Pythonの知識ポイント(過去最高の完成度)
Python最終試験知識のポイント(過去最多の完成度)
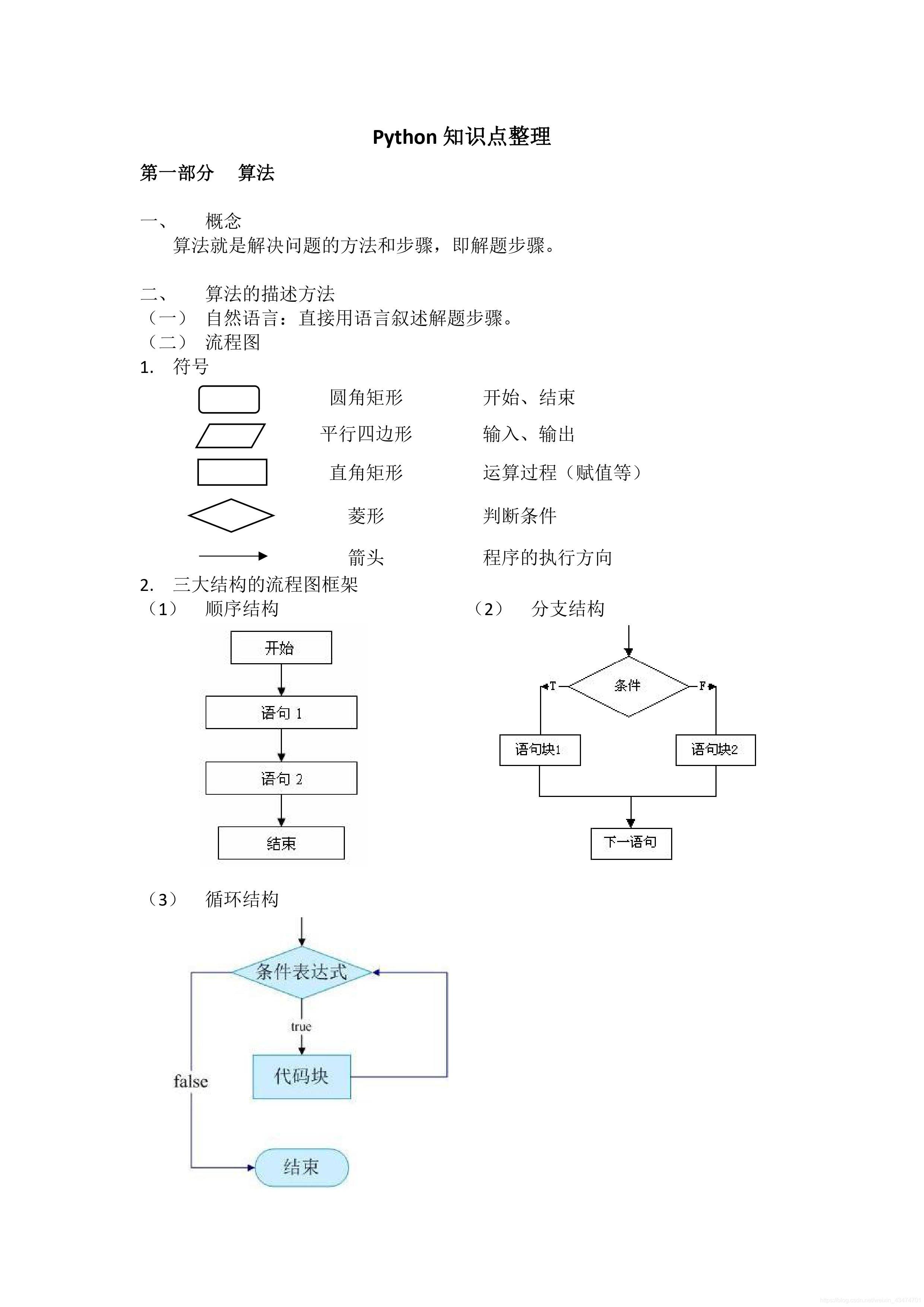






python入門
Python is an interpreted language
Python uses indented alignment to organize code execution, so code that is not indented is automatically executed on load
Data types: plastic int infinite
floating-point float fractional
complex complex consists of real and imaginary numbers
There are six standard data types in Python.
Number (numbers)
String
List (list)
Tuple
Sets
Dictionart(Dictionary)
Among the non-fungible data.
Number (number) String (string) Tuple (tuple) Sets (set)
Can become
List(list) Dictionart(dictionary)
We can use type or isinstance to determine the type
<イグ
type() はサブクラスを親タイプとは見なしません。
isinstance() は、サブクラスを親型と見なします。
To define variables in python, you don't need to write the variable type, but you must initialize it. It will automatically match the data type we write, based on the
Variable naming rules: consist of letters, numbers, underscores, the first must be a letter or underscore, case-sensitive, not a keyword
Input and Output
When we need to input Chinese, we need to include the header file # -*- coding: UTF-8 -*- or #coding=utf-8
input a=input("Please enter a number") Return value is str type
output print('hello world') Of course, you can also output variable values strictly according to the format control character here
For example: print("now a=%d,b=%d"%(a,b)) double quotes without commas
print default newline, we can print( end=''), modify the default parameter so that he does not newline
You can also add a comma after print() print(xxx) , which will also not be a newline.
