文字列(Bitmap)の最大長は512MBなので、2 ^ 32 = 4294967296種類のビットを表現することができる。
関連
-
[解決済み】127.0.0.1:6379 で Redis に接続できませんでした。homebrewで接続が拒否された
-
[解決済み] MISCONF RedisがRDBスナップショットを保存するように設定されている。
-
[解決済み] レディス パターンに一致するキーを検索する
-
[解決済み] エラーです。スタンナルメソッドでElastic cacheに接続中、ピアによって接続がリセットされました。
-
[解決済み] Redisインスタンスのバージョンを確認する方法は?
-
[解決済み] Zookeeper vs インメモリデータグリッド vs Redis
-
を作ってください。*** ターゲット "install "を作るためのルールがありません。停止
-
error:[Errno 98] アドレスが既に使用されている場合の解決策
-
Linux installation of redis common error server.c:3318:16: error: 'struct redisServer' has no member named 'loading '
-
redis の高可用性 --- マスタースレーブレプリケーション、センチネル、クラスタ
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン