MySQLの基本的な使い方 (I)
データベース
1. データベースの概要
1.1 データベースの概要
データベースとは
データベースは、データを保存するためのリポジトリです。基本的にはファイルシステムであり、データは特定の形式で保存され、ユーザーはデータベース内のデータを追加、変更、削除、照会することができます。
小さな例
我々は今、データベースを持っていないと仮定すると、我々はローカルの電話帳ソフトウェアを開発したい、つまり、携帯電話のアドレス帳は、このソフトウェアは、記録の機能を持って、連絡先の名前、電話番号、誕生日、性別やその他の情報を記録する必要がある、それはデータを永続させることですので、我々は唯一のphone.txtなどのファイル、例えば、書き込むことができます。
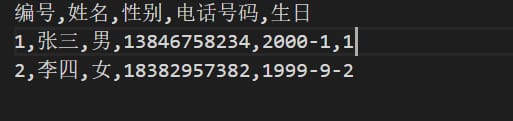
最初の行はテーブルのヘッダーで、他の行は内容で、データはカンマで区切り、各行はデータの一部で、設計は行ごとに読むことができるように、カンマで分割してJavaBeanに預けることができ、今プログラムアーキテクチャは次のようになります。
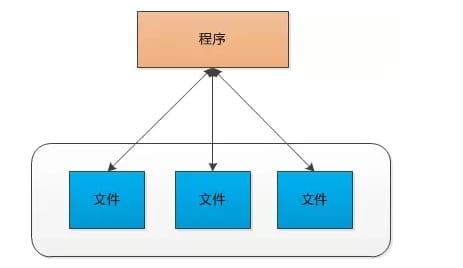
この機能は完璧に実装されましたが、プログラムが進化するにつれ、いくつかの問題が見つかりました。例えば、男性の電話番号をすべて見つけようとしたり、今日誕生日の人を見つけて、休日のメッセージを送ったりなど、常にコーディングを必要とし、基本的にファイルの情報を読み取ります。最悪の事態は、関数が何であれ、最初にすべてのハードディスクのデータをメモリにロードする必要があるということです。これらのデータは必要ない場合でも。すべてのコンピュータの問題は、中間層を追加することによって解決することができます"ので、中間層を追加することを感じる、論理データ構造上の中間層は、実際には、[番号、名前、性別、電話番号、誕生日】これらの事は、これらの事はテーブルと呼ばれ、それらの各々は、&quotと呼ばれ、列&quot、各列には文字型、日付型、デジタル型など、タイプを持っている必要があります。 , そして、プロフェッショナルなステートメントを使用してクエリを実行できるように、我々はそれをSQLと呼ぶことにしました、つまり、構造化問い合わせ言語構造化問い合わせ言語、そして今、ソフトウェア 現在、ソフトウェアのアーキテクチャは次のようになります。
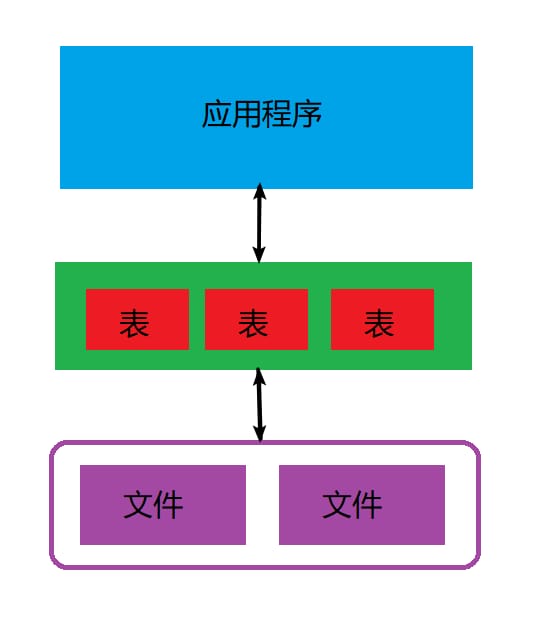
また、プログラムと物理層の間に抽象化レイヤーがあるため、インデックスやB+ツリーなどのキャッシュツールを用いて、上位アプリケーションのロジックに影響を与えずに物理層のストレージを最適化することが可能です
これはリレーショナルデータベースです
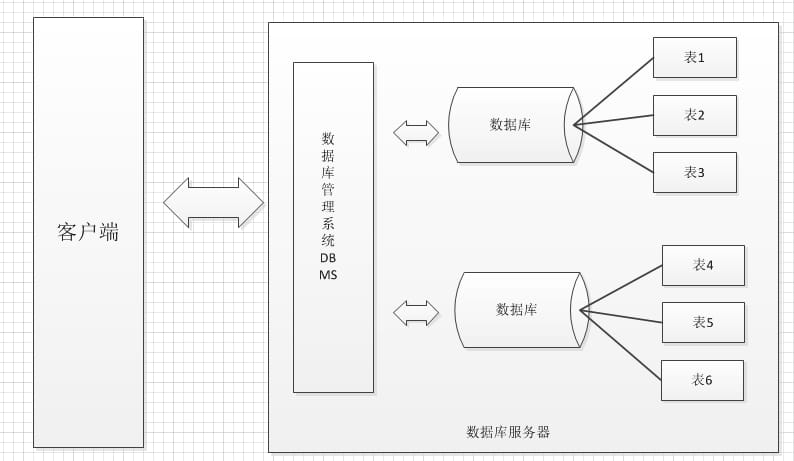