-
基本構文
演算子です。
算術演算子:5の累乗の**をもう1つ**5は5の5乗、 // 整数除算をもう1つ
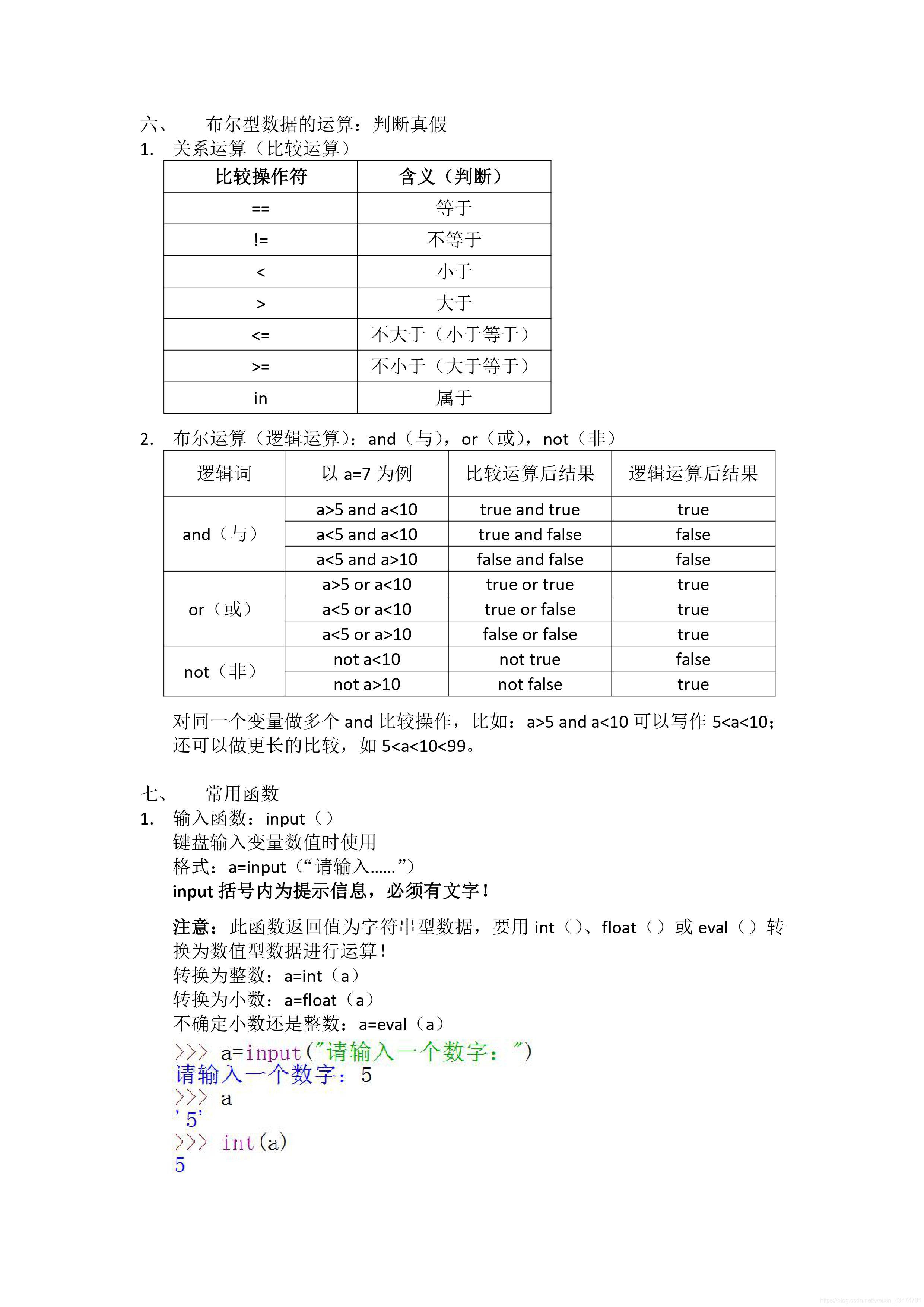
論理演算子:and,or,not with,or,not
代入演算子:なし ++, -
同一性演算子:is is not
メンバー関係演算子:in not in
概要:余分な ** と // // は整数の除算を意味し、例えば 5//3 は 1 になるが 5/3 は 10 進数の 1.6666666667 になる。
Operator precedence (from highest to lowest below): power operators are the highest
Power operator **
Positive and negative signs + -
Arithmetic operators *, /, //, +, -
Comparison operators <,<=,>,>=,==,! =
Logical operators not,and,or (not>and>or)
構造体の選択
if-else
if-elif-else (elseは省略可)
Logic results
Anything that is "empty' in python is false "" (true if there are spaces in between, false if there is nothing here) Empty tuple, empty list, empty dictionary 0 all false
文字列

Pis:元の文字列を示すために、文字列の前に r を付け、エスケープしない。
リスト
リストは、順序付けられた項目の集合を扱うデータ構造であり、角括弧で定義される
リストに対する操作
I. 添え字によるリスト内の値へのアクセス (スライスによるアクセスも可能)
Output: Here we are using slicing to access 1 through 5
Key: Note the use of slicing here, we wrote 1:5 to actually access the subscripts 1,2,3,4...no 5!
<イグ
次に、リストを更新します (リストは変更可能です)
添え字を経由して、値を直接変更します。
3つ目は、リスト要素の削除(del + list item) remove()に続けて、アイテムを削除します。

IV、リスト用スクリプト演算子

V、リストインターセプト用、ステッチ

六、リストには(タプルをリストに変換する)関数が付属しています。
メソッド 関数
max(list) は、リスト要素の最大値を返します。
min(list) は、リスト要素の最小値を返します。
list(seq) タプルからリストへの変換
list.append(obj) リストの末尾に新しいオブジェクトを追加します。
list.count(obj) リスト内にある要素の出現回数を数えます。
list.extend(seq) リストの末尾に新しいリストを追加して、リストを拡張します。
list.index(obj) リスト内で最初に一致する値のインデックス位置を求めます。
list.insert(index,obj) リストにオブジェクトを挿入します。indexは、挿入の位置で、元の位置の後ろの要素は、位置の要素を含む、一様に後ろに移動されます。
list.pop(obj=list[-1])
この関数とdelの違いは、delがキーワードであることです。delとの違いは、delはキーワードであるのに対し、popは組み込み関数なので、delによって削除された項目を受け取るために変数を使うことができないことです(引数は省略可能で、最後の項目はデフォルトで削除されます)。
list.remove(obj) リストから、値が最初に一致した項目を削除します。
list.reverse() はリストの要素を反転させます (末尾が入れ替わります)。
list.sort() は、リストをソートします。
list.copy() は、リストをコピーします。
list.clear() リストを消去します。
コレクションを設定する
セットは重複のない要素の順序付きシーケンスである
基本的な機能は、メンバーシップテストを行い、重複する要素を削除することです(いわゆるメンバーシップテストとは、重複しているかどうか、2つの集合の交差点かどうか......)。
コレクションを作成するには、{ } または set() 関数を使用しますが、空のコレクションを作成するには set() を適用する必要があります。

プログラミング言語の変遷:機械語、アセンブリ言語、高級言語
機械語。コンピュータは内部でバイナリコードしか受け付けないため、バイナリコード0または1で記述された命令をマシン命令と呼び、すべてのマシン命令の集合がコンピュータの機械語を構成する。
アセンブリ言語:基本的に機械語と同じで、どちらもハードウェアを直接操作する。ただし、命令は認識しやすく覚えやすいように英語の識別子を省略したものを使用する。
高水準言語。高レベル言語は開発者に優しく、開発効率が高い。
高級言語で書かれたプログラムは、コンピュータに直接認識されないので、実行する前に変換する必要がある。
高級言語は変換によって分類される:コンパイルされたもの、解釈されたもの
コンパイルされたもの。プログラムのソースコードをターゲットコードに変換してからアプリケーションソースを実行するため、ターゲットコードは言語環境に依存せずに実行できる。
