[解決済み] 二項探索木トラバーサル戦略(Preorder, Postorder, Inorder)をいつ使うか?
質問
私は最近、私の人生でBSTをたくさん使ってきた一方で、Inorder traversal以外のものを使おうと考えたことすらないことに気づきました(pre/post-order traversalを使うためにプログラムを適合させることがいかに簡単であるかは承知していますが)。
このことに気づいたとき、私は古いデータ構造の教科書をいくつか引っ張り出して、前置および後置走査の有用性の背後にある理由を探しましたが、それらはあまり述べていませんでした。
実際に preorder/postorder を使用する場合の例はどのようなものですか? いつそれが順不同よりも意味をなすのでしょうか?
どのように解決するのですか?
注文前、注文中、注文後のトラバーサル戦略をいつ使うか?
二分木に対してどのような状況でプレオーダー、インオーダー、ポストオーダーを使用するかを理解する前に、それぞれの探索戦略がどのように機能するかを正確に理解する必要があります。 次の木を例にしてみましょう。
この木のルートは 7 で、一番左のノードは 0 で、右端のノードは 10 .
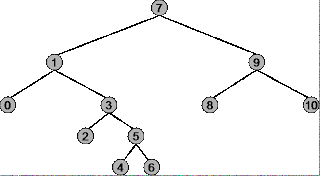
先行予約のトラバーサル :
概要:ルートから始まる( 7 ) で始まり、一番右のノードで終わり ( 10 )
トラバーサルシーケンスです。7, 1, 0, 3, 2, 5, 4, 6, 9, 8, 10
順方向探索 :
要約: 左端のノードから始まる ( 0 ) で始まり、右端のノード ( 10 )
トラバーサル シーケンス 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
ポストオーダートラバーサル :
概要:一番左のノードから開始する( 0 ) で始まり、ルート ( 7 )
トラバーサルシーケンスです。0, 2, 4, 6, 5, 3, 1, 8, 10, 9, 7
Pre-Order、In-order、Post-Order のどれを使うべきですか?
プログラマが選択する探索戦略は、設計されているアルゴリズムの特定のニーズに依存します。 目標はスピードなので、必要なノードを最も速くもたらす戦略を選びます。
-
葉を調べる前に根を探索する必要があるとわかっている場合、次のように選びます。 プレオーダー を選びます。なぜなら、すべての葉の前にすべての根に遭遇するからです。
-
どのノードよりも先にすべての葉を探索する必要があることが分かっている場合、以下のように選択します。 ポストオーダー を選択します。なぜなら、葉を探すために根を検査する時間を無駄にしないからです。
-
木がノードに固有のシーケンスを持っていることが分かっていて、 木を元のシーケンスに戻すために平らにしたい場合は インオーダー トラバーサルが使用されるべきです。 木は作られたときと同じ方法で平坦化される。 前順序または後順序の探索は、ツリーを作成するために使用されたシーケンスに戻るようにツリーを巻き戻さないかもしれません。
Pre-order、In-order、Post-order の再帰的アルゴリズム (C++):
struct Node{
int data;
Node *left, *right;
};
void preOrderPrint(Node *root)
{
print(root->name); //record root
if (root->left != NULL) preOrderPrint(root->left); //traverse left if exists
if (root->right != NULL) preOrderPrint(root->right);//traverse right if exists
}
void inOrderPrint(Node *root)
{
if (root.left != NULL) inOrderPrint(root->left); //traverse left if exists
print(root->name); //record root
if (root.right != NULL) inOrderPrint(root->right); //traverse right if exists
}
void postOrderPrint(Node *root)
{
if (root->left != NULL) postOrderPrint(root->left); //traverse left if exists
if (root->right != NULL) postOrderPrint(root->right);//traverse right if exists
print(root->name); //record root
}
関連
-
[解決済み】最小スパニングツリー。カットプロパティとは何ですか?
-
[解決済み] 補助データ構造とは何ですか?
-
[解決済み] なぜバイナリサーチツリーでHashtableを実装するのか?
-
[解決済み] フュージョンツリーを理解する?
-
[解決済み】2分木と2分探索木の違いについて
-
[解決済み】スキップリストとバイナリサーチツリーの比較
-
[解決済み] lenses, fclabels, data-accessor - 構造体アクセスと突然変異のためのどのライブラリが良いか
-
[解決済み] Clojureでリストが特定の値を含むかどうかをテストする
-
[解決済み] メモリ上でhexile/hexグリッドを表現するにはどうしたらよいですか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン