Intel Skylake / Kaby Lake CPUで、単純なハッシュテーブルの実装で謎の3倍速の速度低下が発生する理由とは?
質問
要するに
私は、キャッシュラインにぴったり合うバケット(いくつかの要素を含む)を持つ、シンプルな(マルチキーの)ハッシュテーブルを実装しました。 キャッシュラインのバケットに挿入するのは非常に簡単で、メイン ループの重要な部分です。
私は、同じ結果を生成し、同じ動作をするはずの3つのバージョンを実装しました。
謎
しかし、すべてのバージョンがまったく同じキャッシュライン アクセス パターンを持ち、同一のハッシュ テーブル データになるにもかかわらず、驚くほど大きな要因 3 によるパフォーマンスの乱高下を目の当たりにしました。
最適な実装
insert_ok
と比較して、およそ3倍の速度低下が発生します。
insert_bad
と同じです。
insert_alt
を私の CPU (i7-7700HQ) で実行しました。
一つのバリエーションinsert_badは、単純な修正で
insert_ok
これは、キャッシュライン内の不要な線形探索を追加して、書き込む位置 (これはすでに知っている) を見つけますが、この x3 のスローダウンには悩まされません。
まったく同じ実行ファイルに
insert_ok
と比べて1.6倍高速になりました。
insert_bad
&
insert_alt
を他の CPU (AMD 5950X (Zen 3)、Intel i7-11800H (Tiger Lake)) で使用した場合。
# see https://github.com/cr-marcstevens/hashtable_mystery
$ ./test.sh
model name : Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
==============================
CXX=g++ CXXFLAGS=-std=c++11 -O2 -march=native -falign-functions=64
tablesize: 117440512 elements: 67108864 loadfactor=0.571429
- test insert_ok : 11200ms
- test insert_bad: 3164ms
(outcome identical to insert_ok: true)
- test insert_alt: 3366ms
(outcome identical to insert_ok: true)
tablesize: 117440813 elements: 67108864 loadfactor=0.571427
- test insert_ok : 10840ms
- test insert_bad: 3301ms
(outcome identical to insert_ok: true)
- test insert_alt: 3579ms
(outcome identical to insert_ok: true)
コード
// insert element in hash_table
inline void insert_ok(uint64_t k)
{
// compute target bucket
uint64_t b = mod(k);
// bounded linear search for first non-full bucket
for (size_t c = 0; c < 1024; ++c)
{
bucket_t& B = table_ok[b];
// if bucket non-full then store element and return
if (B.size != bucket_size)
{
B.keys[B.size] = k;
B.values[B.size] = 1;
++B.size;
++table_count;
return;
}
// increase b w/ wrap around
if (++b == table_size)
b = 0;
}
}
// equivalent to insert_ok
// but uses a stupid linear search to store the element at the target position
inline void insert_bad(uint64_t k)
{
// compute target bucket
uint64_t b = mod(k);
// bounded linear search for first non-full bucket
for (size_t c = 0; c < 1024; ++c)
{
bucket_t& B = table_bad[b];
// if bucket non-full then store element and return
if (B.size != bucket_size)
{
for (size_t i = 0; i < bucket_size; ++i)
{
if (i == B.size)
{
B.keys[i] = k;
B.values[i] = 1;
++B.size;
++table_count;
return;
}
}
}
// increase b w/ wrap around
if (++b == table_size)
b = 0;
}
}
// instead of using bucket_t.size, empty elements are marked by special empty_key value
// a bucket is filled first to last, so bucket is full if last element key != empty_key
uint64_t empty_key = ~uint64_t(0);
inline void insert_alt(uint64_t k)
{
// compute target bucket
uint64_t b = mod(k);
// bounded linear search for first non-full bucket
for (size_t c = 0; c < 1024; ++c)
{
bucket_t& B = table_alt[b];
// if bucket non-full then store element and return
if (B.keys[bucket_size-1] == empty_key)
{
for (size_t i = 0; i < bucket_size; ++i)
{
if (B.keys[i] == empty_key)
{
B.keys[i] = k;
B.values[i] = 1;
++table_count;
return;
}
}
}
// increase b w/ wrap around
if (++b == table_size)
b = 0;
}
}
私の分析
ループ C++ にさまざまな変更を加えてみましたが、本質的に非常に単純なので、コンパイラーは同じアセンブリを生成します。 結果として得られるアセンブリから、要因 3 の損失が何を引き起こすかは、本当に明らかではありません。 Perf で測定してみましたが、意味のある違いを突き止めることはできないようです。
すべて比較的小さなループである 3 つのバージョンのアセンブリを比較すると、これらのバージョン間で要因 3 の損失を引き起こすかもしれない、近い何かを示唆するものは何もありません。
したがって、3 倍のスローダウンは、自動プリフェッチ、分岐予測、命令/ジャンプ アライメント、またはそれらの組み合わせによる奇妙な効果であると推測しています。
どなたか、ここで実際に作用している可能性のある効果について、より良い洞察や測定方法をお持ちではないでしょうか。
詳細
私は、この問題を実証する小さな動作する C++11 の例を作成しました。 コードは次の場所で入手できます。 https://github.com/cr-marcstevens/hashtable_mystery
また、異なるコンパイラーが異なるコードを生成するかもしれないので、私の CPU でこの問題を実証する私自身の静的バイナリも含まれています。 また、3 つのすべてのハッシュ テーブル バージョンのダンプされたアセンブリ コードも含まれています。
Perf イベント測定
たくさんのperfイベント測定値を紹介します。単語を含むものに焦点を当てました。
miss
と
stall
.