コンパイルされたプログラムは再翻訳されることなく、翻訳結果をそのまま使用するだけで実行されます。プログラムの実行効率が高い、遅延依存のコンパイラ、クロスプラットフォームに劣る。C、C++、GO、Delphiなど。
インタプリタ型。アプリケーションのソースコードを対応する言語のインタプリタで実行しながらターゲットコードに変換するため、効率が悪く、独立して実行可能な実行ファイルを生成できず、アプリケーションとインタプリタを分離することができない。Python、Java、PHP、Rubyなど。クロスプラットフォームが得意で、開発効率はあまり良くない。
コンパイル言語は実行速度が速い、言語環境に依存せずに実行できる、クロスプラットフォームに弱い
インタプリタ型は、クロスプラットフォームに適しており、1つのコードでどこでも実行できます。デメリットは実行速度が遅いことと、実行する際にインタプリタに依存することです。
Pythonの創始者。グイド・ヴァン・ロッサム(タートルおじさん)
Pythonは1989年に誕生しました
Python 3.0が登場したのは2008年12月
2010年に移行版Python 2.7が登場(最大でも2020年までしかサポートされず、それ以降は2.0バージョンはサポートされない)。
Python インタープリタは C 言語で記述されています。
Python インタープリタの種類は以下の通りです。CPython、IPython、PyPy、Jython、IronPython。
インストールが正常に行われたかどうかをテストする。
Windows->run->type cmd,enter で cmd プログラムがポップアップするので、Python と入力し、対話型環境になればインストール成功です。
print('hello world!')
helloworld.pyとして保存します。接尾辞.pyの目的に注意してください:命名制約の指定、プログラマがコードを識別しやすいようにします。
cmdコマンドラインでPython helloworld.pyを実行し、結果を見てください。
ファイル名の前にpythonを付けているのは、pythonインタプリタにコードを解釈して実行させるためであることに注意してください。
メモリとディスクの関係:メモリアクセスは高速で電源が落ちると失われる、ディスクアクセスは低速で永久に保存される。
Pythonインタラクタは、主にコードのデバッグに使用される
変数:最初に定義して、後で使用する
変数:データを保存し、メモリを占有し、プログラム実行の中間結果を保存し、後でコードから呼び出すことができる。
変数の宣言:変数名=変数の値
変数の命名規則
1. 変数名は、数字、文字、アンダースコアの組み合わせのみとする
2. 変数名の最初の文字は数字ではありません。
3. 以下のキーワードは変数名として宣言できません ['and','as','assert','break ','class','continue','def','elif ','else','except','exec', for','from','global','if','import','in','is','lambda','not','or','pass','print','raise','return','try','while','with','yield'] となります。
定数:プログラム実行中に変更することができない量
Pythonには定数のための特別な構文はありません。プログラマーの慣習として、定数のための変数名はすべて大文字にします。
ユーザー入力の読み込み
name = input("あなたの名前は何ですか:")print("こんにちは "+name)
ユーザー名とパスワードの入力
username= input("ユーザー名:")
password= input("password:")print(username,password)
コメント:コードを読みやすくするための説明文です。
一行コメント。#
複数行のコメント。
データ型
データ型 - 数値型
int (整数): 32ビットマシンでは-2 31 -- 2 31 - 1 64bit 同上
long (長整数型)。Python の long integer 型はビット幅を指定しない。(Python 3でlong型は廃止されました)。
float (浮動小数点型)。
データ型 - 文字列型
文字列です。Pythonでは、引用符で囲まれた文字は文字列とみなされます!
注:一重引用符と二重引用符の違いはありません。複数行の文字列は複数引用符で囲む必要があります。
ブーリアン型。
TrueとFalseの2値のみで、主に論理的な判断に使用される
書式付きで出力します。(%s は文字で置き換え %d は整数で置き換え %f は浮動小数点数で置き換え) はプレースホルダー % は連結子です。
演算子
算術演算子(+,-,*,/,%,**,//)は、次のようなものです。
比較演算子(==,! =,<>,>,<,>=,<=)は
論理演算子(and,or,not)・・・・・・・・・・。
代入演算子 (=,+=,*=,/=,%=,**=,//=)、および
メンバーシップ演算子(in,not in)や
同一性演算子(is , is not)、は
ビット演算子(>>,<<)
プロセス制御
シングルブランチ
if条件。
条件を満たしたときに実行されるコードのブロック
マルチブランチ
という条件であれば
条件を満たしたときに実行されるコードのブロック
elif コンディション
上記の条件を満たさない場合は、次のようにします。
elif コンディション。
上記の条件を満たさない場合は、次のようにします。
elif コンディション。
上記の条件を満たさない場合は、次のようにします。
でなければ
上記の条件を満たさない場合は、次のようにします。
whileループ
while コンディション。
コードを実行する...
