PostgreSQLのテーブルをパーティション分割する3つの方法
I. はじめに
テーブル・パーティショニングは、例えば、大きすぎる1つのテーブルによって引き起されるパフォーマンス問題のいくつかを解決する方法です。大きすぎるテーブルは、クエリの速度を低下させる原因となり、解決策としてパーティショニングを行うことがあります。一般的に、1つのテーブルのサイズがメモリを超える場合、テーブルパーティショニングを検討することをお勧めします。PostgreSQLでは、テーブルをパーティショニングする3つの方法があります。
- レンジ:レンジパーティショニング。
- リスト:リストパーティション。
- Hash: ハッシュパーティション。
この記事では、3種類のパーティショニングの方法を、例を挙げて説明します。
II. 3つの方法
便宜上、DockerでPostgreSQLを起動しますが、以下のコマンドで、Hashパーティションがサポートされないため、上位バージョンを選択する必要があります。
<ブロッククオートdocker run -itd \
--name pkslow-postgres \ \?
-e POSTGRES_DB=pkslow ୧⃛(๑⃙⃘◡̈๑⃙⃘)
-e POSTGRES_USER=pkslow ୧⃛(๑⃙⃘◡̈๑⃙⃘)
-e POSTGRES_PASSWORD=pkslow ୧⃛(๑⃙⃘◡̈︎๑⃙⃘)
-p 5432:5432 \
ポストグレス:13
2.1. レンジ範囲分割
まず年齢を表すテーブルを作成し、次に年齢区分に基づいてパーティションを設定し、以下のようにテーブル文を作成します。
CREATE TABLE pkslow_person_r (
age int not null,
city varchar not null
) PARTITION BY RANGE (age);
このステートメントでは、すでに年齢フィールドによるパーティショニングを指定し、パーティションテーブルを作成しています。
create table pkslow_person_r1 partition of pkslow_person_r for values from (MINVALUE) to (10);
create table pkslow_person_r2 partition of pkslow_person_r for values from (11) to (20);
create table pkslow_person_r3 partition of pkslow_person_r for values from (21) to (30);
create table pkslow_person_r4 partition of pkslow_person_r for values from (31) to (MAXVALUE);
ここでは、0歳から10歳、11歳から20歳、21歳から30歳、30歳以上に対応した4つのパーティションテーブルが作成されている。
次に、いくつかのデータを挿入します。
insert into pkslow_person_r(age, city) VALUES (1, 'GZ');
insert into pkslow_person_r(age, city) VALUES (2, 'SZ');
insert into pkslow_person_r(age, city) VALUES (21, 'SZ');
insert into pkslow_person_r(age, city) VALUES (13, 'BJ');
insert into pkslow_person_r(age, city) VALUES (43, 'SH');
insert into pkslow_person_r(age, city) VALUES (28, 'HK');
ここでもテーブル名が
pkslow_person_r
これは、特定のパーティションテーブルではなく、クライアント非対応であることを示しています。
にも問い合わせる。