各イベントは2行になります。
-
最初の行は
insert_okであり、これは速度低下 -
に対応し、2 行目は
insert_altこれは追加のループと追加の作業を伴いますが、最終的にはより高速な
=== L1-dcache-load-misses ===
insert_ok : 171411476
insert_alt: 244244027
=== L1-dcache-loads ===
insert_ok : 775468123
insert_alt: 1038574743
=== L1-dcache-stores ===
insert_ok : 621353009
insert_alt: 554244145
=== L1-icache-load-misses ===
insert_ok : 69666
insert_alt: 259102
=== LLC-load-misses ===
insert_ok : 70519701
insert_alt: 71399242
=== LLC-loads ===
insert_ok : 130909270
insert_alt: 134776189
=== LLC-store-misses ===
insert_ok : 16782747
insert_alt: 16851787
=== LLC-stores ===
insert_ok : 17072141
insert_alt: 17534866
=== arith.divider_active ===
insert_ok : 26810
insert_alt: 26611
=== baclears.any ===
insert_ok : 2038060
insert_alt: 7648128
=== br_inst_retired.all_branches ===
insert_ok : 546479449
insert_alt: 938434022
=== br_inst_retired.all_branches_pebs ===
insert_ok : 546480454
insert_alt: 938412921
=== br_inst_retired.cond_ntaken ===
insert_ok : 237470651
insert_alt: 433439086
=== br_inst_retired.conditional ===
insert_ok : 477604946
insert_alt: 802468807
=== br_inst_retired.far_branch ===
insert_ok : 1058138
insert_alt: 1052510
=== br_inst_retired.near_call ===
insert_ok : 227076
insert_alt: 227074
=== br_inst_retired.near_return ===
insert_ok : 227072
insert_alt: 227070
=== br_inst_retired.near_taken ===
insert_ok : 307946256
insert_alt: 503926433
=== br_inst_retired.not_taken ===
insert_ok : 237458763
insert_alt: 433429466
=== br_misp_retired.all_branches ===
insert_ok : 36443541
insert_alt: 90626754
=== br_misp_retired.all_branches_pebs ===
insert_ok : 36441027
insert_alt: 90622375
=== br_misp_retired.conditional ===
insert_ok : 36454196
insert_alt: 90591031
=== br_misp_retired.near_call ===
insert_ok : 173
insert_alt: 169
=== br_misp_retired.near_taken ===
insert_ok : 19032467
insert_alt: 40361420
=== branch-instructions ===
insert_ok : 546476228
insert_alt: 938447476
=== branch-load-misses ===
insert_ok : 36441314
insert_alt: 90611299
=== branch-loads ===
insert_ok : 546472151
insert_alt: 938435143
=== branch-misses ===
insert_ok : 36436325
insert_alt: 90597372
=== bus-cycles ===
insert_ok : 222283508
insert_alt: 88243938
=== cache-misses ===
insert_ok : 257067753
insert_alt: 475091979
=== cache-references ===
insert_ok : 445465943
insert_alt: 590770464
=== cpu-clock ===
insert_ok : 10333.94 msec cpu-clock:u # 1.000 CPUs utilized
insert_alt: 4766.53 msec cpu-clock:u # 1.000 CPUs utilized
=== cpu-cycles ===
insert_ok : 25273361574
insert_alt: 11675804743
=== cpu_clk_thread_unhalted.one_thread_active ===
insert_ok : 223196489
insert_alt: 88616919
=== cpu_clk_thread_unhalted.ref_xclk ===
insert_ok : 222719013
insert_alt: 88467292
=== cpu_clk_unhalted.one_thread_active ===
insert_ok : 223380608
insert_alt: 88212476
=== cpu_clk_unhalted.ref_tsc ===
insert_ok : 32663820508
insert_alt: 12901195392
=== cpu_clk_unhalted.ref_xclk ===
insert_ok : 221957996
insert_alt: 88390991
insert_alt: === cpu_clk_unhalted.ring0_trans ===
insert_ok : 374
insert_alt: 373
=== cpu_clk_unhalted.thread ===
insert_ok : 25286801620
insert_alt: 11714137483
=== cycle_activity.cycles_l1d_miss ===
insert_ok : 16278956219
insert_alt: 7417877493
=== cycle_activity.cycles_l2_miss ===
insert_ok : 15607833569
insert_alt: 7054717199
=== cycle_activity.cycles_l3_miss ===
insert_ok : 12987627072
insert_alt: 6745771672
=== cycle_activity.cycles_mem_any ===
insert_ok : 23440206343
insert_alt: 9027220495
=== cycle_activity.stalls_l1d_miss ===
insert_ok : 16194872307
insert_alt: 4718344050
=== cycle_activity.stalls_l2_miss ===
insert_ok : 15350067722
insert_alt: 4578933898
=== cycle_activity.stalls_l3_miss ===
insert_ok : 12697354271
insert_alt: 4457980047
=== cycle_activity.stalls_mem_any ===
insert_ok : 20930005455
insert_alt: 4555461595
=== cycle_activity.stalls_total ===
insert_ok : 22243173394
insert_alt: 6561416461
=== dTLB-load-misses ===
insert_ok : 67817362
insert_alt: 63603879
=== dTLB-loads ===
insert_ok : 775467642
insert_alt: 1038562488
=== dTLB-store-misses ===
insert_ok : 8823481
insert_alt: 13050341
=== dTLB-stores ===
insert_ok : 621353007
insert_alt: 554244145
=== dsb2mite_switches.count ===
insert_ok : 93894397
insert_alt: 315793354
=== dsb2mite_switches.penalty_cycles ===
insert_ok : 9216240937
insert_alt: 206393788
=== dtlb_load_misses.miss_causes_a_walk ===
insert_ok : 177266866
insert_alt: 101439773
=== dtlb_load_misses.stlb_hit ===
insert_ok : 2994329
insert_alt: 35601646
=== dtlb_load_misses.walk_active ===
insert_ok : 4747616986
insert_alt: 3893609232
=== dtlb_load_misses.walk_completed ===
insert_ok : 67817832
insert_alt: 63591832
=== dtlb_load_misses.walk_completed_4k ===
insert_ok : 67817841
insert_alt: 63596148
=== dtlb_load_misses.walk_pending ===
insert_ok : 6495600072
insert_alt: 5987182579
=== dtlb_store_misses.miss_causes_a_walk ===
insert_ok : 89895924
insert_alt: 21841494
=== dtlb_store_misses.stlb_hit ===
insert_ok : 4940907
insert_alt: 21970231
=== dtlb_store_misses.walk_active ===
insert_ok : 1784142210
insert_alt: 903334856
=== dtlb_store_misses.walk_completed ===
insert_ok : 8845884
insert_alt: 13071262
=== dtlb_store_misses.walk_completed_4k ===
insert_ok : 8822993
insert_alt: 12936414
=== dtlb_store_misses.walk_pending ===
insert_ok : 1842905733
insert_alt: 933039119
=== exe_activity.1_ports_util ===
insert_ok : 991400575
insert_alt: 1433908710
=== exe_activity.2_ports_util ===
insert_ok : 782270731
insert_alt: 1314443071
=== exe_activity.3_ports_util ===
insert_ok : 556847358
insert_alt: 1158115803
=== exe_activity.4_ports_util ===
insert_ok : 427323800
insert_alt: 783571280
=== exe_activity.bound_on_stores ===
insert_ok : 299732094
insert_alt: 303475333