デッドループ
count=0
をTrueのままにしておきます。
print("このホモ野郎!!!" ,count)
count+=1
ループの終了文:break文またはcontinue文
break文:ループを完全に終了させ、本体から飛び出して後続の文を実行するために使用します。
continue文:現在のループだけを終了させ、次のループを実行します。
while...elseの使い方
whileループが正常に実行を終了し、途中でブレークして終了しない場合、else以降の文が実行されます。
バイナリ演算、文字エンコーディング、データ型
2進数(0,1)、8進数(0-7)、10進数(0-9)、16進数(0-9、A-F) 2進数変換
2進数の4ビットから16進数の1ビットへ
oct() 8進数 hex() 16進数
char(num) は、ASCII 文字に変換するために、0-255 の範囲の数字を使用します。
ord(char) は、ASCII 値の文字を受け取り、対応する ASCII 値を返します。
各0または1は、ビットと呼ばれる空間の単位を占め、これはコンピュータの表現の最小単位である
8ビット=1バイト 記憶の最小単位であるバイト、1バイトは1Bと略記される
1024バイト=1キロバイト
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
ASCII 256、各文字は8ビットを占有します。
ユニコード・エンコーディング(Unicode、ユニコード):すべての文字と記号を最小16ビットで表現することを規定しています。
UTF-8:アスキーコードの内容は1バイトに、欧文文字は2バイトに、東アジア文字は3バイトに...と格納される。
中国版winsowsシステムのデフォルトのエンコーディングはGBKです
Mac OSLinux システムのデフォルトのエンコーディングは UTF-8 です。
UTFは、ストレージや伝送におけるユニコード・エンコーディングのために設計された、スペースを取らないエンコーディング方式です。
メモリ上でどのようなエンコーディングで文字を表示しても、ハードディスク上にはバイナリとして保存されます。バイナリーはエンコーディングによって異なる
ハードディスクに保存されているエンコーディングが何であれ、同じエンコーディングで読まないと文字化けしてしまうのです。
Python 2.x のデフォルトのエンコーディングは ASCII です。中国語はデフォルトではサポートされておらず、サポートするためには追加する必要があります。# * コーディング:utf-8 または#!encoding:utf-8
Python 3.xのデフォルトエンコーディングはUTF-8で、デフォルトで中国語をサポートしています。
Pythonのデータ型
文字列
数値: integer (int) long integer (long) floating point (float) boolean (bool) complex (complex)
リスト
タプル タプル
辞書
set: ミュータブルセット(セット) イミュータブルセット(フロジンセット)
不変の型:数値、文字列、タプル
変数型:リスト、ディクショナリ、コレクション
899590-20180512120213031-26929447.png
文字列
特徴:順序性、不変性
文字列の共通メソッド:isdigit、replace、find、count、index、strip、split、format、join、center
コントラクトブロック.gif
拡張ブロック開始.gif
1 s = "abcd"。
2 print(s.swapcase()) # すべて大文字になる
3
4 print(s.capitalize()) # 全てが初期大文字になる
5
6 print(s.center(50," ")) # print the string of the variable s 長さを50に指定し、文字列の長さが足りない場合に使用する。 で長さを補う
7
8 print(s.count("a",0,5))です。# 0,5 は 0 から 5 までの添え字を意味します。
9
10 print(s.endswith("! ")) # 何かで終わるかどうか
11
12 print(s.startswith("a"))です。# 何から始めるか決定する
13
14
15 s = "a b"。
16 print(s.expandtabs(20)) # a と b の真ん中のタブの長さが 20 文字になるのと同等、インタラクティブモードではその効果が表示される
17
18 s.find("a",0,5) # 文字列を検索して、インデックスを返す。
19
20 s.format() # 文字列の書式設定
21 s1 = "私の名前は{0}です、私は{1}歳です"。
22 print(s1)23 print(s1.format("aaa",22)) # {0} を aaa に {1} を 22 にそれぞれ置き換える。
24 #次のように書くこともできます。
25 s1 = "私の名前は{名前},私は{年齢}歳です"。
26 s1.format(name="aaa",age = 22) # 辞書形式の割り当て
27
28 #s.format_map() #後続の追加事項
29
30
31 print(s.index("a"))です。# インデックス値を返す
32
33 print(s.isalnum()) # アラビア文字かどうかを確認する 数字と文字を含む
34
35 print(s.isalpha()) # アルファベットを除いたアラビア数字かどうか確認する
36
37 print(s.isdecimal()) # 整数かどうかを判断する
38
39 print(s.isdigit()) # 整数かどうか判断する
40
41 print(s.isidentifier()) # 文字列が利用可能な法的変数名であるかどうかを判断する
42
43 print(s.islower()) # 小文字かどうか判断する
44
45 print(s.isnumeric()) # 数字だけが入っているかどうかを判断する
46
47 print(s.isprintable()) # 印刷可能かどうかを判断する、linuxのドライバは印刷できない
48
49 print(s.isspace()) # スペースかどうかを判断する
50
51 print(s.istitle()) # タイトルかどうか判断する 各文字列の最初の文字を大文字にする Hello Worlld
52
53 print(s.isupper()) # 全てが大文字かどうかを判断する
54
55 #s.join()
56 name = ["a", "b", "1", "2"]57 name2 = "".join(name) # list to string, join all elements in the list to the string
58 print(name2) # yield ab12
59
60 #s.ljust
61 s = "ハローワールド"。
62 print(s.ljust(50,"-")) # 文字列の長さを左から50に設定すると、文字列の長さが足りなくなる - 追加
63
64 print(s.lower()) # 文字列はすべて小文字
65
66 print(s.upper()) # 大文字にする
67
68 print(s.strip()) # 括弧の内側を取り除く、これはスペースである可能性がある 改行タブ ...
