機械学習 KNN 最近傍分類アルゴリズム
先日、巨大な人工知能の学習サイトを発見し、分かりやすく、面白く、ユーモラスで、皆にシェアせずにはいられなかった。 クリックするとチュートリアルに飛びます .
KNNアルゴリズムの紹介
KNN(K-Nearest Neighbor)分類アルゴリズムは、データマイニングの分類手法の中で最もシンプルなアルゴリズムの一つで、「"自分に近い人ほど有利"」、つまり自分のカテゴリは隣人から推測されるという考えに基づいて導かれるものである。

KNN最近傍分類アルゴリズムの実装原理。未知サンプルのクラスを決定するために、既知のクラスの全サンプルを基準として、未知サンプルと全既知サンプル間の距離を計算し、その中から未知サンプルと最も距離が近いK個の既知サンプルを選択し、多数決ルールに従って、未知サンプルとクラスに属するK個の最近傍サンプルをグループ化します。 未知サンプルはK個の最近傍サンプルと一つのカテゴリーに分類されます。
これは分類タスクのための KNN アルゴリズムの基本原理で、実際には文字 K は選択される最も近いサンプルインスタンスの数を意味し、 scikit-learn では KNN アルゴリズムの K 値は n_neighbors パラメータで調整されます、デフォルト値は 5 です。
下図のように、緑色の丸が赤い三角形と青い四角形のどちらのクラスに属するべきかを判断するには、どうすればよいでしょうか。K=3の場合、赤い三角形は2/3なので緑の円は赤い三角形のクラスに属すると判定され、K=5の場合、青い四角形は3/5なので緑の円は青い四角形のクラスに属すると判定されます。
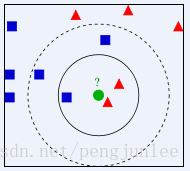
KNN最近傍分類アルゴリズムでは、クラス領域を判別して分類するのではなく、分類判定で最も近いサンプルまたはサンプルのクラスに基づいて分類するため、クラス領域の交差や重複が多い分類対象サンプルの集合には、他の方法よりもKNN法が適しています。
KNNアルゴリズムのポイント
(1) サンプルの全特徴を比較定量化する
サンプルフィーチャーに非数値型がある場合、それを数値化する手段を講じる必要がある。例えば、サンプルの特徴に色が含まれている場合、色をグレースケール値に変換することで距離計算を行うことができる。
(2) 正規化するサンプル特徴量
サンプルには複数のパラメータがあり、それぞれに定義と値の範囲があり、大きな値が小さな値を上書きするように、距離計算への影響も異なる。そのため、サンプルのパラメータは何らかの方法でスケーリングする必要があります。最も簡単な方法は、すべての特徴量の値を正規化することです。
(3) 2つのサンプル間の距離を計算するための距離関数が必要である
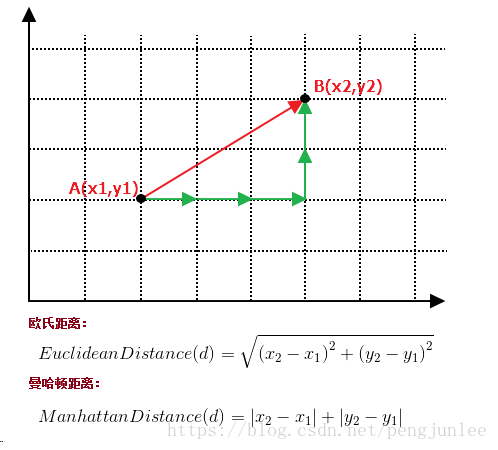
よく使われる距離関数としては ユークリッド距離、コサイン距離、ハミング距離、マンハッタン距離などです。一般に距離尺度としてはユークリッド距離が選ばれるが、これは連続変数の場合のみである。テキスト分類のような非連続変数の場合は、ハミング距離を距離指標として用いることができる。通常、ラージエッジ最近傍法や最近傍成分分析法などの特殊なアルゴリズムを使用してメトリックを計算すると、K-最近傍分類の精度を大幅に向上させることができる。
例として、2次元空間の2点A(x1,y1)とB(x2,y2)の間のユークリッド距離とマンハッタン距離を次のように計算する。
(4) Kの値を決定する。
選択したKの値が大きすぎるとアンダーフィット、小さすぎるとオーバーフィットになりやすく、Kの値を決定するためにクロスバリデーションが必要です。
KNNアルゴリズムの長所
1. シンプル、理解しやすい、実装しやすい、推定すべきパラメータがない、学習が不要。
2. 稀な事象の分類に適している。
3. 特に多階級問題(マルチモーダル、対象が複数のクラスラベルを持つ)に適している。kNNはSVMよりも性能が高い。
KNNアルゴリズムの欠点
KNNアルゴリズムによる分類の大きな欠点は、あるクラスのサンプル数が多く、他のクラスのサンプル数が少ない場合など、サンプルに偏りがある場合、新しいサンプルを入力すると、そのサンプルのK隣接のうち、下図のように容量の大きいクラスのサンプルが優位になる可能性があることです。このアルゴリズムでは、最近傍のサンプルしか数えません。あるクラスのサンプル数が多い場合、このクラスのサンプルはターゲットサンプルに近くないか、このクラスのサンプルはターゲットサンプルに非常に近いかのどちらかです。いずれにせよ、この数は実行結果に影響を与えません。重みの方法(そのサンプルとの距離が小さい隣人は大きな重みを持つ)を使うことで改善することができます。
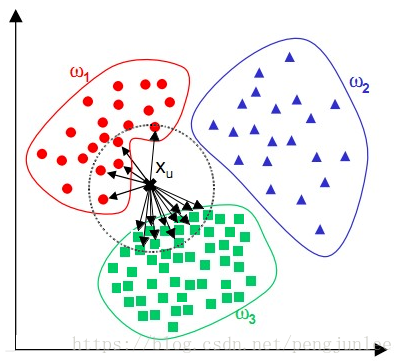
この方法のもう一つの欠点は計算量が多いことです。なぜなら、分類される各テキストについて、既知のサンプル全体との距離を計算し、そのK個の最近傍を見つける必要があるからです。
理解度が低く、決定木のようなルールを与えることができない。
KNNアルゴリズムの実装
KNNアルゴリズムを自分で実装するのはそれほど難しいことではなく、大きく分けて3つのステップがある。
距離の計算:分類されるサンプルが与えられたら、すでに分類された各サンプルからの距離を計算します。
近傍探索:分類したいサンプルに最も近いK個の分類済みサンプルを、分類したいサンプルの最近傍として丸で囲みます。
分類を行う:これらK個の最近接のうち、最も多く属するクラスに基づいて、分類されるサンプルがどのクラスに属するべきかを決定すること。
Pythonを用いてKNNアルゴリズムを実装する簡単な例を以下に示す。
import math
import csv
import operator
import random
import numpy as np
from sklearn.datasets import make_blobs
#Python version 3.6.5
# Create a sample dataset samples(number of samples) features(dimension of the feature vector) centers(number of categories)
def createDataSet(samples=100, features=2, centers=2):
return make_blobs(n_samples=samples, n_features=features, centers=centers, cluster_std=1.0, random_state=8)
# loadIrisDataset filename(path to dataset file)
def loadIrisDataset(filename):
with open(filename, 'rt') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
return dataset
# split dataset dataset(dataset to split) split(proportion of training set) trainingSet(training set) testSet(test set)
def splitDataSet(dataSet, split, trainingSet=[], testSet=[]):
for x in range(len(dataSet)):
if random.random() <= split:
trainingSet.append(dataSet[x])
else:
testSet.append(dataSet[x])
# Calculate the Euclidean distance
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x] - instance2[x]), 2)
return math.sqrt(distance)
# Pick the nearest K instances
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance) - 1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
# Get the nearest K instances with a larger percentage of categories
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
# Calculate the accuracy
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct / float(len(testSet))) * 100.0
def main():
# Use custom created dataset for classification
# x,y = createDataSet(features=2)
# dataSet= np.c_[x,y]
# Use the Iris flower dataset for classification
dataSet = loadIrisDataset(r'C:\DevTolls\eclipse-pureh2b\python\DeepLearning\KNN\iris_dataset.txt')
print(dataSet)
trainingSet = []
testSet = []
splitDataSet(dataSet, 0.75, trainingSet, testSet)
print('Train set:' + repr(len(trainingSet)))
print('Test set:' + repr(len(testSet)))
predictions = []
k = 7
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print('>predicted=' + repr(result) + ',actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%')
main()
尾花データファイル Baidu.com ダウンロードリンク: https://pan.baidu.com/s/10vI5p_QuM7esc-jkar2zdQ パスワード: 4und
KNNアルゴリズム応用例
単純な分類タスクにKNNアルゴリズムを使用する
scikit-learnにはいくつかのToy Datasetが組み込まれており、独自のデータセットを生成するためのAPIも多数用意されています。次に、scikit-learn の make_blobs 関数を使って、サンプルサイズ 200、分類サイズ 2 のデータセットを生成し、KNN アルゴリズムを使って分類することにします。
# Import the draw tool
import matplotlib.pyplot as plt
# Import the array tool
import numpy as np
# Import dataset generator
from sklearn.datasets import make_blobs
# import KNN classifier
from sklearn.neighbors import KNeighborsClassifier
# import dataset splitting tool
from sklearn.model_selection import train_test_split
# Generate a dataset with 200 samples and 2 classifications
data=make_blobs(n_samples=200, n_features=2,centers=2, cluster_std=1.0, random_state=8)
X,Y=data
# Visualize the generated dataset
# plt.scatter(X[:,0], X[:,1],s=80, c=Y, cmap=plt.cm.spring, edgecolors='k')
# plt.show()
clf = KNeighborsClassifier()
clf.fit(X,Y)
# Plot the graph
x_min,x_max=X[:,0].min()-1,X[:,0].max()+1
y_min,y_max=X[:,1].min()-1,X[:,1].max()+1
xx,yy=np.meshgrid(np.range(x_min,x_max,.02),np.range(y_min,y_max,.02))
z=clf.predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
plt.pcolormesh(xx,yy,z,cmap=plt.cm.Pastel1)
plt.scatter(X[:,0], X[:,1],s=80, c=Y, cmap=plt.cm.spring, edgecolors='k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:KNN")
# The data points to be classified are represented by five stars
plt.scatter(6.75,4.82,marker='*',c='red',s=200)
# Judgment on the classification of the data points to be classified
res = clf.predict([[6.75,4.82]])
plt.text(6.9,4.5,'Classification flag: '+str(res))
plt.show()
プログラムを実行すると、下図のような結果が得られます。
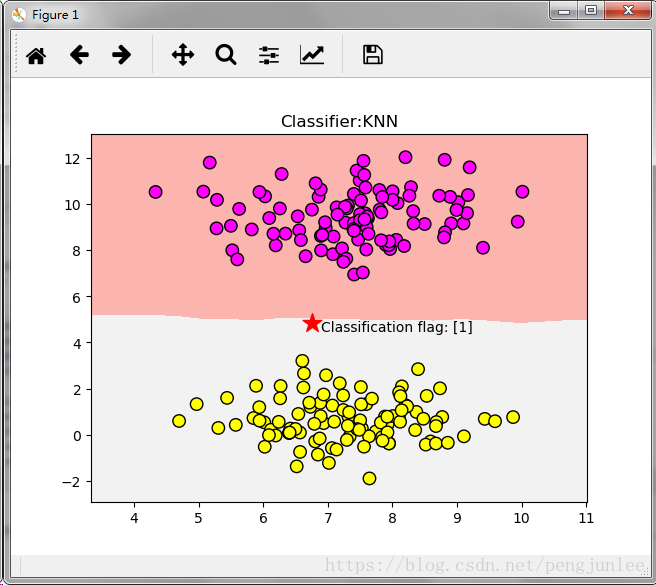
多変量解析タスクのためのKNNアルゴリズムの使用
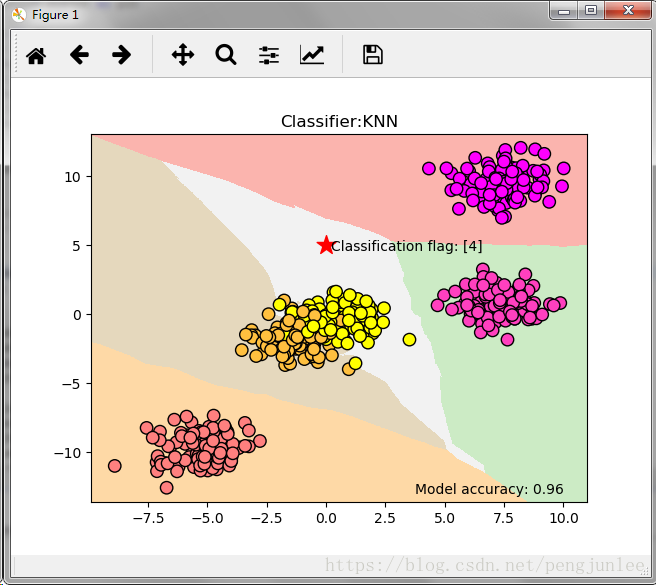
次に、scikit-learnのmake_blobs関数を使って、サンプルサイズ500、分類サイズ5のデータセットを生成し、KNNアルゴリズムを使って分類を行います。
# Import the drawing tool
import matplotlib.pyplot as plt
# Import the array tool
import numpy as np
# Import dataset generator
from sklearn.datasets import make_blobs
# import KNN classifier
from sklearn.neighbors import KNeighborsClassifier
# import dataset splitting tool
from sklearn.model_selection import train_test_split
# Generate a dataset with 500 samples and 5 classifications
data=make_blobs(n_samples=500, n_features=2,centers=5, cluster_std=1.0, random_state=8)