=== exe_activity.exe_bound_0_ports ===
insert_ok : 227569792
insert_alt: 348959512
=== frontend_retired.dsb_miss ===
insert_ok : 6771584
insert_alt: 93700643
=== frontend_retired.itlb_miss ===
insert_ok : 1115
insert_alt: 1689
=== frontend_retired.l1i_miss ===
insert_ok : 3639
insert_alt: 3857
=== frontend_retired.l2_miss ===
insert_ok : 2826
insert_alt: 2830
=== frontend_retired.latency_ge_1 ===
insert_ok : 9206268
insert_alt: 178345368
=== frontend_retired.latency_ge_128 ===
insert_ok : 2708
insert_alt: 2703
=== frontend_retired.latency_ge_16 ===
insert_ok : 403492
insert_alt: 820950
=== frontend_retired.latency_ge_2 ===
insert_ok : 4981263
insert_alt: 85781924
=== frontend_retired.latency_ge_256 ===
insert_ok : 802
insert_alt: 970
=== frontend_retired.latency_ge_2_bubbles_ge_1 ===
insert_ok : 56936702
insert_alt: 225712704
=== frontend_retired.latency_ge_2_bubbles_ge_2 ===
insert_ok : 10312026
insert_alt: 163227996
=== frontend_retired.latency_ge_2_bubbles_ge_3 ===
insert_ok : 7599252
insert_alt: 122841752
=== frontend_retired.latency_ge_32 ===
insert_ok : 3599
insert_alt: 3317
=== frontend_retired.latency_ge_4 ===
insert_ok : 2627373
insert_alt: 42287077
=== frontend_retired.latency_ge_512 ===
insert_ok : 418
insert_alt: 241
=== frontend_retired.latency_ge_64 ===
insert_ok : 2474
insert_alt: 2802
=== frontend_retired.latency_ge_8 ===
insert_ok : 528748
insert_alt: 951836
=== frontend_retired.stlb_miss ===
insert_ok : 769
insert_alt: 562
=== hw_interrupts.received ===
insert_ok : 9330
insert_alt: 3738
=== iTLB-load-misses ===
insert_ok : 456094
insert_alt: 90739
=== iTLB-loads ===
insert_ok : 949
insert_alt: 1031
=== icache_16b.ifdata_stall ===
insert_ok : 1145821
insert_alt: 862403
=== icache_64b.iftag_hit ===
insert_ok : 1378406022
insert_alt: 4459469241
=== icache_64b.iftag_miss ===
insert_ok : 61812
insert_alt: 57204
=== icache_64b.iftag_stall ===
insert_ok : 56551468
insert_alt: 82354039
=== idq.all_dsb_cycles_4_uops ===
insert_ok : 896374829
insert_alt: 1610100578
=== idq.all_dsb_cycles_any_uops ===
insert_ok : 1217878089
insert_alt: 2739912727
=== idq.all_mite_cycles_4_uops ===
insert_ok : 315979501
insert_alt: 480165021
=== idq.all_mite_cycles_any_uops ===
insert_ok : 1053703958
insert_alt: 2251382760
=== idq.dsb_cycles ===
insert_ok : 1218891711
insert_alt: 2744099964
=== idq.dsb_uops ===
insert_ok : 5828442701
insert_alt: 10445095004
=== idq.mite_cycles ===
insert_ok : 470409312
insert_alt: 1664892371
=== idq.mite_uops ===
insert_ok : 1407396065
insert_alt: 4515396737
=== idq.ms_cycles ===
insert_ok : 583601361
insert_alt: 587996351
=== idq.ms_dsb_cycles ===
insert_ok : 218346
insert_alt: 74155
=== idq.ms_mite_uops ===
insert_ok : 1266443204
insert_alt: 1277980465
=== idq.ms_switches ===
insert_ok : 149106449
insert_alt: 150392336
=== idq.ms_uops ===
insert_ok : 1266950097
insert_alt: 1277330690
=== idq_uops_not_delivered.core ===
insert_ok : 1871959581
insert_alt: 6531069387
=== idq_uops_not_delivered.cycles_0_uops_deliv.core ===
insert_ok : 289301660
insert_alt: 946930713
=== idq_uops_not_delivered.cycles_fe_was_ok ===
insert_ok : 24668869613
insert_alt: 9335642949
=== idq_uops_not_delivered.cycles_le_1_uop_deliv.core ===
insert_ok : 393750384
insert_alt: 1344106460
=== idq_uops_not_delivered.cycles_le_2_uop_deliv.core ===
insert_ok : 506090534
insert_alt: 1824690188
=== idq_uops_not_delivered.cycles_le_3_uop_deliv.core ===
insert_ok : 688462029
insert_alt: 2416339045
=== ild_stall.lcp ===
insert_ok : 380
insert_alt: 480
=== inst_retired.any ===
insert_ok : 4760842560
insert_alt: 5470438932
=== inst_retired.any_p ===
insert_ok : 4760919037
insert_alt: 5470404264
=== inst_retired.prec_dist ===
insert_ok : 4760801654
insert_alt: 5470649220
=== inst_retired.total_cycles_ps ===
insert_ok : 25175372339
insert_alt: 11718929626
=== instructions ===
insert_ok : 4760805219
insert_alt: 5470497783
=== int_misc.clear_resteer_cycles ===
insert_ok : 199623562
insert_alt: 671083279
=== int_misc.recovery_cycles ===
insert_ok : 314434729
insert_alt: 704406698
=== itlb.itlb_flush ===
insert_ok : 303
insert_alt: 248
=== itlb_misses.miss_causes_a_walk ===
insert_ok : 19537
insert_alt: 116729
=== itlb_misses.stlb_hit ===
insert_ok : 11323
insert_alt: 5557
=== itlb_misses.walk_active ===
insert_ok : 2809766
insert_alt: 4070194
=== itlb_misses.walk_completed ===
insert_ok : 24298
insert_alt: 45251
=== itlb_misses.walk_completed_4k ===
insert_ok : 34084
insert_alt: 29759
=== itlb_misses.walk_pending ===
insert_ok : 853764
insert_alt: 2817933
=== l1d.replacement ===
insert_ok : 171135334
insert_alt: 244967326
=== l1d_pend_miss.fb_full ===
insert_ok : 354631656
insert_alt: 382309583
=== l1d_pend_miss.pending ===
insert_ok : 16792436441
insert_alt: 22979721104
=== l1d_pend_miss.pending_cycles ===
insert_ok : 16377420892
insert_alt: 7349245429
=== l1d_pend_miss.pending_cycles_any ===
insert_ok : insert_alt: === l2_lines_in.all ===
insert_ok : 303009088
insert_alt: 411750486
=== l2_lines_out.non_silent ===
insert_ok : 157208112
insert_alt: 309484666
=== l2_lines_out.silent ===
insert_ok : 127379047
insert_alt: 84169481
=== l2_lines_out.useless_hwpf ===
insert_ok : 70374658
insert_alt: 144359127
=== l2_lines_out.useless_pref ===
insert_ok : 70747103
insert_alt: 142931540
=== l2_rqsts.all_code_rd ===
insert_ok : 71254
insert_alt: 242327
=== l2_rqsts.all_demand_data_rd ===
insert_ok : 137366274
insert_alt: 143507049
=== l2_rqsts.all_demand_miss ===
insert_ok : 150071420
insert_alt: 150820168
=== l2_rqsts.all_demand_references ===
insert_ok : 154854022
insert_alt: 160487082
=== l2_rqsts.all_pf ===
insert_ok : 170261458
insert_alt: 282476184
=== l2_rqsts.all_rfo ===
insert_ok : 17575896