69
70 s.lstrip() # 左側のスペースだけ取り除く
71 s.rstrip() #右側のスペースだけドラッグする
72
73 #s.maketrans()
74 str_in = "abcdef" # 一対一の対応でなければならない。
75 str_out = "! 一対一対応でなければならない。
76 tt = str.maketrans(str_in,str_out) # パスワードテーブルのような対応表が生成される。
77 print(tt)78 #Result: {97: 33, 98: 64, 99: 35, 100: 36, 101: 37, 102: 94}
79
80 print(s.translate(tt)) #s.translate メソッドは暗号化メソッド tt を呼び出して s の文字列を暗号化します。
81 #結果 H%llo Worl$
82
83 #s.partition()
84 s = "ハローワールド"。
85 print(s.partition("o"))です。# 最初のoで文字列を左から右へ半分に分割する
86 #結果 ('Hell', 'o', 'World')
87
88 s.replace("original character", "new character",2) # 文字列置換、複数回の置換も記述可能 デフォルトの完全置換、回数設定も可能
89
90 s.rfind("o") # 右端の文字を検索します。
91
92 print(s.rindex("o") ) # 右端の文字のインデックス値を調べる
93
94 s.rpartition("o") # 右端の文字から半分に分割する。
95
96 s.split() # 文字列をリストに分割し、括弧の中に空白などを入れる。
97
98 s.rsplit() # 文字列を右端からある文字で区切る
99
100 s.splitlines() # 分割する文字列を改行付きリストに設定する
101
102 print(s.swapcase()) # 大文字と小文字が入れ替わり、大は小に、小は大になります。
103 #result ":hELLO wORLD
104 #オリジナル "ハローワールド"。
105
106 s.title() # 文字列をタイトルフォーマットに変換 Hello World
107
108 s.zfill(40) # 文字列を40にする、文字列が足りないので左から右に0を埋める
109
110
111 #"atb" 文字列の途中にある"⽊"はタブと⾔えます。
112 #全体の意味は、aにタブがあり、その後にbがある
コードを見る
リスト
リストの共通メソッド:作成、クエリ、スライス、追加、変更、削除、ループ、ソート、反転、スプライス、クリア、コピー
リストの特徴:繰り返し使える、リストに順番がある
コントラクトブロック.gif
拡張ブロック開始.gif
1 1, create 2 方法1: list1 = ["a", "b"] # 共通
3 方法2: list2 = list () # 通常は使用しない
4
5 2. クエリ 6 リストのインデックス(添え字ともいう)。7 リストの左から右への添え字は 0 0, 1, 2, 3...8 リストの右から左への添え字は - 1 -1 -2 -3...9。
10 クエリのインデックス値:11 list1.index (a) #インデックスクエリは、プログラムが行かない最初のaを見つけます。
12 list1[0] # a のインデックスで a を取得する。
13 list1[-1] #bをその添え字で取得する
14
15 list1 = [1, 2, 3, 4, 4, 4, 4, 4] 16 リストの要素が同じである回数を数える 17 list1.count (4) # 回数を数える:6 はリストには 4 が 6 個あることを意味します。
18
19 3. スライス 20 スライス:インデックス(または添え字)によるスライス 21 リストからデータの一部を切り捨てる。22 list1 = [1, 2, 3, 4, 4, 4, 4, 4, 4] 23 list1[0:2] # yields [1,2], list slicing by head but not tail, also list1[:2].
24 list1[-5:] # yields [4,4,4,4,4], which takes last 5 elements, only from left to right.
25 ステップごとに要素を取る: 26 list1 = [1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5] 27 list1[:6:2] # yields:[1, 3, 5] :2 for step, 2ステップごとに要素を1つずつ取る
28 list1[::2] # yields :[1, 3, 5, 1, 3, 5] 2ステップ間隔でリストの全要素に数字を取る。
29
30 4.追加 31 list1 = ["a", "b", "c"] 32 list1.append ("d ") # list1の最後にdを追加 Result.Append ("b") # list1の最後にdを追加 Result: ['a', 'b', 'c', ' d'] となります。
33 list1.insert (1, "aa") #1のリスト添え字の前にaaを挿入 Result: ['a', 'aa', 'b', 'c', 'd'] となります。
34
35 5. 36 list1[1] = "bb" # 対応する位置に直接値を代入する、すなわちResultを修正する。['a', 'bb', 'b', 'c', 'd' ]。
37 一括修正 38 ['a', 'bb', 'b', 'c', 'd'] の最初の2要素を置換して入れる 39 list1[0:2] = "boy" # result: ['b', 'o ', 'y', 'b', 'c', 'd'] となります。
40
41 6.削除 42 list1 = ['b', 'o', 'y', 'b', 'c', 'd']43 list1.pop () # デフォルトで最後の要素を削除する d
44 list1.remove ("o") #要素の削除 O removeは1つずつしか削除できません。
45 list1.remove (0) # 添え字0を持つ要素を削除する b
46 del list1[0] # 添え字0を持つ要素を削除する delはグローバル削除メソッドです。
47 del list1[0:2] #delは一括で削除できます。
48
49 7. for ループリスト50 list1 = [1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5]51 for i in list1: # list1 の要素をループするために for ループを使用します。
52 range (10) #0から10までの数字を生成する
53
54 8.ソート 55 list1 = ["1", "5", "3", "a", "b", "f", "c", "d", "A ", "C", "B" ] 56 list1.sort () # 結果です。[1', ' 3', '5', 'A', 'B', 'C', 'a', 'b', 'c', 'd', 'f ' ]。
57
58 並べ替えはASCIIの対応表で行う。59 reverse 60 list1.reverse () # result: ['f', 'd', 'c', 'b', 'a', 'C', 'B', 'A ', '5', '3', '1' ]。
61
62 9. 2つのリストを組み合わせる 63 #方法1
64 list1 = [1, 2, 3, 4, 5] 65 list2 = [6, 7, 8, 9] 66 list1 + list2 #Result: [1, 2, 3, 4, 5, 6, 7, 8, 9]
67 #メソッド2
68 list1.extend (list2) #list2 を list1 に拡張する。
69 結果 [1, 2, 3, 4, 5, 6, 7, 8, 9] 70
71 10. クリア72 #リストをクリアする
73 list2.clear () #リスト2をクリアする
74
75 11. コピー 76 浅いコピー 77 コピーリスト 78 list2 = list1.copy ()79 リストが1レベルのデータしか持たず、ネストしたリストがない場合、コピーしたリストは元のリストから完全に独立しています。80 リストが複数のレベルのネストを持つ場合、リストネストの中のリストの内容を元のリストと共有します。81 list1 .copy () # だからこれは次のように呼ばれます。浅いコピーです。
82