データベース管理システム
-
データベース管理システムとは
データベース管理システム(DataBase Management System、DBMS):大規模なソフトウェアを操作し、データベースを管理するために、確立するために使用される、使用すると、データベースのセキュリティと整合性を確保するために、データベースの統一管理と制御を指します。ユーザーは、DBMSを介してデータベース内のテーブルのデータにアクセスします。 -
一般的なデータベース管理システム
- MYSQL:オープンソースのフリーデータベース、小規模データベース。オラクルに買収されました。MySQLのバージョン6.xも充電を開始しました。
- オラクル オラクル社の製品である有料の大型データベース。オラクルはSUNを買収し、そのSUNがMYSQLを買収した。
- DB2:IBMのデータベース製品で、有償。銀行システムで使用されることが多い
- SQLServer MicroSoftの有料中型データベース、C#、.NETでよく利用される。
- SQLite。組み込み型小規模データベース、携帯電話で利用されている
-
データベースとデータベース管理システム
1.2 データベーステーブル
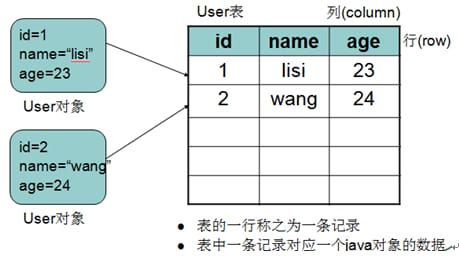
データは、テーブルという組織単位でデータベースに格納される。
テーブルは、Javaのクラスと似ていて、各フィールドに対応するデータ型があります。
そして、おなじみのjavaプログラムを使ってリレーショナルデータと比較すると、次のような対応関係があることがわかります。
1.3 データテーブル
テーブルのフィールドで指定されたデータ型に応じて、1つのデータで埋めることができ、テーブルの各データは、クラスのインスタンスオブジェクトに似ています。テーブルの情報行はレコードと呼ばれる
2. SQLステートメント
データベースはJAVAを知りませんが、私たちはデータベースとも対話しなければならないので、データベースがコードとして知っている言語であるSQL文を使う必要があるのです。
Structured Query Language(略してSQL)は、データへのアクセス、リレーショナルデータベースシステムの問い合わせ、更新、管理のためのデータベースクエリおよびプログラミング言語である。
データベースの作成、データテーブルの作成、データテーブルへのデータ情報の追加には、すべてSQL文が必要です。
3.1 SQLの分類
- Data Definition Language(データ定義言語)。DDL (Data Definition Language)の略で、データベースオブジェクト(データベース、テーブル、カラムなど)を定義するために使用されます。キーワード:create, alter, drop, etc.