insert_alt: 16938897
=== l2_rqsts.code_rd_hit ===
insert_ok : 79800
insert_alt: 381566
=== l2_rqsts.code_rd_miss ===
insert_ok : 25800
insert_alt: 33755
=== l2_rqsts.demand_data_rd_hit ===
insert_ok : 5191029
insert_alt: 9831101
=== l2_rqsts.demand_data_rd_miss ===
insert_ok : 132253891
insert_alt: 133965310
=== l2_rqsts.miss ===
insert_ok : 305347974
insert_alt: 414758839
=== l2_rqsts.pf_hit ===
insert_ok : 14639778
insert_alt: 19484420
=== l2_rqsts.pf_miss ===
insert_ok : 156092998
insert_alt: 263293430
=== l2_rqsts.references ===
insert_ok : 326549998
insert_alt: 443460029
=== l2_rqsts.rfo_hit ===
insert_ok : 11650
insert_alt: 21474
=== l2_rqsts.rfo_miss ===
insert_ok : 17544467
insert_alt: 16835137
=== l2_trans.l2_wb ===
insert_ok : 157044674
insert_alt: 308107712
=== ld_blocks.no_sr ===
insert_ok : 14
insert_alt: 13
=== ld_blocks.store_forward ===
insert_ok : 158
insert_alt: 128
=== ld_blocks_partial.address_alias ===
insert_ok : 5155853
insert_alt: 17867414
=== load_hit_pre.sw_pf ===
insert_ok : 10840795
insert_alt: 11072297
=== longest_lat_cache.miss ===
insert_ok : 257061118
insert_alt: 471152073
=== longest_lat_cache.reference ===
insert_ok : 445701577
insert_alt: 583870610
=== machine_clears.count ===
insert_ok : 3926377
insert_alt: 4280080
=== machine_clears.memory_ordering ===
insert_ok : 97177
insert_alt: 25407
=== machine_clears.smc ===
insert_ok : 138579
insert_alt: 305423
=== mem-stores ===
insert_ok : 621353009
insert_alt: 554244143
=== mem_inst_retired.all_loads ===
insert_ok : 775473590
insert_alt: 1038559807
=== mem_inst_retired.all_stores ===
insert_ok : 621353013
insert_alt: 554244145
=== mem_inst_retired.lock_loads ===
insert_ok : 85
insert_alt: 85
=== mem_inst_retired.split_loads ===
insert_ok : 171
insert_alt: 174
=== mem_inst_retired.split_stores ===
insert_ok : 53
insert_alt: 49
=== mem_inst_retired.stlb_miss_loads ===
insert_ok : 68308539
insert_alt: 18088047
=== mem_inst_retired.stlb_miss_stores ===
insert_ok : 264054
insert_alt: 819551
=== mem_load_l3_hit_retired.xsnp_none ===
insert_ok : 231116
insert_alt: 175217
=== mem_load_retired.fb_hit ===
insert_ok : 6510722
insert_alt: 95952490
=== mem_load_retired.l1_hit ===
insert_ok : 698271530
insert_alt: 920982402
=== mem_load_retired.l1_miss ===
insert_ok : 69525335
insert_alt: 20089897
=== mem_load_retired.l2_hit ===
insert_ok : 1451905
insert_alt: 773356
=== mem_load_retired.l2_miss ===
insert_ok : 68085186
insert_alt: 19474303
=== mem_load_retired.l3_hit ===
insert_ok : 222829
insert_alt: 155958
=== mem_load_retired.l3_miss ===
insert_ok : 67879593
insert_alt: 19244746
=== memory_disambiguation.history_reset ===
insert_ok : 97621
insert_alt: 25831
=== minor-faults ===
insert_ok : 1048716
insert_alt: 1048718
=== node-loads ===
insert_ok : 71473780
insert_alt: 71377840
=== node-stores ===
insert_ok : 16781161
insert_alt: 16842666
=== offcore_requests.all_data_rd ===
insert_ok : 284186682
insert_alt: 392110677
=== offcore_requests.all_requests ===
insert_ok : 530876505
insert_alt: 777784382
=== offcore_requests.demand_code_rd ===
insert_ok : 34252
insert_alt: 45896
=== offcore_requests.demand_data_rd ===
insert_ok : 133468710
insert_alt: 134288893
=== offcore_requests.demand_rfo ===
insert_ok : 17612516
insert_alt: 17062276
=== offcore_requests.l3_miss_demand_data_rd ===
insert_ok : 71616594
insert_alt: 82917520
=== offcore_requests_buffer.sq_full ===
insert_ok : 2001445
insert_alt: 3113287
=== offcore_requests_outstanding.all_data_rd ===
insert_ok : 35577129549
insert_alt: 78698308135
=== offcore_requests_outstanding.cycles_with_data_rd ===
insert_ok : 17518017620
insert_alt: 7940272202
=== offcore_requests_outstanding.demand_code_rd ===
insert_ok : 11085819
insert_alt: 9390881
=== offcore_requests_outstanding.demand_data_rd ===
insert_ok : 15902243707
insert_alt: 21097348926
=== offcore_requests_outstanding.demand_data_rd_ge_6 ===
insert_ok : 1225437
insert_alt: 317436422
=== offcore_requests_outstanding.demand_rfo ===
insert_ok : 1074492442
insert_alt: 1157902315
=== offcore_response.demand_code_rd.any_response ===
insert_ok : 53675
insert_alt: 69683
=== offcore_response.demand_code_rd.l3_hit.any_snoop ===
insert_ok : 19407
insert_alt: 29704
=== offcore_response.demand_code_rd.l3_hit.snoop_none ===
insert_ok : 12675
insert_alt: 11951
=== offcore_response.demand_code_rd.l3_miss.any_snoop ===
insert_ok : 34617
insert_alt: 40868
=== offcore_response.demand_code_rd.l3_miss.spl_hit ===
insert_ok : 0
insert_alt: 753
=== offcore_response.demand_data_rd.any_response ===
insert_ok : 131014821
insert_alt: 134813171
=== offcore_response.demand_data_rd.l3_hit.any_snoop ===
insert_ok : 59713328
insert_alt: 50254543
=== offcore_response.demand_data_rd.l3_miss.any_snoop ===
insert_ok : 71431585
insert_alt: 83916030
=== offcore_response.demand_data_rd.l3_miss.spl_hit ===
insert_ok : 244837
insert_alt: 6441992
=== offcore_response.demand_rfo.any_response ===
insert_ok : 16876557
insert_alt: 17619450
=== offcore_response.demand_rfo.l3_hit.any_snoop ===
insert_ok : 907432
insert_alt: 45127
=== offcore_response.demand_rfo.l3_hit.snoop_none ===
insert_ok : 787567
insert_alt: 794579
=== offcore_response.demand_rfo.l3_hit_e.any_snoop ===
insert_ok : 496938
insert_alt: 173658
=== offcore_response.demand_rfo.l3_hit_e.snoop_none ===
insert_ok : 779919
insert_alt: 50575
=== offcore_response.demand_rfo.l3_hit_m.any_snoop ===
insert_ok : 128627
insert_alt: 25483
=== offcore_response.demand_rfo.l3_miss.any_snoop ===
insert_ok : 16782186
insert_alt: 16847970
=== offcore_response.demand_rfo.l3_miss.snoop_none ===
insert_ok : 16782647
insert_alt: 16850104
=== offcore_response.demand_rfo.l3_miss.spl_hit ===