X,Y=data
# Visualize the generated dataset
# plt.scatter(X[:,0], X[:,1],s=80, c=Y, cmap=plt.cm.spring, edgecolors='k')
# plt.show()
clf = KNeighborsClassifier()
clf.fit(X,Y)
# Plot the graph
x_min,x_max=X[:,0].min()-1,X[:,0].max()+1
y_min,y_max=X[:,1].min()-1,X[:,1].max()+1
xx,yy=np.meshgrid(np.range(x_min,x_max,.02),np.range(y_min,y_max,.02))
z=clf.predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
plt.pcolormesh(xx,yy,z,cmap=plt.cm.Pastel1)
plt.scatter(X[:,0], X[:,1],s=80, c=Y, cmap=plt.cm.spring, edgecolors='k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:KNN")
# The data points to be classified are represented by five stars
plt.scatter(0,5,marker='*',c='red',s=200)
# Judgment on the classification of the data points to be classified
res = clf.predict([[0,5]])
plt.text(0.2,4.6,'Classification flag: '+str(res))
plt.text(3.75,-13,'Model accuracy: {:.2f}'.format(clf.score(X, Y))))
plt.show()
プログラムを実行すると、下図のような結果が得られます。
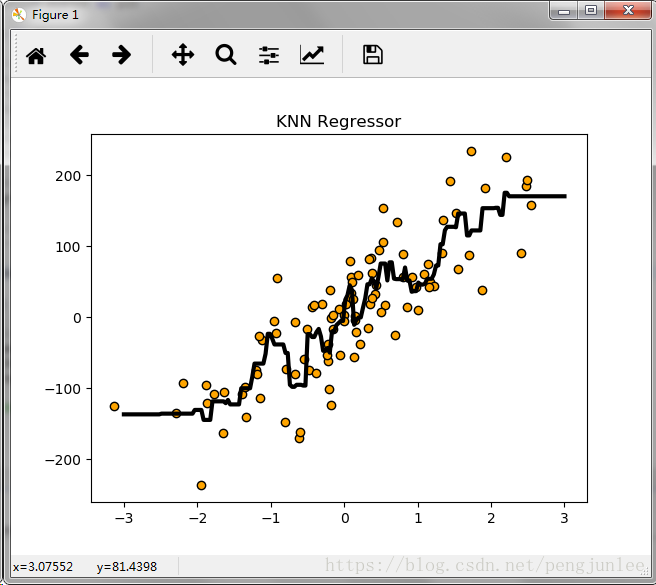
KNNアルゴリズムによる回帰分析
ここでは、scikit-learnのmake_regressionを使って、回帰分析におけるKNNアルゴリズムを実証するための実験用データセットを生成しています。
# Import the drawing tool
import matplotlib.pyplot as plt
# Import the array tool
import numpy as np
# Import KNN model for regression analysis
from sklearn.neighbors import KNeighborsRegressor
# Import the dataset splitting tool
from sklearn.model_selection import train_test_split
# import dataset generator
from sklearn.datasets.samples_generator import make_regression
from docutils.utils.math.math2html import LineWriter
# Generate a dataset with 200 samples and 2 categories
X,Y=make_regression(n_samples=100,n_features=1,n_informative=1,noise=50,random_state=8)
# Visualize the generated dataset
# plt.scatter(X,Y,s=80, c='orange', cmap=plt.cm.spring, edgecolors='k')
# plt.show()
reg = KNeighborsRegressor(n_neighbors=5)
reg.fit(X,Y)
# Visualize the prediction results with images
z = np.linspace(-3,3,200).reshape(-1,1)
plt.scatter(X,Y,c='orange',edgecolor='k')
plt.plot(z,reg.predict(z),c='k',Linewidth=3)
#
plt.title("KNN Regressor")
plt.show()
プログラムを実行すると、下図のような結果が得られます。
KNNアルゴリズムプロジェクト体験記 ---- ワインの分類
from sklearn.datasets.base import load_wine
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# load datasets from sklearn's datasets module load wine datasets
