[解決済み] pandas - データフレームを行の要素で別のデータフレームでフィルタリングする
2023-05-08 16:48:09
質問
私はデータフレーム
df1
のようなものです。
c k l
0 A 1 a
1 A 2 b
2 B 2 a
3 C 2 a
4 C 2 d
という名前と、もうひとつ
df2
のようなものです。
c l
0 A b
1 C a
フィルタリングしたい
df1
にない値だけを残して
df2
. フィルタリングする値は、以下のようになります。
(A,b)
と
(C,a)
のタプルを作成しました。これまで、私は
isin
メソッドを使用しています。
d = df[~(df['l'].isin(dfc['l']) & df['c'].isin(dfc['c']))]
それはあまりにも複雑に思える、それが返されます。
c k l
2 B 2 a
4 C 2 d
が、期待しているのは
c k l
0 A 1 a
2 B 2 a
4 C 2 d
どのように解決するのですか?
これを効率的に行うには
isin
を使って効率的に行うことができます。
df1 = pd.DataFrame({'c': ['A', 'A', 'B', 'C', 'C'],
'k': [1, 2, 2, 2, 2],
'l': ['a', 'b', 'a', 'a', 'd']})
df2 = pd.DataFrame({'c': ['A', 'C'],
'l': ['b', 'a']})
keys = list(df2.columns.values)
i1 = df1.set_index(keys).index
i2 = df2.set_index(keys).index
df1[~i1.isin(i2)]
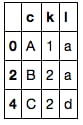
これは@IanSの類似の解決策を改善したものだと思います。なぜなら、これはどんな列型も仮定していないからです(すなわち、文字列と同様に数字でも動作します)。
(上記の回答は編集したものです。以下は私の最初の回答です)
面白いですね。これは私が前に遭遇したことがないものです...。私はおそらく、2つの配列をマージし、以下の行を削除することによってそれを解決するでしょう。
df2
が定義されている行を削除します。これは一時的な配列を使用した例です。
df1 = pd.DataFrame({'c': ['A', 'A', 'B', 'C', 'C'],
'k': [1, 2, 2, 2, 2],
'l': ['a', 'b', 'a', 'a', 'd']})
df2 = pd.DataFrame({'c': ['A', 'C'],
'l': ['b', 'a']})
# create a column marking df2 values
df2['marker'] = 1
# join the two, keeping all of df1's indices
joined = pd.merge(df1, df2, on=['c', 'l'], how='left')
joined
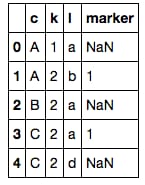
# extract desired columns where marker is NaN
joined[pd.isnull(joined['marker'])][df1.columns]
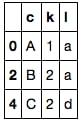
一時的な配列を使用せずにこれを行う方法があるかもしれませんが、私は思いつきません。データが巨大でない限り、上記の方法は高速で十分な答えになるはずです。
関連
-
[解決済み] PandasでDataFrameの行を反復処理する方法
-
[解決済み] 列の値に基づいてDataFrameから行を選択するにはどうすればよいですか?
-
[解決済み] Pandasのカラム名のリネーム
-
[解決済み] Pandas DataFrameからカラムを削除する
-
[解決済み] Pandasのデータフレームで複数の列を選択する
-
[解決済み] Pandas DataFrameの行数を取得する方法は?
-
[解決済み] 既存のDataFrameに新しい列を追加する方法は?
-
[解決済み] 一行ずつ追加してPandas Dataframeを作成する
-
[解決済み] pandasを使った "大量データ "ワークフロー【終了しました
-
[解決済み】Pandas DataFrameのカラムヘッダからリストを取得する。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] 列の値が設定された値のリストに含まれている場合、データフレームの行をフィルタリングする [重複] 。
-
[解決済み] 前月の日時オブジェクトを返す
-
[解決済み] PythonでファイルのMD5チェックサムを計算するには?重複
-
[解決済み] googletransがエラー 'NoneType' オブジェクトに 'group' 属性がない、と言って動かなくなった。
-
[解決済み] Pythonの要素別タプル演算(sumなど
-
[解決済み] Python 3でバイナリデータを標準出力に書き込むには?
-
[解決済み] Django Rest Framework ファイルアップロード
-
[解決済み] PyMongoで.sortを使用する
-
[解決済み] Pythonでマルチプロセッシングキューを使うには?
-
[解決済み] matplotlib でプロットの軸、目盛、ラベルの色を変更する方法