insert_ok : 0
insert_alt: 1364
=== offcore_response.other.any_response ===
insert_ok : 137231000
insert_alt: 189526494
=== offcore_response.other.l3_hit.any_snoop ===
insert_ok : 62695084
insert_alt: 51005882
=== offcore_response.other.l3_hit.snoop_none ===
insert_ok : 62975018
insert_alt: 50217349
=== offcore_response.other.l3_hit_e.any_snoop ===
insert_ok : 62770215
insert_alt: 50691817
=== offcore_response.other.l3_hit_e.snoop_none ===
insert_ok : 62602591
insert_alt: 50642954
=== offcore_response.other.l3_miss.any_snoop ===
insert_ok : 74247236
insert_alt: 139212975
=== offcore_response.other.l3_miss.snoop_none ===
insert_ok : 75911794
insert_alt: 141076520
=== other_assists.any ===
insert_ok : 1
insert_alt: 3
=== page-faults ===
insert_ok : 1048719
insert_alt: 1048718
=== partial_rat_stalls.scoreboard ===
insert_ok : 530950991
insert_alt: 539869553
=== ref-cycles ===
insert_ok : 32546980212
insert_alt: 12930921138
=== resource_stalls.any ===
insert_ok : 21923576648
insert_alt: 5205690082
=== resource_stalls.sb ===
insert_ok : 397908667
insert_alt: 402738367
=== rs_events.empty_cycles ===
insert_ok : 1173721723
insert_alt: 1880165720
=== rs_events.empty_end ===
insert_ok : 87752182
insert_alt: 160792701
=== sw_prefetch_access.t0 ===
insert_ok : 20835202
insert_alt: 20599176
=== task-clock ===
insert_ok : 10416.86 msec task-clock:u # 1.000 CPUs utilized
insert_alt: 4767.78 msec task-clock:u # 1.000 CPUs utilized
=== tlb_flush.stlb_any ===
insert_ok : 1835393
insert_alt: 1835396
=== topdown-fetch-bubbles ===
insert_ok : 1904143421
insert_alt: 6543146396
=== topdown-slots-issued ===
insert_ok : 7538371393
insert_alt: 14449966516
=== topdown-slots-retired ===
insert_ok : 5267325162
insert_alt: 5849706597
=== uops_dispatched_port.port_0 ===
insert_ok : 1252121297
insert_alt: 1489605354
=== uops_dispatched_port.port_1 ===
insert_ok : 1379316967
insert_alt: 1585037107
=== uops_dispatched_port.port_2 ===
insert_ok : 1140861153
insert_alt: 1785053149
=== uops_dispatched_port.port_3 ===
insert_ok : 1187151423
insert_alt: 1828975838
=== uops_dispatched_port.port_4 ===
insert_ok : 1577171758
insert_alt: 1557761857
=== uops_dispatched_port.port_5 ===
insert_ok : 1341370655
insert_alt: 1653599117
=== uops_dispatched_port.port_6 ===
insert_ok : 1856735970
insert_alt: 4387464794
=== uops_dispatched_port.port_7 ===
insert_ok : 508351498
insert_alt: 603583315
=== uops_executed.core ===
insert_ok : 7225522677
insert_alt: 12716368190
=== uops_executed.core_cycles_ge_1 ===
insert_ok : 3041586797
insert_alt: 5168421550
=== uops_executed.core_cycles_ge_2 ===
insert_ok : 2017794537
insert_alt: 3653591208
=== uops_executed.core_cycles_ge_3 ===
insert_ok : 1225785335
insert_alt: 2316014066
=== uops_executed.core_cycles_ge_4 ===
insert_ok : 657121809
insert_alt: 1143390519
=== uops_executed.core_cycles_none ===
insert_ok : 22191507320
insert_alt: 6563722081
=== uops_executed.cycles_ge_1_uop_exec ===
insert_ok : 3040999757
insert_alt: 5175668459
=== uops_executed.cycles_ge_2_uops_exec ===
insert_ok : 2015520940
insert_alt: 3659989196
=== uops_executed.cycles_ge_3_uops_exec ===
insert_ok : 1224025952
insert_alt: 2319025110
=== uops_executed.cycles_ge_4_uops_exec ===
insert_ok : 657094113
insert_alt: 1141381027
=== uops_executed.stall_cycles ===
insert_ok : 22350754164
insert_alt: 6590978048
=== uops_executed.thread ===
insert_ok : 7214521925
insert_alt: 12697219901
=== uops_executed.x87 ===
insert_ok : 2992
insert_alt: 3337
=== uops_issued.any ===
insert_ok : 7531354736
insert_alt: 14462113169
=== uops_issued.slow_lea ===
insert_ok : 2136241
insert_alt: 2115308
=== uops_issued.stall_cycles ===
insert_ok : 23244177475
insert_alt: 7416801878
=== uops_retired.macro_fused ===
insert_ok : 410461916
insert_alt: 735050350
=== uops_retired.retire_slots ===
insert_ok : 5265023980
insert_alt: 5855259326
=== uops_retired.stall_cycles ===
insert_ok : 23513958928
insert_alt: 9630258867
=== uops_retired.total_cycles ===
insert_ok : 25266688635
insert_alt: 11703285605
背景
私は C++11 で暗号解読攻撃を実装しており、2 つの大きなリスト (両方ともオンザフライで生成) の間の多くの衝突を見つける必要があります。 したがって、攻撃の重要な部分は、単に 2 つの重要なループで構成されています。
- まず、1 つのリストでハッシュ テーブルを生成します。
- 次に、ハッシュテーブルに対してもう一方のリストをマッチングします。
このようにハッシュテーブルの操作はパフォーマンス上重要であり、3倍遅くなるということは、攻撃が3倍遅くなるということです。
設計について。 メモリ使用量を最小限にすることに加えて、私は、典型的なハッシュ テーブル操作が単一のキャッシュライン上で動作するようにしようとしています。これは、特にすべての CPU コアで攻撃を実行する場合、全体的な攻撃パフォーマンスを向上させると予想しているからです。
どのように解決するのですか?
概要
TLDR は、TLB のすべてのレベルを欠き (したがってページ ウォークを必要とし)、かつ
住所不明
のストアは並列実行できない、つまり、ロードはシリアライズされ
メモリレベル並列化
(MLP) 係数の上限は 1 です。事実上、ストア
フェンス
と同じように
lfence
と同じです。
挿入関数の低速バージョンはこのシナリオになり、他の 2 つはなりません(ストア アドレスは既知です)。大きな領域サイズでは、メモリ アクセス パターンが支配的で、性能は MLP にほぼ直接関係します。高速バージョンでは、ロード ミスをオーバーラップさせて約 3 の MLP を得ることができ、結果として 3 倍のスピードアップになります (以下で説明する狭い再現ケースは、より多く示すことができます。 10x Skylake では 10 倍以上の差を示すことができます)。
根本的な理由は、Skylake プロセッサが ページ テーブル コヒーレンス
これは、仕様では要求されていませんが、ソフトウェアのバグを回避することができます。詳細
ご興味のある方のために、詳細を掘り下げてご紹介します。
私の Skylake i7-6700HQ マシンでこの問題をすぐに再現できました。余計な部分を取り除くことで、オリジナルのハッシュ挿入ベンチマークをこの単純なループに縮小でき、同じ問題が発生します。
tlb_fencing:
xor eax, eax ; the index pointer
mov r9 , [rsi + region.start]
mov r8 , [rsi + region.size]
sub r8 , 200 ; pointer to end of region (plus a bit of buffer)
mov r10, [rsi + region.size]
sub r10, 1 ; mask
mov rsi, r9 ; region start
.top:
mov rcx, rax
and rcx, r10 ; remap the index into the region via masking
add rcx, r9 ; make pointer p into the region
mov rdx, [rcx] ; load 8 bytes at p, always zero
xor rcx, rcx ; no-op
mov DWORD [rsi + rdx + 160], 0 ; store zero at p + 160
add rax, (64 * 67) ; advance a prime number of cache lines slightly larger than a page
dec rdi
jnz .top
ret
とほぼ同等であり
B.size
アクセス (ロード) と
B.values[B.size] = 1
の最内周のループのアクセス(ストア)と
insert_ok
4
.