wineDataSet=load_wine()
print(wineDataSet)
print("Keys in wine dataset: \n{}".format(wineDataSet.keys()))
print("data profile: \n{}".format(wineDataSet['data'].shape))
print(wineDataSet['DESCR'])
# Split the dataset into a training dataset and a test dataset
X_train,X_test,y_train,y_test=train_test_split(wineDataSet['data'],wineDataSet['target'],random_state=0)
print("X_train shape:{}".format(X_train.shape))
print("X_test shape:{}".format(X_test.shape))
print("y_train shape:{}".format(y_train.shape))
print("y_test shape:{}".format(y_test.shape))
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(x_train,y_train)
print(knn)
# Evaluate the accuracy of the model
print('Test dataset score: {:.2f}'.format(knn.score(X_test,y_test)))
# Use the built model to make classification predictions for the new wine
X_new = np.array([[13.2,2.77,2.51,18.5,96.6,1.04,2.55,0.57,1.47,6.2,1.05,3.33,820]])
prediction = knn.predict(X_new)
print("Predict the classification of new wine as: {}".format(wineDataSet['target_names'][prediction]))
このプログラムを実行すると、次のような結果が出力されます。
X_train shape:(133, 13)
X_test shape:(45, 13)
y_train shape:(133,)
y_test shape:(45,)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
Test dataset score: 0.76
The predicted classification of the new wine is: ['class_2']
参考書籍:「徹底攻略Python機械学習」段暁斗著
関連
-
OSError: cannot identify image file 究極の解決策!
-
initAndListen で例外が発生しました。NonExistentPathです。データディレクトリ /data/db が見つかりませんでした。
-
サイズ2の軸1に対して、インデックス2が範囲外です。
-
mnist の next_batch コンストラクタを理解し、独自の next_batch イテレータを構築する。
-
wandb: ディープラーニングのための軽量な可視化ツールを始めるためのチュートリアル
-
tensorflow Solutionに一致するディストリビューションは見つかりませんでした。
-
TensorFlowのインストールエラー:tensorflowに一致するディストリビューションが見つかりません。
-
インストール cuda レポート エラー nvcc fatal : PATH でコンパイラ 'cl.exe' が見つからない
-
プログラム「'std::bad_alloc'のインスタンスを投げた後に呼び出されたterminate」を解く what(): std::bad_alloc Abo...
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
ハートビート・エフェクトのためのHTML+CSS
-
HTML ホテル フォームによるフィルタリング
-
HTML+cssのボックスモデル例(円、半円など)「border-radius」使いやすい
-
HTMLテーブルのテーブル分割とマージ(colspan, rowspan)
-
ランダム・ネームドロッパーを実装するためのhtmlサンプルコード
-
Html階層型ボックスシャドウ効果サンプルコード
-
QQの一時的なダイアログボックスをポップアップし、友人を追加せずにオンラインで話す効果を達成する方法
-
sublime / vscodeショートカットHTMLコード生成の実装
-
HTMLページを縮小した後にスクロールバーを表示するサンプルコード
-
html のリストボックス、テキストフィールド、ファイルフィールドのコード例