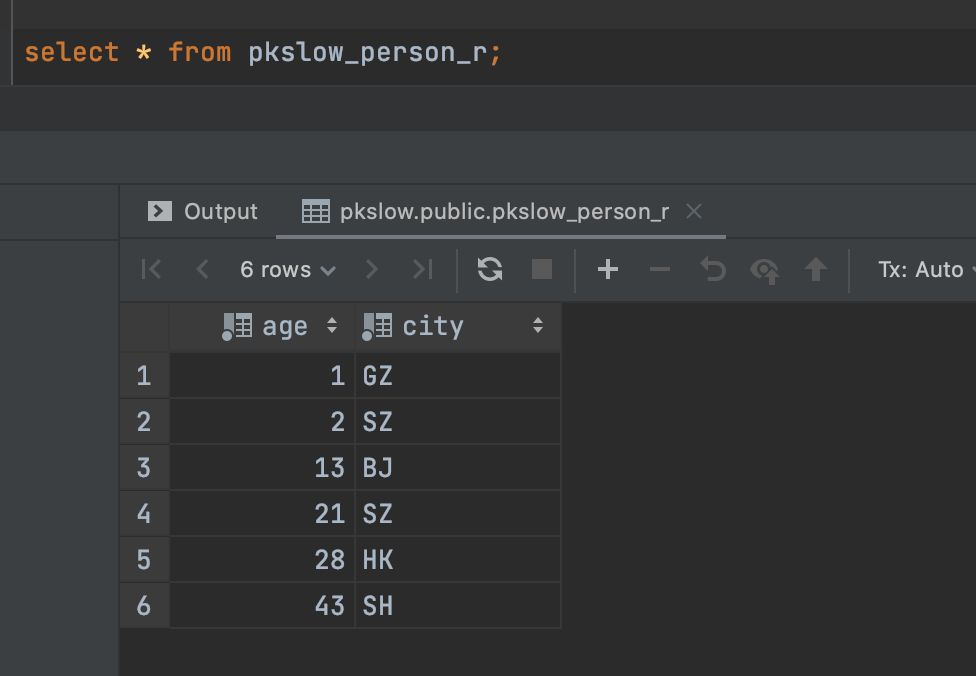
しかし、実際に存在するパーティションドテーブルは、以下の通りです。
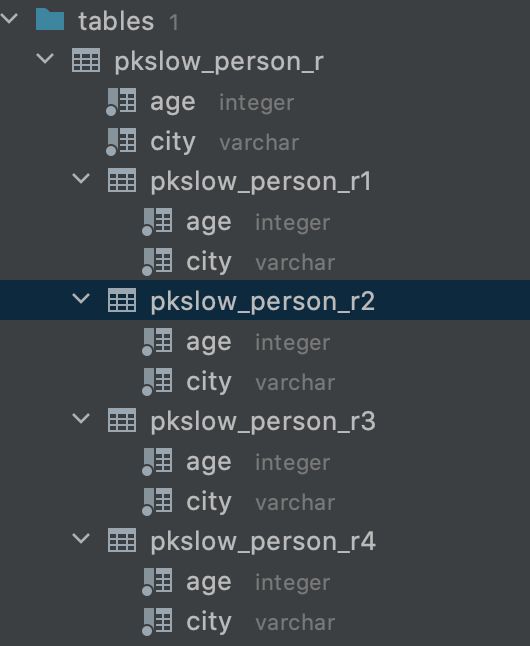
そして、パーティションされたテーブルのフィールドは、メイン・テーブルのフィールドと同じです。
パーティション分割されたテーブルに問い合わせると、その特定のパーティションのデータのみが表示されます。

2.2. リスト・パーティション
同様に、リスト・パーティショニングは、特定の値によるパーティショニングで、あるパーティションの特定の都市のデータを比較します。ここでは各ステップの説明は省きますが、コードは以下のようになります。
-- Create the main table
create table pkslow_person_l (
age int not null,
city varchar not null
) partition by list (city);
-- create partitioned table
CREATE TABLE pkslow_person_l1 PARTITION OF pkslow_person_l FOR VALUES IN ('GZ');
CREATE TABLE pkslow_person_l2 PARTITION OF pkslow_person_l FOR VALUES IN ('BJ');
CREATE TABLE pkslow_person_l3 PARTITION OF pkslow_person_l DEFAULT;
-- Insert test data
insert into pkslow_person_l(age, city) VALUES (1, 'GZ');
insert into pkslow_person_l(age, city) VALUES (2, 'SZ');
insert into pkslow_person_l(age, city) VALUES (21, 'SZ');
insert into pkslow_person_l(age, city) VALUES (13, 'BJ');
insert into pkslow_person_l(age, city) VALUES (43, 'SH');
insert into pkslow_person_l(age, city) VALUES (28, 'HK');
insert into pkslow_person_l(age, city) VALUES (28, 'GZ');
最初のパーティションに問い合わせたところ、広州のデータしかありませんでした。
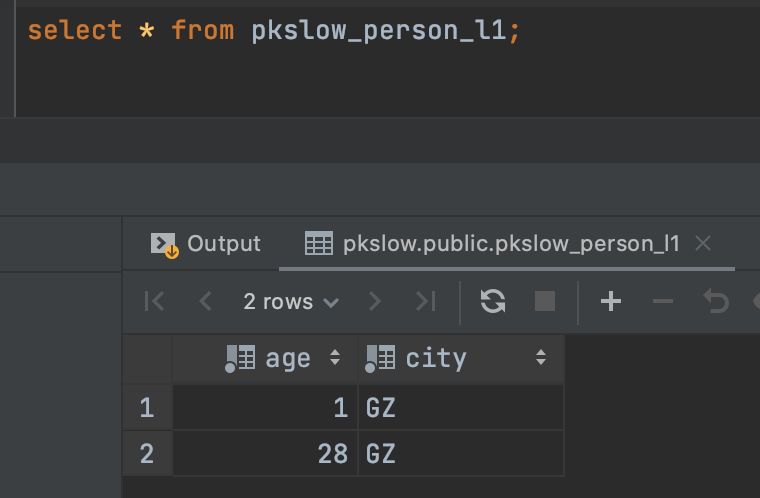
2.3. ハッシュハッシュパーティショニング
ハッシュパーティショニングとは、フィールドごとにハッシュ値を取り、それをパーティショニングすることである。具体的には以下のような記述になります。
-- Create the main table
create table pkslow_person_h (
age int not null,
city varchar not null
) partition by hash (city);
-- Create a partitioned table
create table pkslow_person_h1 partition of pkslow_person_h for values with (modulus 4, remainder 0);
create table pkslow_person_h2 partition of pkslow_person_h for values with (modulus 4, remainder 1);
create table pkslow_person_h3 partition of pkslow_person_h for values with (modulus 4, remainder 2);