ループに集中し、ストライドロードと固定ストアを行います。次に、ロード位置をページのサイズ (4 KiB) よりも少し前に移動します。重要なのは、ストアアドレス
に依存します。
に依存します。アドレス指定式として
[rsi + rdx + 160]
には
rdx
で、ロードされた値を保持するレジスタである
1
. ループの中でアドレスの構成要素はどれも変化しないので、ストアは常に同じアドレスに発生します(したがって、常にL1キャッシュにヒットすることが期待されます)。
元のハッシュの例では、さらに多くの作業を行い、ランダムにメモリにアクセスし、ロードと同じ行にストアを行いました。しかし、この単純なループは同じ効果をキャプチャします。
我々はまた、ベンチマークの他の1つのバージョンを使用します。
xor rcx, rcx
がロードとストアの間の
xor rdx, rdx
. これは
が壊れる
という、ロードアドレスとストアアドレスの間の依存関係を壊します。
直感的には、この依存関係にはあまり期待していません。ここでのストアは fire-and-forgetです。 で、保存された場所から再び読み取ることはありません (少なくとも多くの反復処理では) ので、運ばれた依存関係の連鎖の一部ではありません。小規模な領域では、ボトルネックは ~8 uops を噛み砕くことであり、大規模な領域では、すべてのキャッシュ ミスを処理する時間が支配的であると予想されます。
以下の 3 つのバリエーションで、4 KiB から 256 MiB までの領域サイズに対するサイクルでのパフォーマンスを確認してください。
2M dep:
上記のループ(ストアアドレスがロードに依存する)で 2MiBの巨大ページ .
4Kデポです。 標準的な4KiBページで上に示したループ(ストアアドレスがロードに依存する)。
4K indep:
上記のループの変形で、ただし
xor rdx, rdx
に置き換えて
xor rcx, rcx
に置き換えることで、ロード結果とストアアドレスの間の依存関係を断ち切り、4KiBページを使用します。
その結果
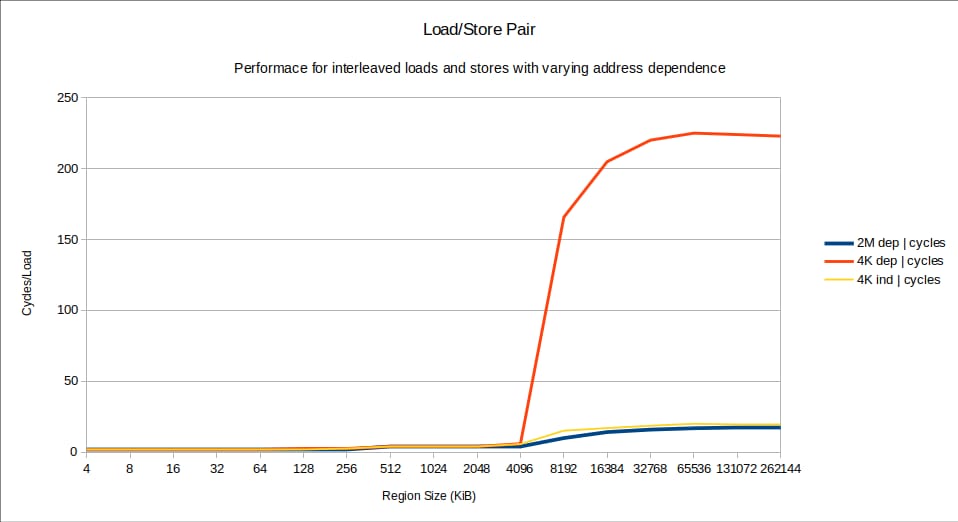
すべての変種の性能は、小さな領域サイズでは基本的に同じです。256 KiB まではすべて 2 サイクル/繰り返しで、ループ内の 8 uops と CPU 幅が 4 uops/ サイクルであること . L2 キャッシュ ヒットの待ち時間は 12 サイクルですが、2 サイクルごとに 1 回完了しているため、平均して 6 回の L1 ミスの待ち時間をオーバーラップさせて達成する必要があります。
256 KiB と 4096 KiB の間では、L3 ヒットが起こり始めるため、パフォーマンスが多少低下しますが、パフォーマンスは良好で、MLP も高いです。
8196 KiB では、以下のようにパフォーマンスが極端に低下します。 のみです。 で壊滅的に低下します。 4Kディスプレイ の場合、150サイクルを越えて、最終的には220サイクル程度で安定する。よりも多いのです。 10倍 2 .
すでにいくつかの重要な観察ができます。
- 両方の 2Mデップ と 4K indep のケースは高速です:だからこれは ただ ストア間の依存関係だけでなく、ページング動作についても同様です。
- は 2M デップ のケースが最も速いので、メモリにミスしても依存関係が何か根本的な問題を引き起こさないことがわかります。
- の性能は、遅い 4K デップ のケースは、私のマシンのメモリ レイテンシと怪しく似ています。
上記でMLPについて触れ、観測されたパフォーマンスからMLPの下限を計算しましたが、Intel CPUでは、2つのパフォーマンスカウンターを使用してMLPを直接測定することができます。
<ブロッククオート
l1d_pend_miss.pendingL1D ミス未処理の期間、つまりデマンド リードによって必要とされるフィル バッファー (FB) 未処理の各サイクル数をカウントします。
l1d_pend_miss.pending_cycles
L1Dロードミスが発生したサイクル
最初のカウンターは、毎サイクル、L1Dからの未処理のリクエストの数を数えます。したがって、3 つのミスが進行中の場合、このカウンターはサイクルごとに 3 ずつ増加します。2 番目のカウンターは、少なくとも毎サイクル 1 つずつ増加します。
1
が発生するたびに1ずつ増加します。これは、毎サイクル1で飽和する最初のカウンターのバージョンと見ることができます。比率は
l1d_pend_miss.pending / l1d_pend_miss.pending_cycles
は,ミスが発生している間の平均的なMLP係数です.
3
.