- データ操作言語。DML (Data Manipulation Language)の略で、データベース内のテーブルのレコードを更新するために使用されます。キーワード:挿入、削除、更新、など。
- データ制御言語。DCL (Data Control Language)、データベースのアクセス権やセキュリティレベルの定義、ユーザーの作成に使用される
- データクエリ言語。DQL (Data Query Language)の略で、データベースのテーブルのレコードを照会するために使用される。キーワードは、select、from、whereなど。
3.2 SQL共通構文
-
SQL文は1行または複数行で書くことができ、最後はセミコロンで終わります。
-
文の可読性を高めるために、スペースとインデントを使用することができます。
-
MySQL データベースの SQL 文は大文字と小文字を区別しないので、SELECT * FROM user などのように大文字を使用することをお勧めします。
-
コメントは /*/ で補完することもできます。
-
MySQL の一般的なデータ型は次のとおりです。
<テーブル タイプ 説明 int 整数 ダブル 浮動小数点 varchar 文字列型 日付 日付型、形式はyyyy-MM-dd、年、月、日のみ、時、分、秒はなし
詳細なデータ型
MySQLは様々な型をサポートしており、それらは大きく分けて、数値型、日付/時刻型、文字列(キャラクタ)型の3つに分類することができます。
数値の種類
MySQL は、標準的な SQL の数値データ型をすべてサポートしています。
これには、厳密な数値データ型(INTEGER、SMALLINT、DECIMAL、NUMERIC)、近似的な数値データ型(FLOAT、REAL、DOUBLE PRECISION)が含まれます。
キーワードINTはINTEGERの同義語、キーワードDECはDECIMALの同義語です。
BITデータ型は、ビットフィールド値を保持し、MyISAM、MEMORY、InnoDB、BDBテーブルをサポートします。
標準SQLの拡張として、MySQLはTINYINT、MEDIUMINT、BIGINTの各整数型もサポートしています。以下の表は、各整数型が必要とするストレージと範囲を示しています。
浮動小数点数 DOUBLE 8バイト (-1.797 693 134 862 315 7 e+308, -2.225 073 858 507 201 4 e-308), 0, (2.225 073 858 507 201 4 e-308, 1.797 693 134 862 315 7 e+308) 0, (2.225 073 858 507 201 4 e-308, 1.797 693 134 862 315 7 e+308) 倍精度
浮動小数点数 デシマル DECIMAL(M,D)の場合、M>DならM+2、そうでなければD+2 MとDの値による M と D の値に依存する。 小さい値
日付と時刻のタイプ
時刻の値を表す日付と時刻の型は、DATETIME、DATE、TIMESTAMP、TIME、YEARです。
各時間型には有効な値の範囲と、MySQL が表現することが合法でない値を指定するときに使用する "ゼロ" 値があります。
TIMESTAMP型は、後述する独自の自動更新機能を備えています。
(バイト) 範囲 フォーマット 使用方法 日付 3 1000-01-01/9999-12-31 YYYY-MM-DD 日付の値 時間 3 '-838:59:59'/'838:59:59' HH:MM:SS 時間値または期間 年 1 1901/2155 YYYY 年 値 データタイム 8 1000-01-01 00:00:00/9999-12-31 23:59:59 yyyy-mm-dd hh:mm:ss 日付と時刻の混在した値 タイムスタンプ 4
1970-01-01 00:00:00/2038
終了時刻は、最初の 2147483647 秒、日本標準時 2038-1-19 11:14:07 日本時間2038年1月19日午前03時14分07秒
yyyymmdd hhmmss 日付と時刻の混在した値、タイムスタンプ文字列の種類
文字列型とは、CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM、SETを指します。このセクションでは、これらの型の動作とクエリでの使用方法について説明します。
<テーブル タイプ サイズ 使用 CHAR 0〜255バイト 固定長文字列 VARCHAR 0-65535バイト 可変長文字列 TINYBLOB 0〜255バイト 255文字以下のバイナリ文字列 TINYTEXT 0〜255バイト 短いテキスト文字列 BLOB 0-65 535バイト バイナリ形式の長いテキストデータ テキスト 0-65 535バイト 長いテキストデータ メディアムブロック 0~16 777 215 バイト バイナリ形式の中長テキストデータ MEDIUMTEXT 0~16 777 215 バイト 中長テキストデータ LONGBLOB 0-4 294 967 295 バイト バイナリ形式の極めて大きなテキストデータ LONGTEXT 0-4 294 967 295 バイト 非常に大きなテキストデータ
CHAR型とVARCHAR型は似ていますが、保存と取り出しの方法が異なります。また、最大長や末尾の空白を保存するかどうかという点でも異なります。保存や取り出しの際に大文字と小文字の変換は行われません。
BINARYクラスとVARBINARYクラスはCHARとVARCHARに似ていますが、バイナリ文字列を含み、非バイナリ文字列を含まないという点が異なります。つまり、文字列ではなく、バイト文字列を格納します。つまり、文字セットを持たず、列値のバイトに基づいて数値のソートと比較を行います。
BLOBは、可変長のデータを保持できるバイナリラージオブジェクトである。BLOBには4つのタイプがある。TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOBの4種類があり、保持できる値の最大長が異なるだけです。
TEXTタイプは4つあります。TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXTです。これらは、同じ最大長とストレージ要件を持つ4つのBLOBタイプに対応します。
3 SQL
3.1 DDL
データベース操作
- データベースを作成する
create database database name;
create database if not exists database name; -- create if not existing
- データベースの表示
MySQLサーバーにあるすべてのデータベースを表示します。
show databases;
- データベースの定義情報を表示する
show create database Database name;
- データベースの削除
drop database Database name;
- データベースの切り替え
use database name;
テーブル構造に関する記述
- テーブルの作成
フォーマット:
create table table name (
Field Name Type(length) Constraint,
field name type(length) constraint
);
例
CREATE TABLE sort (
sid INT, # sort ID
sname VARCHAR(100) # sort name
);
CREATE TABLE sort (
sid INT, #sort ID
sname VARCHAR(100) # sort name
) CHARSET=utf8;
-
主キー制約
主キーは、現在のレコードを識別するために使用されるフィールドです。NULLでなく、一意である。一般的に開発では、主キーは 意味を持たない で、現在のレコードを識別するためにのみ使用されます
フォーマット:
- テーブル作成時にプライマリーキーを作成し、フィールドの後にプライマリーキーを追加する。
CREATE TABLE table name (
id int primary key,
....