create table pkslow_person_h4 partition of pkslow_person_h for values with (modulus 4, remainder 3);
-- insert into test data
insert into pkslow_person_h(age, city) VALUES (1, 'GZ');
insert into pkslow_person_h(age, city) VALUES (2, 'SZ');
insert into pkslow_person_h(age, city) VALUES (21, 'SZ');
insert into pkslow_person_h(age, city) VALUES (13, 'BJ');
insert into pkslow_person_h(age, city) VALUES (43, 'SH');
insert into pkslow_person_h(age, city) VALUES (28, 'HK');
パーティションド・テーブルを作るときにモジュロを使ったので、もしN個のパーティションド・テーブルを作りたいなら、N個のモジュロを取らなければならないことがわかりますね。
パーティションドテーブルのランダムクエリは、次のようになります。

同じSZのハッシュは同じで間違いなく同じパーティションになり、BJのハッシュもモジュロ後に同じパーティションになることがわかります。
III. まとめ
この記事では、PostgreSQLをパーティション分割する3つの方法について説明します。
コードは、こちらをご覧ください。 https://github.com/LarryDpk/pkslow-samples
以上、PostgreSQLのテーブル・パーティショニングの3つの方法について詳しく説明しましたが、PostgreSQLのテーブル・パーティショニングに関するより詳しい情報は、Script Houseの他の関連記事にも注目してください
関連
-
PostgreSQLのJSONBのマッチングと交差の問題について
-
Postgresqlの高度なアプリケーションは、セルのアイデアをマージするの詳細
-
Postgresqlのユーザーログインエラーの回数を制限するサンプルコード
-
PostgreSQLでデータの一括インポートのパフォーマンスを向上させるn個の方法を説明します。
-
PostgresqlのデータベーステーブルのデータをExcel形式にエクスポートする方法(推奨)
-
GROUP BY句での定数使用に関するPostgreSQLの特別な制限について説明します。
-
pgAdmin for postgreSQLでサーバーのデータをバックアップする方法
-
postgreSQLのクエリ結果に自己インクリメントシーケンス演算が追加されました。
-
oracle_fdwを介してOracleデータにアクセスするためのPostgreSQLの手順
-
PostgreSQLで時間指定タスクを実装する4つの方法
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
postgresql 重複データ削除 ケーススタディ
-
postgresのjsonbプロパティの利用について
-
Centos環境でのPostgresqlのインストールと設定、環境変数の設定Tips
-
Postgresqlの行から列への高度な応用と要約のアイデア
-
エクセルテーブルのデータをpostgresqlのデータベースにインポートする方法
-
どのように定期的にLinux上でpostgresqlのデータベースをバックアップする
-
PostgreSQLがバキュームテーブルの情報を収集する必要があることを発見する方法
-
Postgresqlのデータベースにおける配列の作成と変更に関する操作
-
PostgreSqlのhash_code関数の使用法
-
postgresqlのjsonbデータの問い合わせと変更方法