Python 最適化データ前処理法 Pandasパイプ 詳細
Pandasはデータ解析・処理に最も広く使われているライブラリの一つで、生データの前処理を行うための様々なメソッドを提供しています。
import numpy as np
import pandas as pd
df = pd.DataFrame({
"id": [100, 100, 101, 102, 103, 104, 105, 106],
"A": [1, 2, 3, 4, 5, 2, np.nan, 5],
"B": [45, 56, 48, 47, 62, 112, 54, 49],
"C": [1.2, 1.4, 1.1, 1.8, np.nan, 1.4, 1.6, 1.5]
})
df
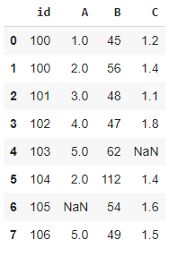
上記データのNaNは欠損値、id列は重複値、B列の112は異常値と思われます。
これらは、実際のデータにおける典型的な問題点である。今説明した問題を処理するパイプラインを作成します。それぞれのタスクに対して、関数が必要です。そこでまず、パイプラインに配置する関数を作成します。パイプラインで使う関数は、データフレームを引数に取り、データフレームを返す必要があることに注意してください。
最初の関数は、欠損値を処理するためのものです
def fill_missing_values(df):
for col in df.select_dtypes(include= ["int","float"]).columns:
val = df[col].mean()
df[col].fillna(val, inplace=True)
return df
私は、数値列の欠損値を列の平均値に置き換えるのが好きですが、もちろん特定のシナリオに合わせて定義することができます。データフレームを引数に取り、データフレームを返すものであれば、パイプラインで動作します。
2つ目の関数は、重複する値を削除するためのものです
def drop_duplicates(df, column_name):
df = df.drop_duplicates(subset=column_name)
return df
Pandasの組み込みのdrop duplicates関数を呼び出し、与えられたカラムの中の重複する値を削除します。
最後の関数は、外れ値を除去するためのものです
def remove_outliers(df, column_list):
for col in column_list:
avg = df[col].mean()
std = df[col].std()
low = avg - 2 * std
high = avg + 2 * std
df = df[df[col].between(low, high, inclusive=True)]
return df
この関数は、以下の処理を行います。
- データフレームと列のリストが必要です。
- リスト内の各列について、平均と標準偏差を計算する。
- は標準偏差を計算し、下限平均を使用します。
- 下限値と上限値で定義された範囲外の値を削除する
これまでの関数と同様に、外れ値を検出する方法を自分で選択することができます。
パイプラインの作成
これで、データの前処理を行うための3つの関数が揃いました。次は、これらの関数を用いてパイプラインを作成します。
df_processed = (df.pipe(fill_missing_values).pipe(drop_duplicates, "id").pipe(remove_outliers, ["A","B"] ))
このパイプラインは、指定された順序で関数を実行します。パイプラインには、関数名と一緒に引数を渡すことができます。
ここで一つ言及しておきたいのは、パイプラインの中のいくつかの関数は元のデータフレームを変更するということです。したがって、上記のパイプラインを使用すると、dfも更新されます。
この問題を解決する一つの方法は、パイプラインで元のデータフレームのコピーを使用することです。もし、元のデータフレームをそのままにしておいても構わないのであれば、パイプラインの中でそれを使うことができます。
パイプラインを次のように更新してみます。
my_df = df.copy()
df_processed = (my_df.pipe(fill_missing_values).pipe(drop_duplicates, "id").pipe(remove_outliers, ["A","B& quot;]))
元のデータフレームと処理後のデータフレームを見てみましょう。


まとめ
もちろん、これらの関数を個別に使用しても同じ作業を行うことは可能です。しかし、パイプライン関数は、複数の関数を1つの操作にまとめるための、構造化され整理された方法を提供します。
生データとタスクによっては、前処理に追加のステップが含まれることがあります。パイプライン関数には、必要に応じていくつでもステップを追加することができます。ステップの数が増えるにつれて、パイプライン関数の構文は、関数を個別に実行する場合と比較して明確になります。
以上、Python最適化データ前処理手法「Pandas pipe」について詳しく解説しました。pandas pipeのデータ前処理最適化については、Scripting Houseの他の関連記事もフォローしてください
関連
-
[解決済み】Python json.loadsにValueErrorが表示される。余分なデータ
-
[解決済み】Pythonが'list'オブジェクトをstrに変換できないエラー [終了しました]
-
PygameのDraw関数の具体的な使用方法
-
[解決済み] bash: 予期しないトークン `(' の近辺でシンタックスエラーが発生 - Python
-
[解決済み] 'tuple' オブジェクトはアイテムの割り当てをサポートしていません。
-
[解決済み] ハンドシェイクに失敗し、-1、SSL エラーコード 1、net_error -201 を返しました。
-
[解決済み] ImportError: flask.ext'という名前のモジュールがない [重複] 。
-
[解決済み] 基本ファイルが実行されない → デバイスPRNを初期化できない
-
[解決済み] UnicodeDecodeError: 'ascii' コーデックは、位置 13 のバイト 0xe2 をデコードできません: 序数が range(128) にありません。
-
[解決済み] TensorFlowチュートリアルのbatch_xs, batch_ys = mnist.train.next_batch(100) のnext_batchはどこから来ているのでしょうか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】pip install mysql-python は EnvironmentError: mysql_config not found で失敗します。
-
[解決済み】Python throws ValueError: list.remove(x): xがリストにない。
-
[解決済み] データ型変換エラーです。ValueError: 非有限値(NAまたはinf)を整数に変換できない[重複]。
-
[解決済み] seabornヒートマップのxticklabelsのフォントサイズを変更する。
-
[解決済み] Django インポート datetime
-
[解決済み] toxで1つのテストだけを実行する方法は?
-
[解決済み] torch.clampの列依存境界線
-
Fatal Python error: init_fs_encoding: failed to get Python codec of filesystem encoding
-
Python Data Analysis-ImportError: pandas.io.data'という名前のモジュールがありません。
-
TypeError: 'float' オブジェクトは整数として解釈できません。