);
- テーブル作成時にプライマリキーを作成し、テーブル作成の最後にプライマリキーを指定する。
CREATE TABLE table name (
id int,
.... ,
primary key(id)
);
- 主キーを削除します。
alter table table name drop primary key;
- 主キー自己成長(MySQLのみ)
通常、主キーは自己成長するフィールドであり、指定する必要はありません。自己成長するステートメントを追加するには、主キーフィールドの後に auto_increment を追加するなどしてください。
CREATE TABLE sort (
sid INT PRIMARY KEY auto_increment, # sort ID
sname VARCHAR(100) # sort name
);
- 表示テーブル
データベース内のすべてのテーブルを表示する
show tables;
- テーブル構造を表示
desc Table name;
<イグ
- テーブルのビルドステートメントを表示する
show create table Table name;
- テーブルを削除する
フォーマット:
drop table Table name;
- テーブルの構造を変更する
カラムを削除する。
alter TABLE table name DROP column name;
テーブル名を変更します。
RENAME TABLE table name TO new table name;
テーブルの文字セットを変更する
alter TABLE table name CHARACTER SET character set
カラム名の修正
alter TABLE table name CHANGE column name new column name column type;
カラムの追加
alter table table name add column name column type;
3.2 DML操作
テーブルの全データを照会するステートメントを知ることから始めましょう。
SELECT * FROM table name;
DMLとは、テーブル内のデータを追加、削除、変更する操作のことです。DDLと混同しないように、DMLには.NET Frameworkが含まれています。
- INSERT:挿入
- UPDATE:更新
- DELETE:削除
トリビアです。
mysqlでは、文字列型と日付型はシングルクォートで囲む必要があります。'tom' '2015-09-04'
Null値:ヌル
3.2.1 挿入操作。INSERT。
構文
INSERT INTO table name (column name 1, column name 2 ...) VALUES(column value 1, column value 2 ...) ;
注意事項
- 列名は、列値の型、数、順序に対応する必要があります
- javaでは、カラム名を形式パラメータ、カラム値を実パラメータとして扱うことができます
- 値は列の定義の長さを超えてはいけません。
- null値を挿入する場合は、nullを使用します。
- 挿入された日付は、文字と同様に引用符で囲まれる
運動
empテーブルを作成し、以下のテーブル構造でデータを挿入してください。
<テーブル カラム名 カラムタイプ イド int 名前 varchar(100) 性別 varchar(10) 誕生日 日付 給与 フロート(10,2) 入力日 日付 履歴書 テキストcreate table emp(
id int,
name varchar(100),
gender varchar(10),
birthday date,
salary float(10,2),
entry_date date,
resume text
);
INSERT INTO emp(id,name,gender,birthday,salary,entry_date,resume)
VALUES(1,'zhangsan','female','1990-5-10',10000,'2015-5-5-','good girl');
INSERT INTO emp(id,name,gender,birthday,salary,entry_date,resume)
VALUES(2,'lisi','male','1995-5-10',10000,'2015-5-5','good boy');
INSERT INTO emp(id,name,gender,birthday,salary,entry_date,resume)
VALUES(3,'wangwu','male','1995-5-10',10000,'2015-5-5','good boy');
-- Batch insert
INSERT INTO emp VALUES
(4,'zs','m','2015-09-01',10000,'2015-09-01',NULL),
(5,'li','m','2015-09-01',10000,'2015-09-01',NULL),
(6,'ww','m','2015-09-01',10000,'2015-09-01',NULL);
3.2.2 修正操作。アップデイト
構文
UPDATE table name SET column name 1=column value 1, column name 2=column value 2... WHERE column name=value
エクササイズ
- すべての従業員の給与を5,000ドルに変更します。
UPDATE emp SET salary=5000
-
の名前を設定します。
zhangsan従業員の給与を$3000に設定
UPDATE emp SET salary=3000 WHERE name=' zhangsan';
-
名前を設定する
lisi従業員の給料を4000ドルに、仕事をcccに変更します。
UPDATE emp SET salary=4000,gender='female' WHERE name='lisi';
- すべての男性の元給に1000を加算
UPDATE emp SET salary=salary+1000 WHERE gender='male';
削除アクション
構文
DELETE FROM table name [WHERE column name=value]
エクササイズ
- テーブルからzhangsanという名前の行を削除します。
DELETE FROM emp WHERE name = 'zhangsan';
- テーブルのすべての行を削除する
DELETE FROM emp;
3.3 DQL操作
DQL データクエリ言語(重要)
DQLステートメントのデータベース実行は、データに変更を加えず、データベースがクライアントに結果セットを送信することを可能にします。
クエリによって返される結果セットは
仮想テーブル
.