について、そのMLP比をプロットしてみましょう。 dep と インデック バージョンの 4K ベンチマークです。
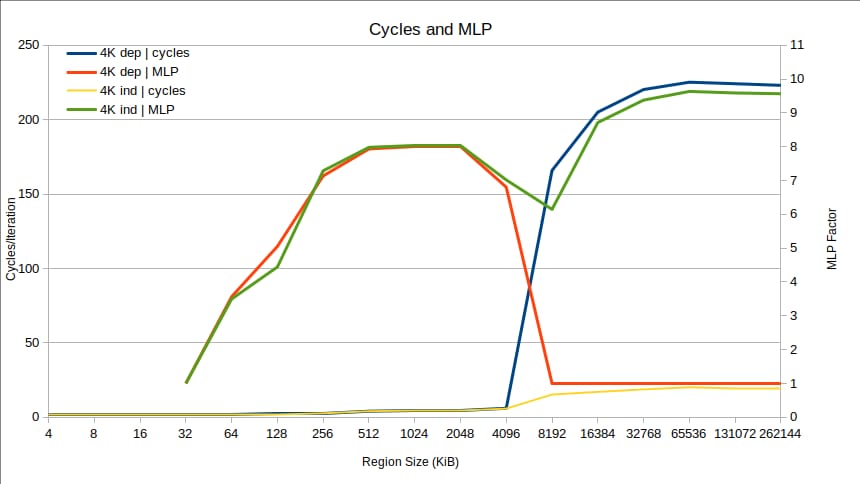
問題は非常に明確になります。4096 KiB の領域までは、パフォーマンスは同じで、MLP は高いです (非常に小さな領域サイズでは、L1D ミスがまったくないため、MLP は "no"となります)。8192KiBで突然、依存型の場合のMLPは1に低下してそのままになりますが、独立型の場合のMLPはほぼ10まで上昇します。これだけで、基本的に 10 倍のパフォーマンスの違いが説明できます。依存するケースでは、負荷をまったくオーバーラップさせることができないのです。
なぜでしょうか。問題は TLB ミスであるように思われます。8192 KiB で何が起こったかというと、ベンチマークが TLB を欠落させ始めたのです。具体的には、各 Skylake コアには 1536 個の STLB (第 2 レベル TLB) エントリがあり、1536 × 4096 = 6 MiB の 4K ページをカバーすることができます。そのため、領域サイズが4MiBと8MiBの間で、TLBミスが1回になります。
dtlb_load_misses.walk_completed
に基づいて、TLB ミスが 1 回になり、このほとんど完璧すぎる偽物のプロットが作成されます。
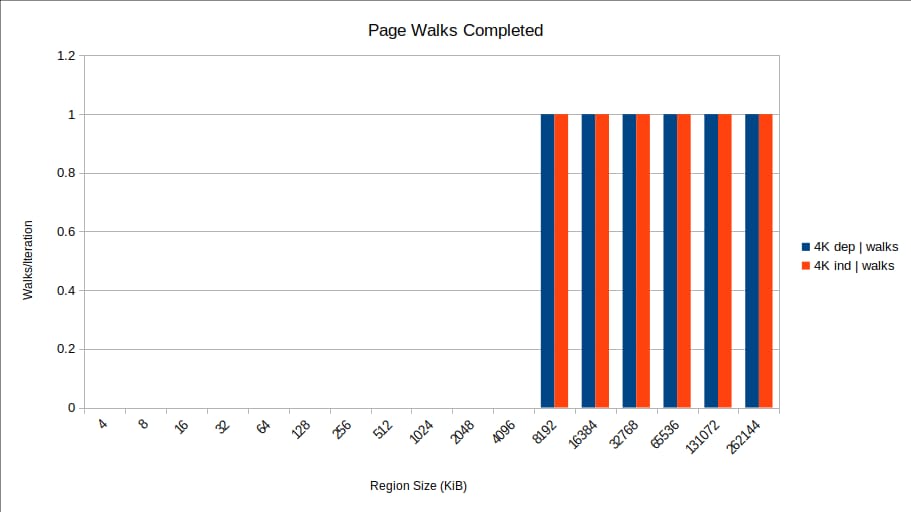
つまり、アドレス未知のストアがストアバッファにある場合、STLB ミスを取るロードは重なることができず、1 回に 1 回の処理となります。つまり、1回のアクセスごとにメモリのレイテンシが発生するわけです。2MB ページが 3 GiB のメモリをカバーできるため、これらの領域サイズでは STLB ミス/ページウォークは発生しません。
なぜ
この動作は、Skylake およびその他の初期の Intel プロセッサーに実装されている ページ テーブル コヒーレンスを実装していることに起因しているようです。
を実装していることに起因しているようです。ページ テーブル コヒーレンスとは、アドレス マッピングを変更するストアがある場合 (たとえば)、リマッピングの影響を受ける仮想アドレスを使用する後続のロードは、明示的なフラッシュを行わずに新しいマッピングを一貫して参照することを意味します。この洞察は、Henry Wong によるものです。 ページ ウォーク コヒーレンスに関する優れた記事 によると、これを行うために、ページウォークは、競合する、または アドレス不明なストア が発生した場合、ページウォークは終了します。
<ブロッククオート予期せぬことに、Intel Core 2 および新しいシステムは、ページ テーブルの変更がないにもかかわらず、ページウォーク コヒーレンス ミスペキュレーションが発生したかのような動作をしました。これらのシステムにはメモリ依存の予測があるため、ロードはストアよりもはるかに早く投機的に実行され、データ依存の連鎖を断ち切ったはずです。
正確に言うと、間違って検出された誤投機の原因は、早期に実行された負荷であることが判明しました。ページウォークを既知の古いストア アドレス (ストア キュー内?) と比較し、競合または未知のアドレスを持つ古いストアがある場合、コヒーレンス違反と仮定することによってです。
したがって、これらのストアは、ページ テーブルを変更しないという点でまったく無実であるにもかかわらず、ページ テーブル コヒーレンス メカニズムに巻き込まれるのです。イベントを見ることで、この理論のさらなる証拠を見つけることができます。
dtlb_load_misses.miss_causes_a_walk
. とは異なり
walk_completed
イベントとは異なり、これは
が開始された
が開始されたすべてのウォークをカウントします。これは次のようになります (繰り返しますが、2M はページ ウォークをまったく開始しないため、表示されません)。
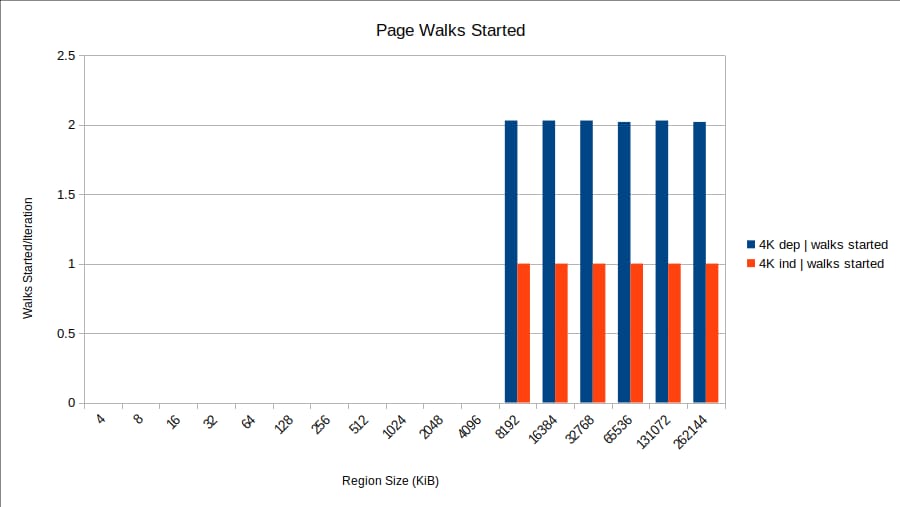
あれっ!?4K依存で表示されるのは に が表示され、そのうちの 1 つだけが正常に完了します。これは、すべてのロードに対して 2 回のウォークです。これは、反復処理 N+1 のロードに対してページ ウォークが開始されるが、反復処理 N からのストアがストア バッファにまだ残っていることを発見するという理論に一致します (反復処理 N のロードがそのアドレスを提供し、それがまだ進行中であるためです)。アドレスが不明なので、Henryが説明するようにページウォークはキャンセルされる。さらにページウォークは、ストアのアドレスが解決されるまで延期されます。ロード N+1 のページ ウォークはロード N の結果を待つ必要があるため、結果的にすべてのロードがシリアライズされた方法で完了します。
なぜ "bad" と "alt" メソッドは高速なのでしょうか。
最後に、1つだけ残っている謎があります。上記は、元のハッシュ アクセスが遅い理由を説明していますが、他の 2 つが速い理由は説明していません。重要なのは、高速なメソッドの両方がアドレス不明ストアを持たないことで、ロードによるデータ依存性が投機的制御依存性に置き換えられているからです。
の内部ループを見てみましょう。
insert_bad
のアプローチの内部ループを見てみましょう。
for (size_t i = 0; i < bucket_size; ++i)
{
if (i == B.size)
{
B.keys[i] = k;
B.values[i] = 1;
++B.size;
++table_count;
return;
}
}
ストアはループインデックス
i
. とは異なり
insert_ok
の場合とは異なり、インデックス
