[解決済み] MarketWatchからデータを取得する
2022-03-02 09:25:36
質問
BeautifulSoupを使って、MarketWatchをスクレイピングしようとしています。
from bs4 import BeautifulSoup
import requests
import pandas
url = "https://www.marketwatch.com/investing/stock/khc/profile"
# Make a GET request to fetch the raw HTML content
html_content = requests.get(url).text
soup = BeautifulSoup(html_content, "lxml")
では、"を抜き出してみたいと思います。 現在のPER "と" 株価収益率 htmlにあるのはクラスです。
[...]
<div class="sixwide addgutter">
<div class="block threewide addgutter">
<h2>Valuation</h2>
<div class="section">
<p class="column">P/E Current</p>
<p class="data lastcolumn">19.27</p>
</div>
<div class="section">
<p class="column">P/E Ratio (with extraordinary items)</p>
<p class="data lastcolumn">19.55</p>
</div>
<div class="section">
<p class="column">P/E Ratio (without extraordinary items)</p>
<p class="data lastcolumn">20.00</p>
</div>
<div class="section">
<p class="column">Price to Sales Ratio</p>
<p class="data lastcolumn">1.55</p>
</div>
<div class="section">
<p class="column">Price to Book Ratio</p>
<p class="data lastcolumn">0.75</p>
</div>
[...]
どうすれば入手できますか?
私はコマンドを使用します
section = soup.findAll('div', {'class' : 'section'})
しかし、その後、私は私が興味を持っている値を取得するために先に行く方法がわからない、あなたは助けることができますか?
どのように解決するのですか?
このソリューションでは、以下のすべてのセクションからデータを取得します。
div
クラス "sixwide addgutter" を持つ。結果は、辞書のリストという形になります。
soup = BeautifulSoup(req.content, 'lxml')
base = soup.find('div', attrs={'class' : 'sixwide addgutter'})
section = base.find_all('div', attrs={'class' : 'section'})
all_data=[]
for item in section:
data = {}
data['name']=item.p.text
data['value']=item.p.findNext('p').text
all_data.append(data)
出力サンプルです。
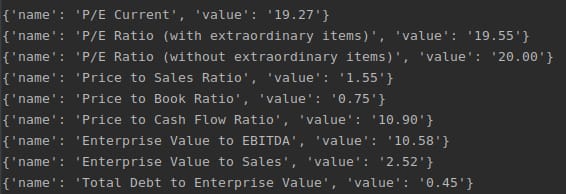
具体的に知りたい方は、"PER Current"と"Price to Sales Ratio"をご覧ください。
all_data[0]
,
all_data[3]
をそれぞれ作成します。
関連
-
Python Decorator 練習問題
-
[解決済み】TypeError: unhashable type: 'numpy.ndarray'.
-
[解決済み] Pythonで現在時刻を取得する方法
-
[解決済み] 列の値に基づいてDataFrameから行を選択するにはどうすればよいですか?
-
[解決済み] リストの最後の要素を取得する方法
-
[解決済み] Pythonで文字列の部分文字列を取得するにはどうすればよいですか?
-
[解決済み] Pythonの辞書からキーを削除するにはどうしたらいいですか?
-
[解決済み] リストの要素数を取得する方法
-
[解決済み] リストからランダムに項目を選択するにはどうすればよいですか?
-
[解決済み】Pandas DataFrameのカラムヘッダからリストを取得する。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Python関数の高度な応用を解説
-
Pythonショートビデオクローラーチュートリアル
-
Python Pillow Image.save jpg画像圧縮問題
-
[解決済み】OSError: [WinError 193] %1 は有効な Win32 アプリケーションではありません。
-
[解決済み】TypeErrorを取得しました。エントリを持つ子テーブルの後に親テーブルを追加しようとすると、 __init__() missing 1 required positional argument: 'on_delete'
-
[解決済み] builtins.TypeError: strでなければならない、bytesではない
-
[解決済み】LogisticRegression: Pythonでsklearnを使用して、未知のラベルタイプ: '連続'を使用しています。
-
[解決済み】ImportError: bs4という名前のモジュールがない(BeautifulSoup)
-
[解決済み】ValueError: xとyは同じサイズでなければならない
-
[解決済み] python BeautifulSoup テーブルのパース