構文
SELECT column name FROM table name
[WHERE -> GROUP BY -> HAVING -> ORDER BY]
SELECT selection_list / 問い合わせる列の名前 /
FROM table_list / 問い合わせるテーブルの名前 /
WHERE条件 / 列の条件 /
GROUP BY grouping_columns / です。 結果をグループ化する /
HAVING条件 / グループ化後の行条件 /
ORDER BY sorting_columns / (ソートする列の数 結果のグループ化 /
LIMIT offset_start, row_count / です。 結果資格 /
準備
テーブルstuの作成
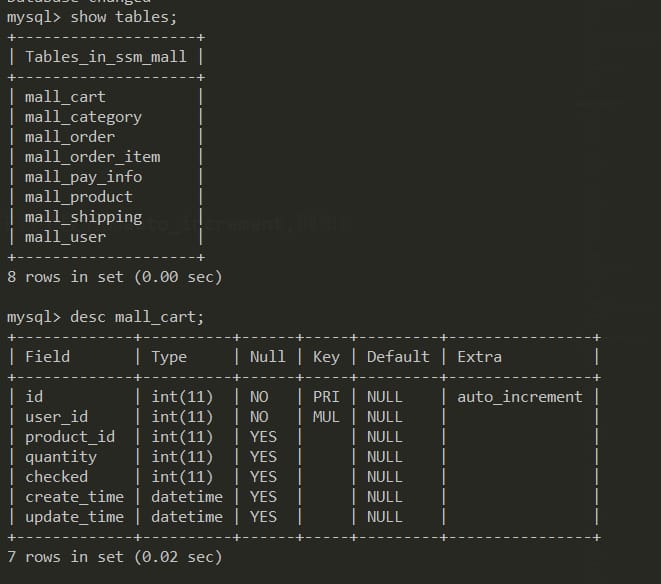
CREATE TABLE stu (
sid CHAR(6),
sname VARCHAR(50),
age INT,
gender VARCHAR(50)
);
INSERT INTO stu VALUES('S_1001', 'liuYi', 35, 'male');
INSERT INTO stu VALUES('S_1002', 'chenEr', 15, 'female');
INSERT INTO stu VALUES('S_1003', 'zhangSan', 95, 'male');
INSERT INTO stu VALUES('S_1004', 'liSi', 65, 'female');
INSERT INTO stu VALUES('S_1005', 'wangWu', 55, 'male');
INSERT INTO stu VALUES('S_1006', 'zhaoLiu', 75, 'female');
INSERT INTO stu VALUES('S_1007', 'sunQi', 25, 'male');
INSERT INTO stu VALUES('S_1008', 'zhouBa', 45, 'female');
INSERT INTO stu VALUES('S_1009', 'wuJiu', 85, 'male');
INSERT INTO stu VALUES('S_1010', 'zhengShi', 5, 'female');
INSERT INTO stu VALUES('S_1011', 'xxx', NULL, NULL);
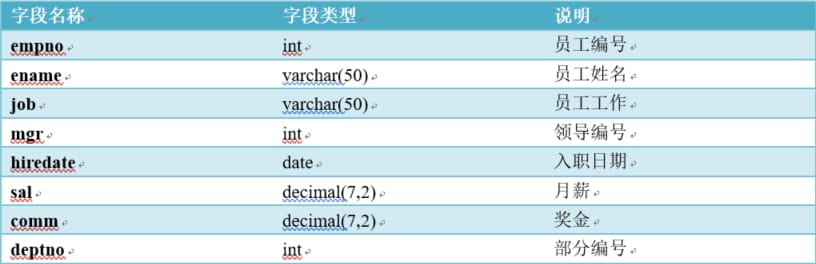
従業員テーブルの作成:emp

CREATE TABLE emp(
empno INT,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
comm decimal(7,2),
deptno INT
);
INSERT INTO emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp values(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp values(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp values(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp values(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp values(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp values(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp values(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp values(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
部分テーブル:dept
CREATE TABLE dept(
deptno INT,
dname varchar(14),
loc varchar(13)
);
INSERT INTO dept values(10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO dept values(20, 'RESEARCH', 'DALLAS');
INSERT INTO dept values(30, 'SALES', 'CHICAGO');
INSERT INTO dept values(40, 'OPERATIONS', 'BOSTON');
SELECT * FROM stu;
SELECT sid, sname, age FROM stu;
1. 基本的なクエリ
1.1 すべての列のクエリ
SELECT * FROM stu
WHERE gender='female' AND age<50;
SELECT * FROM stu
WHERE sid ='S_1001' OR sname='liSi';
SELECT * FROM stu
WHERE sid IN ('S_1001','S_1002','S_1003');
SELECT * FROM tab_student