83 deepcopy: Python モジュールが必要84 importcopy85 list2 =copy.deepcopy (list1)86 deepcopy の後、新しいリストと古いリストは、リストのネストがあってもなくても、完全に別の存在になります87 二つのリストが独立しているかどうかは、リスト名に対応するメモリアドレスを見てわかります88 python インタープリタでメモリアドレスを見るには id(変数名)です。
コードを見る
タプル
What: 順序付き、不変のリスト
共通機能:インデックス、カウント、スライス
利用シーン ここのデータは変更できないことを知らせるための表示、データベース接続の設定情報など。
ハッシュ関数
hashは一般に"hash"と訳されるが、直訳すると"ハッシュ"となり、任意の長さの入力をハッシュアルゴリズムによって固定長の出力に変換し、それがハッシュ値である。この変換は圧縮マッピングである。つまり、通常、ハッシュの空間は入力の空間よりもずっと小さく、ありえない入力が同じ出力にハッシュ化されることがあるため、ハッシュから一意の入力値を決定することはできない。これは、任意の長さのメッセージを固定長のメッセージダイジェストに圧縮する関数に過ぎないのである。
特徴 ハッシュ値の計算過程は、その値の何らかの特徴に基づいているため、ハッシュ化される値は固定的でなければならない。(出力が一意になる保証はなく、衝突が起こりやすい)
用途:ファイル署名、md5暗号化、パスワード検証
コントラクトブロック.gif
拡張ブロック開始.gif
1 >>> ハッシュ("abc")2 -6784760005049606976
3 >>> ハッシュ((1,2,3))4 2528502973977326415
コードを見る
ディクショナリー
構文: info={}
特徴 1. キー-バリュー構造、キーはハッシュ可能、不変データ型、一意でなければならない
2. 各キーは値valueに対応しなければならず、valueは変更可能な任意の数の値を保持することができ、一意でない可能性がある
3. 辞書は順不同
辞書は、各キーを数値にハッシュ化できるため、検索が速い(数値はASCIIテーブルに従ってソートされる)。
辞書の手法:追加、削除、チェック、多段ネストなど。
コントラクトブロック.gif
拡張ブロック開始.gif
1 #Dictionary メソッド
2 info ={3 "student01": "aaa",4 "student02": "bbb",5 "student03": "ccc"
6 }7
8 #追加
9 info["student04"] = "ddd"
10 info["student05"] = "eeee"
11 info["student06"] = "fff"。
12
13 #クエリ
14 #student01が情報辞書にあるかどうか判断する
15 print("student01" in info ) # true を返す。
16 print(info.get("生徒01")))です。#aaa, noneを返します。
17 info["student01"] #対応する値を取得します。そのようなキーがない場合はエラーを返すので、通常はgetを使用します。
18
19 #delete
20 print(info.pop("student01"))です。#キー削除
21 print(info.popitem()) #ランダムキーの削除
22 del info["student02"] # 削除されたキー、もし削除されたキーがなければエラー KeyError: 'student01'
23
24 info.clear() #辞書をクリアする
25
26 #複数レベルの辞書のネスト
27 dic1 = {"aaa": {"aa": 11}, "bbb": {"bb ": 22}}28
29 #その他の方法
30 info ={31 "name1"。[22, "it"],32 "name2": [24, "hr "],33 "name3": 33
34 }35
36 info2 ={37 "name1"。44,38 "name4"。33,39 1: 2
40 }41 info.keys() # すべてのキーを表示する
42 info.values() #全ての値を表示する
43 info.items() #辞書をリストに変換する
44 info.update(info2) # 2つの辞書を1つにまとめる。キーが重複している場合は、info2の重複したキーがinfoのキーを上書きする。
45 info.setdefault("student07", "abcdef") # デフォルトのキー:値を設定する ,
46 # 情報辞書にキーstudent07が存在しない場合、情報辞書にstudent07:abcdefが追加されます。
47 #student07のキー値が手動で情報辞書に追加されている場合、student07:abcdefはここでは機能しません。
48 print(info.fromkeys(["name1", "name2"], "aaa") ) #反復可能なオブジェクトから キーと同じ値を一括生成する
49
50 #ディクショナリーループ:効率的なループ
51 for k ininfo:52 print(k,info[k]) # キーの値を表示する。
53
54 #もう一つの方法 非効率
55 for k,v in info.items()。# まず辞書をリストに変換してからループするので非効率的
56 print(k,v)
コードを見る
コレクション
セットとは、順序や重複のないデータの組み合わせのことである
役割:1.重複を排除する
2. 関係性テスト、2つのデータセット間の交差、差分、連結をテストする。
シンタックス
s = {} #空の場合、辞書になる
s = {1,2,3,4} # then it becomes a set set
s = {1,2,3,4,1,2} # データが重複している場合、重複を取り除いた結果を直接表示する {1, 2, 3, 4} 。
辞書を付与するためのリスト
l = [1,2,3,4,1,2]
l2 = set(l)
セットに関するメソッド
コントラクトブロック.gif
拡張ブロック開始.gif
1 #コレクションメソッド
2 s = {1,2,3,4,5} #コレクションを定義する
3
4 #追加
5 s.add(6)6 print(s) #{1, 2, 3, 4, 5, 6}.
7
8 #delete
9 #ランダム削除
10 s.pop()11 print(s) #{2, 3, 4, 5, 6}のようになります。
12 #削除指定,存在しない場合はエラー
13 s.remove(6)14 print(s) #{2, 3, 4, 5}.
15 #deleteを指定、存在しなければエラーにならない
16 s.discard(6)17 print(s)18
19 # Union other collections, can add multiple values.
20 s.update([7,8,9]) 21 print(s) #{2, 3, 4, 5, 7, 8, 9}のようになります。
22
23 #セットをクリアする
24 s.clear()25
26
27 #コレクションのリレーショナルテスト
28 iphone7 = {"alex", "rain", "jack", "old_driver "}29 iphone8 = {"alex", "shanshan", "jack", "old_boy" }30
31 #交差点
32 print(iphone7.intersection(iphone8))33 print(iphone7 &iphone8)34 #output.
35 {'jack', 'alex'}36 {'jack', 'alex'}. 37
38 #差分セット
39 print(iphone7.difference(iphone8)) 40 print(iphone7 - iphone8) 41 #output.
42 {'rain', 'old_driver'}43 {'rain', 'old_driver'}44
45 #merge 2つのリストを足し合わせる
46 print(iphone7.union(iphone8))47 print(iphone7 |iphone8)48 # 出力します。
49 {'rain', 'jack', 'old_driver', 'alex ', 'shanshan', 'old_boy'}50 {'rain', ' jack', 'old_driver', 'alex', 'shanshan', 'old_boy'}51
52 #対称型差分集合 交差していないものを取り出す
53 print(iphone7.symmetric_difference(iphone8))54 #output:
55 {'rain'、'old_driver'、'shanshan'、'old_boy'}56
57 s = {1,2,3,4}58 s2 = {1,2,3,4,5,6,}59 # superset Whoの親は誰か?
