[解決済み] Map Reduce Programmingにおけるreducerのshufflingとsortingフェーズの目的は何ですか?
質問内容
Map Reduceプログラミングでは、reduceフェーズはシャッフル、ソート、reduceをサブパートとして持っています。ソートはコストがかかる。
Map Reduce Programmingのreducerにおけるshufflingとsortingフェーズの目的は何でしょうか?
どのように解決するのですか?
まずはじめに
shuffling
は、マッパーからリデューサーにデータを転送する処理なので、そうしないとリデューサーがインプット(すべてのマッパーからインプット)できないので、必要なのは当然だと思います。シャッフルは、時間を節約するために、マップ段階が終了する前でも開始することができます。マップのステータスがまだ100%でないときに、リデュースのステータスが0%より大きい(しかし33%より小さい)ことがあるのはそのためです。
Sorting
は、reducer の時間を節約し、新しい reduce タスクがいつ開始されるべきかを簡単に区別できるようにします。簡単に言うと、ソートされた入力データの次のキーが前のキーと異なるときに、新しいリデュースタスクを開始するだけです。各 reduce タスクはキーと値のペアのリストを受け取りますが、key-list(value) を入力とする reduce() メソッドを呼び出さなければならないので、キーで値をグループ化しなければなりません。もし入力データがマップフェーズであらかじめ(ローカルに)ソートされ、リデュースフェーズで単にマージソートされるなら、そうするのは簡単です(リデューサーは多くのマッパーからデータを取得するので)。
Partitioning
また、回答者の一人が言っていた、"Science "は、別の処理です。Mapフェーズの出力である(キー、値)ペアがどのreducerに送られるかを決定するものです。デフォルトのパーティショナーは、キーにハッシュを使用してリデュースタスクに分配しますが、それをオーバーライドして独自のカスタムパーティショナーを使用することができます。
これらの手順に関する素晴らしい情報源は、次のとおりです。 Yahooチュートリアル ( アーカイブス ).
これをうまく図式化すると次のようになります(この図ではシャッフルを"copy"と呼んでいます)。
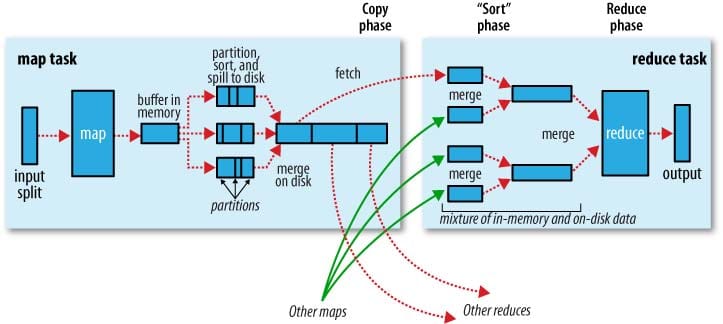
なお
shuffling
と
sorting
は、リデューサをゼロに指定した場合(setNumReduceTasks(0))には、全く実行されません。そして、MapReduceジョブはマップフェーズで停止し、マップフェーズにはいかなるソートも含まれません(したがって、マップフェーズでさえも高速になります)。
UPDATEしてください。
より正式なものをお探しなら、Tom Whiteの著書 "Hadoopもご覧ください。The Definitive Guide"」があります。
こちら
が、ご質問の興味深い部分です。
Tom Whiteは2007年2月からApache Hadoopのコミッターで、Apache Software Foundationのメンバーでもあるので、かなり信憑性の高い公式なものだと思うのですが......。
関連
-
[解決済み] Elasticsearchがフィルタにないフィールドの値で注文する。
-
[解決済み] 負の整数の基数ソート
-
[解決済み] Map Reduce Programmingにおけるreducerのshufflingとsortingフェーズの目的は何ですか?
-
[解決済み] サイズnとmの2つのソートされた配列をマージする際の時間複雑度
-
[解決済み] Scalaで配列を並べ替えるには?
-
[解決済み] Haskellでは、どのように私はペア(タプル)のリストを並べ替えるために組み込みのsortBy関数を使用することができますか?
-
[解決済み] 構造体の配列を(任意の)フィールド名で単純にソートする最短の方法は何ですか?
-
[解決済み] 山積みされた靴下を効率よく組み合わせるには?
-
[解決済み】.NETでMapとReduceを行う。
-
[解決済み] ElasticSearchでソートするためのフィールドのマッピングが見つかりません。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] Elasticsearchがフィルタにないフィールドの値で注文する。
-
[解決済み] 負の整数の基数ソート
-
[解決済み] Map Reduce Programmingにおけるreducerのshufflingとsortingフェーズの目的は何ですか?
-
[解決済み] サイズnとmの2つのソートされた配列をマージする際の時間複雑度
-
[解決済み] Scalaで配列を並べ替えるには?
-
[解決済み] Haskellでは、どのように私はペア(タプル)のリストを並べ替えるために組み込みのsortBy関数を使用することができますか?
-
[解決済み] 構造体の配列を(任意の)フィールド名で単純にソートする最短の方法は何ですか?
-
[解決済み] ElasticSearchでソートするためのフィールドのマッピングが見つかりません。