WHERE s_number NOT IN ('S_1001','S_1002','S_1003');
SELECT * FROM stu
WHERE age IS NULL;
SELECT *
FROM stu
WHERE age>=20 AND age<=40;
<イグ
1.2 指定したカラムに問い合わせる
SELECT *
FROM stu
WHERE age BETWEEN 20 AND 40;
SELECT *
FROM stu
WHERE gender!='male';
<イグ
2. 条件付きクエリ
2.1 条件付きクエリ入門
- 条件付きクエリとは、WHERE句を持つクエリで、その中で以下の演算子やキーワードを使用することができます。
- =, ! =, <>, <, <=, >, >=.
- BETWEEN...AND.
- IN(セット)。
- はnull; is not null
- ANDです。
- OR
- NOT.
2.2 性別が女性、年齢が50歳の学生の情報を問い合わせる
SELECT *
FROM stu
WHERE gender<>'male';
<イグ
2.3 学籍番号S_1001、または名前liSiのレコードを問い合わせる
SELECT *
FROM stu
WHERE NOT gender='male';
SELECT *
FROM stu
WHERE sname IS NOT NULL;
<イグ
2.4 学生番号 S_1001、S_1002、S_1003 のレコードを問い合わせる
SELECT *
FROM stu
WHERE NOT sname IS NULL;
<イグ
2.5 学籍番号が S_1001、S_1002、S_1003 でないレコードを問い合わせる
SELECT *
FROM stu
WHERE sname LIKE '_____'
-- The LIKE keyword must be used for fuzzy queries. Where "_" matches any one letter and 5 "_" means 5 arbitrary letters
SELECT *
FROM stu
WHERE sname LIKE '____i';
SELECT *
FROM stu
WHERE sname LIKE 'z%';
-- where "%" matches any letter from 0 to n.
SELECT *
FROM stu
WHERE sname LIKE '_i%';
SELECT *
FROM stu
WHERE sname LIKE '%a%';
<イグ
2.6 年齢がNULLのレコードを問い合わせる
SELECT DISTINCT sal FROM emp;
2.7 20歳~40歳の学生のレコードを照会する
SELECT *,sal+comm FROM emp;
または
SELECT *,sal+IFNULL(comm,0) FROM emp;
<イグ
2.8 性別が男性でない学生のレコードを問い合わせる
SELECT *, sal+IFNULL(comm,0) AS total FROM emp;
または
SELECT *,sal+IFNULL(comm,0) total FROM emp;
または
order by column name asc/desc
<イグ
2.9 名前が NULL ではない学生レコードのクエリ
SELECT *
FROM stu
ORDER BY age ASC;
または
SELECT *
FROM stu
ORDER BY age;
SELECT *
FROM stu
ORDER BY age DESC;
SELECT * FROM emp
ORDER BY sal DESC,empno ASC;
3 ファジィクエリ
ひとつ以上の値にマッチするか、既知の値より大きいか小さいかをテストするか、あるいは値の範囲をチェックするかどうかにかかわらず、共通するのは、フィルターに使用する値が既知であるということです。しかし、このフィルタリング方法は常にうまくいくとは限りません。たとえば、a という文字を含む学生を検索する場合は、ファジー・クエリを使用する必要があります。ファジィクエリでは、キーワード LIKE
likeキーワードを使用する場合、ワイルドカード文字と一緒に使用されることが多いです。
-
ワイルドカード:一部の特殊文字にマッチさせるために使用します。
- _ : あらゆるものにマッチします。 a 文字
- % : 0〜nの任意の文字
3.1 5文字からなる名前の学生レコードのクエリ
SELECT COUNT(*) AS cnt FROM emp;
3.2 5文字の名前と5文字目に"i"を持つ学生レコードのクエリ
SELECT COUNT(comm) cnt FROM emp;
3.3 名前が "z" で始まる学生レコードの照会
SELECT COUNT(*) AS 'number of people' FROM emp
WHERE sal > 2500;
3.4 名前の2文字目がiである学生のレコードを問い合わせる
SELECT COUNT(*) AS cnt FROM emp WHERE sal+IFNULL(comm,0) > 2500;
3.5 名前に "a" を含む学生レコードを照会する
SELECT COUNT(comm), COUNT(mgr) FROM emp;
4. フィールドコントロールクエリ
4.1 重複する行の削除