60 print(s2.issuperset(s)) #s2 は s の親である
61 print(s2 >=s)62 #出力されます。
63 真64 真65
66 #サブセット
67 print(s.issubset(s2)) #s は s2 のサブセットである
68 print(s <=s2)69 #出力されます。
70 真71 真72
73 # 2つの集合が不連続かどうかを判断する
74 print(s.isdisjoint(s2)) 75 # 出力。
76 False #は、2つの集合が交差していることを意味する
77
78 s = {1,2,3,-1,-2}79 s2 = {1,2,3,4,5,6}80 s.difference_update(s2) # s と s2 の差集合を求め、差集合を s に上書きする
81 print(s) #結果。{-2, -1}
82
83 s.intersection_update(s2) # s と s2 の交点を求め、s で上書きする。
84 print(s)85 print(s2)86 #結果です。
87 {1, 2, 3}88 {1, 2, 3, 4, 5, 6}
コードを見る
文字エンコーディング
パイソン3
ファイルエンコーディング デフォルト:utf-8
文字列のエンコーディング:Unicode
パイソン2
ファイルのエンコーディングのデフォルト:ascii
文字列のエンコーディング デフォルト:ASCII
ファイルヘッダがutf-8を宣言している場合、文字列のエンコーディングはutf-8になります。
unicodeは別のタイプです。
python3の記憶では:すべてユニコード
python3がコードを実行する場所。
1. インタプリタはコードファイルを見つけ、ファイルヘッダで定義されたエンコーディングでコード文字列をメモリにロードし、ユニコードに変換する
2、pythonの構文規則に従ってコード文字列を解釈する。
3. すべての変数文字はUnicodeエンコーディングで宣言されている
Python2では、デフォルトのエンコーディングはASCIIなので、ヘッダーでutf-8と宣言されたコードは、Windowsでは文字化けしてしまいます。
Windowsで正しく表示するには?(windowsのデフォルトエンコーディングはgbkです)
1. 文字列はgbkフォーマットで表示されます
2, 文字列はユニコードでエンコードされる
による修正
1. UTF-8 - >デコードデコード --> ユニコード
2.Unicode - > encode encoding - > GBK / UTF-8
コントラクトブロック.gif
拡張ブロック開始.gif
1 s="ルフィ学園都市"
2 print("decode before:",s)3 s2=s.decode("utf-8")4 print("decode after: ",s2)5 print(type(s2))6 s3=s2.encoded("gbk")7 print(s3)8 print(type(s3)))を実行する。
コードを見る
Pythonのバイトの種類
バイナリを16進数に変換した組み合わせをバイト型と呼びます。つまり、8個のバイナリを受け取り、16進数で表すバイトに整形する型です。
Python 2 では、bytes 型は本質的に文字列と区別がつきません。
str = バイト
utf-8 でエンコードされた python2 の文字列は、Windows では文字化けして表示されません。
python2のようなものを実装して、世界中の国のコンピュータで直接見られるようなソフトを書くにはどうしたらいいでしょうか?
ユニコード・エンコーディングでソフトを書く。
s = you_str.decode("utf-8")です。
s2= u"ルフィ"。
unicode型 文字列としてもカウントされます。
ファイルのヘッダーです。
python2: コード内容がメモリに読み込まれ、ユニコードに変換されない場合、エンコーディングはutf-8またはgbkのままです。
python3: utf-8またはgbkでエンコードされたコードは、メモリに追加されるときに自動的にunicodeに変換されます。
python3では、bytes型は主に画像や動画などのバイナリ形式のデータを格納するために使用されます。
str = ユニコード
グローバル言語エンコーディングはデフォルトでサポートされています
エンコードエラーの一般的な原因として
1. Python インタープリタのデフォルトエンコーディング
2. Pythonソースファイルのファイルエンコーディング
3, ターミナルが使用するエンコーディング(windows/linux/os)
4. OSの言語設定
I. モジュール、パッケージ
1. モジュールとは何ですか?
1. 同じ関数の関数をpyファイルにまとめることをモジュールと呼びます。
2. PY ファイルをモジュールと呼びます。
3. モジュールの利点は何ですか。
1、メンテナンスが容易である。
2. 変数名と関数名の衝突を減らすことができる。
4. モジュールの種類
1. サードパーティモジュール - 他人が書いたモジュール
2、組み込みモジュール - コンパイラに付属しているモジュール(例:os、sysなど)。
3, カスタムモジュール - 自分で書いたモジュール
5. モジュールのインポート方法
importコマンドでインポートする。例:import os(モジュール名)
2. パッケージとは何ですか?
1. 複数のモジュールを同じフォルダに入れたものをパッケージと呼びます。
2. フォルダがパッケージと呼ばれるにはもう一つ条件があります。__init__.pyモジュールがそのフォルダになければなりません。
3. モジュールとパッケージの違いについて
1. モジュール - py ファイルをモジュールと呼びます。
2. パッケージ - __init__.py があるフォルダをパッケージと呼びます。パッケージはその中に複数の py モジュールを持つことができます。
json、pickle
1. シリアライズとは何ですか?
1. メモリ内のデータを文字列に変換すること。
1. メモリデータをハードディスクに保存する。
2、メモリデータを他者に転送する(ネットワーク転送はバイナリ経由なので変換が必要)。
2. シリアライズのためのモジュールは、jsonとpickleの2つがある
2. jsonとpickleのメリット・デメリットを教えてください。
1、json - jsonでサポートされているデータを文字列に変換する
長所 サイズが小さい、クロスプラットフォーム。
短所:int, str, list, dict, tuple などの型しかサポートしていない。
2. pickle - Pythonでサポートされているすべての型を文字列に変換する
長所:すべてのパイソンデータ型をサポートする。
短所:Pythonプラットフォームでしか利用できないため、容量を多く消費する。
3. jsonとpickleには4つのメソッドがある
ロード , ロード , ダンプ , ダンプ
load: open関数のread fileメソッドでメモリデータを文字列に変換する
loads:メモリデータを文字列に変換する
dump:open関数のwrite fileメソッドで文字列を適切なデータ型に変換する。
dumps:文字列データを適切なデータ型に変換する。
棚上げ
1. シェルフとは何ですか?