重複行(系列上に同じデータを持つ2つ以上の行)を削除します。例えば、empテーブルのsalフィールドが同じレコードを持っているとします。empテーブルのsalフィールドのみがクエリされた場合、重複したレコードが存在するため、重複したレコードを削除するには、DISTINCT
SELECT SUM(sal) FROM emp;
<イグ
データは重複していません
4.2 ある従業員の月給と歩合の合計を表示する
sal列とcomm列はともに数値型なので、足し算の操作ができます。salまたはcommのフィールドのいずれかが数値型でない場合は、エラーが発生します。
SELECT SUM(sal), SUM(comm) FROM emp;
<イグ
また、comm列はNULL値を持つ行が多く、NULLに何を加えてもNULLのままなので、決済結果がNULLになることがあります。NULLを値0に変換する次の関数IFNULLが使用されます。
SELECT SUM(sal+IFNULL(comm,0)) FROM emp;
<イグ
4.3 カラムにエイリアスを追加する
上のクエリでは、カラム名が sal+IFNULL(comm,0) と表示されていますが、これは魅力的ではありません。そこで、このカラムに total という別名を付けてみましょう。
SELECT AVG(sal) FROM emp;
<イグ
列のエイリアスを行う場合、ASキーワードを省略することが可能である。
SELECT MAX(sal), MIN(sal) FROM emp;
5.ソート
並べ替えは
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno;
という構文で
デフォルトはasc(昇順) desc(降順)を指定できます。
5.1 年齢で昇順に並べられた、すべての生徒の記録を照会する
SELECT deptno,COUNT(*)
FROM emp
GROUP BY deptno;
または
SELECT deptno,COUNT(*)
FROM emp
WHERE sal>1500
GROUP BY deptno;
<イグ
5.2 年齢で降順に並べられたすべての生徒の記録を照会する
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno
HAVING SUM(sal) > 9000;
<イグ
5.3 月給の降順、または月給が同じ場合は番号の昇順で並べられた全従業員へのクエリ
SELECT
job,
deptno,
avg(sal)
FROM emp
GROUP BY job, deptno
HAVING avg(sal) > 1000;
<イグ
6. 集計機能
集計機能は、垂直方向の演算を行うために使用する機能です
- COUNT():指定したカラムがNULLでないレコードの行数を数えます。
- MAX():指定された列の最大値を計算する。指定された列の型が文字列の場合、文字列ソート操作を使用する。
- MIN():指定された列が文字列の場合、文字列ソートを使用して、指定された列の最小値を計算する。
- SUM():指定された列の数値和を計算する。指定された列の型が数値でない場合は0を計算する。
- AVG():指定された列の平均値を計算する。指定された列の型が数値型でない場合は 0 となる。
6.1 COUNT
COUNT()は、縦に数える必要があるときに使用され、COUNT括弧は、指定された列名に置くことができ、*場合は*クエリは、結果セットの行数であることを意味し、それは列名であれば、それは指定した列の行数であることです
empテーブルの行数を問い合わせる
SELECT * FROM emp LIMIT 0, 5;
<イグ
empテーブルのコミッションを持つ人数を問い合わせる
SELECT COUNT(comm) cnt FROM emp;
<イグ
comm 列に count() 関数が与えられているので、comm 列の非 NULL 行だけがカウントされることに注意してください。
empテーブルの中で、月給が2500以上の人の数を問い合わせます。
SELECT COUNT(*) AS 'number of people' FROM emp
WHERE sal > 2500;
<イグ
月給と歩合の合計が2,500ドル以上である人の人数を数える
SELECT COUNT(*) AS cnt FROM emp WHERE sal+IFNULL(comm,0) > 2500;
<イグ
リーダーとのコミッションを持つ人数を確認する
SELECT COUNT(comm), COUNT(mgr) FROM emp;
<イグ
6.2 SUMとAVG
縦方向の合計が必要な場合は、sum()関数を使用します。平均が必要な場合は、avg()関数を使用します。
- 全従業員の月給の合計を照会する
SELECT SUM(sal) FROM emp;
<イグ
- 全従業員の月給合計と全従業員の歩合合計を問い合わせる
SELECT SUM(sal), SUM(comm) FROM emp;
<イグ
- 全従業員の月給+歩合給を照会し
SELECT SUM(sal+IFNULL(comm,0)) FROM emp;
<イグ
- 全従業員の平均給与に関する統計
SELECT AVG(sal) FROM emp;
<イグ
6.3 MAXとMIN
MAXとMINは、最大値と最小値を問い合わせるために使用します。
- 従業員の給与の最高額と最低額を照会します。
SELECT MAX(sal), MIN(sal) FROM emp;
<イグ
7. グループ化されたクエリ
GROUP BY句は、グループ化されたクエリーが必要な場合に使用します。たとえば、各部門の給与の合計を照会する場合、部門を使用してグループ化することを意味します。
<ブロッククオート
注
集約関数と一緒に出てくる列名は、group byの後に書かなければなりません。
グループ化しても個々のデータが反映されない
group byは一般的に集計関数と組み合わせて使用され、単独で使用する場合はあまり意味がない
7.1 グループ化されたクエリ
- 各部門の番号と各部門の給与と.を問い合わせる。
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno;
<イグ
- 各部門の部門番号と各部門の人数を問い合わせる
SELECT deptno,COUNT(*)
FROM emp
GROUP BY deptno;
<イグ
- 各部署の人数と、各部署で給与が1500を超える人数を問い合わせる。
SELECT deptno,COUNT(*)
FROM emp
WHERE sal>1500
GROUP BY deptno;
<イグ
7.2 HAVING フレーズ
- 部署番号と給与総額が9000以上の部署の給与総額を照会します。
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno
HAVING SUM(sal) > 9000;
<イグ
持つ」と「居る」の違い
- havingはグループ化した後にデータをフィルタリングすること、whereはグループ化する前にデータをフィルタリングすること。
- havingの後に集約関数(統計関数)を使用することはできますが、whereの後には使用できません。
WHEREは、グループ化される前の行に対する条件です。行がWHERE句の条件を満たさない場合、その行はグループ化されません。そしてHAVINGはグループ化された後のデータに対する制約です

- 各部門の役職ごとの平均給与>1000に関する統計情報
SELECT
job,
deptno,
avg(sal)
FROM emp
GROUP BY job, deptno
HAVING avg(sal) > 1000;
<イグ
8. リミット
LIMITは、クエリ結果の開始行と、行の総数を制限するために使用します。
- 0から始まる5行のクエリ
SELECT * FROM emp LIMIT 0, 5;
<イグ
クエリ文の記述順。
select - from - where - group by - having - order by-limit
クエリ文の実行順序。
<ブロッククオートfrom - where -group by - having - select - order by-limit
関連
-
MYSQL "Access denied; you need (at least one of) SUPER privilege(s) for this operation" 問題解決
-
親行が削除または更新できない: 外部キー制約に失敗 解決策
-
unixODBC:データソース名が見つからない、デフォルトドライバが指定されていないに関する質問
-
Hibernateでhibernate.propertiesが見つからない問題とデータベース方言の更新の問題
-
MySQLデータベースのクエリ機能を使用する際に、グループ関数の使用が無効である問題の解決方法
-
SQL SERVER データベース SELECT INTO および INSERT INTO の使用法(テンポラリテーブルへのデータ挿入を含む)
-
は、GROUP BY句に含まれるか、集約関数で使用される必要があります。
-
DB2 SQL エラーの解決法。sqlcode=-420, sqlstate=22018
-
AttributeError: 'function' オブジェクトには 'cursor' という属性がありません。
-
mysql: この操作には (少なくとも 1 つの) RELOAD 権限が必要です。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
mysql reports Access denied; you need (at least one of) SUPER privilege(s) for this operation
-
この操作を行うには、少なくとも1つのSUPER権限が必要です。
-
2021MySql-8.0.26インストール詳細チュートリアル(ベビーシッターレベル)
-
(NTDLL.DLL): 0xC0000005: アクセス違反 - 解決
-
ERROR 1046 (3D000)の解決策です。MySQLでアカウント削除時にデータベースが選択されない問題
-
IEntityChangeTracker の複数のインスタンスからエンティティオブジェクトを参照できない場合の対処法
-
Postgresql でテーブル "t" の FROM 句の項目が見つからない。
-
Oracleデータベースの挿入データエラーです。ORA-06550
-
アプリケーションから DB2 SQL Error が報告され続けます。SQLCODE=-302, SQLSTATE=22001, SQLERRMC=null, DRIVER=4.17.29
-
PDOデータベース接続エラー。SQLSTATE[HY000] [2002] そのようなファイルやディレクトリはありません。