1. shelveは、key,valueの形式でファイルをシリアライズするモジュールで、シリアライズされたデータはリストの形式をとっています。
2. 基礎となるパッケージはpickleモジュールで、pickleモジュールがサポートするデータ型に対応しています。
3. 複数のデシリアライズ操作を行うことができる。
ハッシュリブ
1. hashlibとは何ですか?
hashlibモジュール - 'hash'モジュールとしても知られています。
ハッシュ化アルゴリズムにより、長さが不定のデータセットを受け取り、そのデータの固定長のハッシュを生成することができます。
特徴
1. 固定長 - 可変長データの文字列を入力すると、固定長の数値のハッシュが生成されます。
2. 一意性 - 異なる入力で異なるデータを得ることができる。
2. md5
可変長データの文字列を入力し、128ビットの固定長データを生成する。
特徴
1. デジタル指紋 - 可変長のデータ列を入力すると、128ビットの固定長データ(デジタル指紋)が生成されます。
2. 単純計算 - 単純な計算で導き出すことができる。
3. 改ざんを入れる - 変更は稀であり、結果の値はすべて異なるものになる。
4. 強い衝突 - MD5値は既知であり、同じMD5値を見つけることは困難である。
機能
1. 関数とは何ですか?
関数名でカプセル化されたコードの集まりで、その関数名を呼び出すだけで呼び出すことができる。
どんなメリットがあるのでしょうか。
1. スケーラブル
2. 重複するコードの削減
3, メンテナンスが容易
2.関数への引数?
関数は引数を取ることができます。
形状のパラメータ。
1. 関数定義で指定する。
2. メモリ領域は、関数が呼び出されたときに確保され、関数の実行が終了したときに解放されます。
実パラメータ。
1. 定数、変数、式、関数などの形式をとることができる。
2. どのようなフォームであっても、フォームのパラメータにデータを渡すためには、明示的な値を持つ必要があります。
デフォルトのパラメータです。
1. デフォルトのパラメータは、関数が定義されるときに指定することができます(例:def func(a,b=1)
2. 参照渡しの際にデフォルトパラメータが指定されている場合はその値が、指定されていない場合はデフォルトパラメータの値が使用されます。
主要なパラメータ
1. 関数は順番に渡す必要があります。順番通りでない場合は、キーパラメータを使用することができます。
非固定パラメータ。
1. 非固定パラメータは、パラメータの数が不確定な場合に使用することができます。
2. 非固定パラメータには2種類ある。1. 1. *args - (入力されるパラメータはタプルとして表現される). 2. 2. **kwargs - (入力されるパラメータは、辞書として表現される)
3. 関数の戻り値
1、関数は操作の結果を返すことができる。
2. 関数は戻り値を持つことも、持たないこともできる。
戻り値あり - returnで返されます。
戻り値なし - 戻り値は None です。
3. 関数の実行の終了を表すreturnに遭遇する。
4. 関数の種類
ネストされた関数 - 関数は別の関数を含む。
高階関数 - 引数が他の関数を参照する関数、および戻り値が他の関数である関数。
匿名関数 - 関数名を明示的に指定しない関数(lambrda)で、mapやfilterと組み合わせて使用されることが多い。
再帰的関数
1. 関数が内部でその関数自身を参照している
2. その関数に明示的な終了条件がある。
再帰的な関数の特性。
1. 明示的な終了条件を持つ
2. 各再帰の大きさを小さくすること
3、再帰的な関数は効率的ではない
スコープ
1. 名前空間
名前空間は、変数名と変数値(eg:x=1)のバインディングを格納する場所です。
1. ネームスペースの種類
local: 関数の内部で、正式なパラメータとローカル変数を含む。
global: 関数が配置されているモジュールの名前空間。
buildin: 組み込み関数の名前空間。
2. 変数名のスコープの違いは、その変数名が存在する名前空間によって決定される。
グローバルスコープ:グローバルに生きている、グローバルに有効である。
ローカルスコープ:ローカルに生きている、ローカルに有効である。
2. スコープの検索順序
スコープ検索順。
ローカル-->囲み関数-->グローバル-->ビルトイン
local: 関数の内部で、正式なパラメータとローカル引数を含む。
enclosing function: 内部の関数。
global:関数が置かれているモジュール。
builtin:組み込み関数。
クロージャ
1. クロージャとは
1. 内部関数と外部関数をそれぞれ持つネストされた関数です。
2. 内側関数は外側関数の変数を使用します。
3. 外側関数は、内側関数のアプリケーションアドレスを返します。
4. そして、ネストされた関数はクロージャと呼ばれます。
2. クロージャーの意味
1. クロージャが返すオブジェクトは単なるオブジェクトではなく、関数のアウターラッパーのスコープを返す。
2. この関数が呼び出されるところでは、まずこの関数を包むスコープが使われます。
デコレーター
1. デコレーターとは
1. デコレーターとは、基本的にクロージャー関数のことです。
2. デコレーターの役割は、元の関数の呼び出し方を変えずに、コードに機能を追加することです。
関連
-
Python】import pandas, error pandas Missing required dependencies ['numpy'] Reason Analysis
-
pip Fatal error in launcher: を使用してプロセスを作成できません。
-
python3 failed to start Fatal Python error: initfsencoding: unable to load file system codec
-
Python がエラー xxx.whl はこのプラットフォームでサポートされているホイールではありませんと報告します。
-
Python3 reports AttributeError: '_io.TextIOWrapper' object has no attribute 'open'.
-
Python|ModuleNotFoundErrorを解決する。utils' という名前のモジュールがありません。
-
Python による pyserial 経由でのシリアルポートの読み取りと書き込み
-
Pythonのsum関数でTypeError: unsupported operand type(s) for +: 'int' and 'list' エラーを解決する。
-
Pythonの非パッケージ問題で相対インポートを試みる
-
Python ネットワークリクエストのエラー "ConnectionRefusedError: [WinError 10061] ターゲットコンピュータがアクティブに拒否したため接続できません"
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
python socket.error: [Errno 9] 不正なファイルディスクリプタに対する解決策
-
ImportError: 名前のインポートができない imsave エラー
-
ImportError: Windows の Django でプロジェクトを作成するとき、django.core solution という名前のモジュールがない。
-
AttributeError: モジュール 'time' には属性 'clock' がありません。
-
Python辞書
-
OperationalError: データベースファイルを開くことができない Solution
-
解決策 UnicodeDecodeError: 'gbk' コーデックは、位置 21804 のバイト 0x8b をデコードできません: 不正なマルチバイト配列です。
-
tkinter モジュールを使った Python 倉庫番ゲーム
-
Python2.7のエンコード問題:UnicodeDecodeError: 'ascii' codec can't decode byte 0xe8 in position... 解決方法
-
Pythonです。AttributeError: module 'numpy' has no attribute 'dtype' 問題が解決されました。