[B.size]
はストアから来る。
i
は単にレジスタの中の計算された値です。さて
i
は
関連
をロードされた値
B.size
であるため、その最終値は
と等しくなります。
になりますが、これは推測されるコントロールの依存関係である比較を介して確立されます。これはページウォークキャンセルの問題を引き起こしません。このシナリオには多くの予測ミスがありますが (ループの出口が予測できないため)、大きな領域の場合、これらは実際にはあまり有害ではありません。なぜなら、悪いパスは通常良いパスと同じメモリ アクセスを行い (具体的には、次に挿入する値は常に同じです)、メモリ アクセス動作が支配的だからです。
の場合にも同じことが言えます。
alt
の場合:書き込むインデックスは、計算された値
i
を使って値をロードし、それが特別なマーカー値であるかどうかをチェックし、そしてその場所に書き込むためにインデックス
i
. ここでも、遅延ストア アドレスはなく、ただ素早く計算されたレジスタ値と推測される制御依存性があるだけです。
他のハードウェアについてはどうでしょう
質問の著者と同様に、私は Skylake で効果を見つけましたが、Haswell でも同じ挙動を確認しました。Ice Lake では、私はそれを再現することができません。 dep と インデック はほぼ同じ性能です。
しかし、ユーザーノア は Tigerlake 上で再現できたと報告しています。 を使用して、特定のアラインメントでオリジナルのベンチマークを再現できたと報告しています。最もありそうな原因は、TGL がこのページウォーク動作の対象ではなく、一部のアラインメントでメモリの曖昧さ回避予測器が衝突して、非常によく似た効果を引き起こしていることだと思います。
自分で実行する
上で説明したベンチマークは、自分で実行することができます。これは uarch-bench . Linux(またはWSL、ただしパフォーマンスカウンターは利用できません)では、次のコマンドを実行して結果を収集することができます。
for s in 2M-dep 4K-dep 4K-indep; do ./uarch-bench --timer=perf --test-name="studies/memory/tlb-fencing/*$s" --extra-events=dtlb_load_misses.miss_causes_a_walk#walk_s,dtlb_load_misses.walk_completed#walk_c,l1d_pend_miss.pending#l1d_p,l1d_pend_miss.pending_cycles#l1d_pc; done
システムによっては、(ハイパースレッディングを有効にしている場合)利用可能な無料のパフォーマンス カウンターが十分でない場合があるので、毎回異なるカウンターのセットを使用して 2 回実行することができます。
1
この場合
rdx
は常にゼロなので (領域は完全にゼロでいっぱいです)、ストア アドレスは、このレジスタがアドレス指定式に含まれていない場合と同じになりますが、CPU はそのことを知りません (笑)。
2 ここでは 2Mデップ の場合よりも良いパフォーマンスを示し始めます。 4K indep の場合も、その差はわずかですが、4K indep の場合よりも良いパフォーマンスを示し始めています。
3
ミスしている間」という部分に注意してください。
l1d_pend_miss.pending / cycles
としてMLPを計算することもでき、これはミスが未解決であるかどうかに関係なく、一定期間の平均MLPとなります。それぞれ独自の方法で有用ですが、このようにミスが常に未解決のケースでは、ほぼ同じ値が得られます。
4
この例と元の例には多くの違いがあります。元のループでは繰り返しごとに変化するロード位置の近くに保存していましたが、ここでは1つの固定された場所に保存しています。1ではなく0を保存しています。をチェックしません。
B.size
が大きすぎるかどうかをチェックしません。このテストでは、ロードされる値は常に 0 です。バケツが一杯になったときのための探索ループはありません。アドレスにランダムな値をロードせず、単にリニアなストライドを行うだけです。しかし、これらは重要ではありません。どちらの場合も同じ効果が発生し、この単純なケースに到達するまで、複雑さを取り除くことで元の例を段階的に修正することができます。
関連
-
[解決済み】C++エラー。アーキテクチャ x86_64 に対して未定義のシンボル
-
[解決済み】構造体のベクター初期化について
-
[解決済み] [Solved] Error C1083: Cannot open include file: 'stdafx.h'
-
[解決済み] error: 'ostream' does not name a type.
-
[解決済み】C++コンパイルタイムエラー:数値定数の前に期待される識別子
-
[解決済み】致命的なエラー LNK1169: ゲームプログラミングで1つ以上の多重定義されたシンボルが発見された
-
[解決済み】「corrupted size vs. prev_size」glibc エラーを理解する。
-
[解決済み】CMakeエラー at CMakeLists.txt:30 (project)。CMAKE_C_COMPILER が見つかりませんでした。
-
[解決済み】C++ - 適切なデフォルトコンストラクタがない [重複]。
-
[解決済み】システムが指定されたファイルを見つけられませんでした。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】非静的メンバ関数への参照を呼び出す必要がある
-
[解決済み】 != と =! の違いと例(C++の場合)
-
[解決済み】C++ 式はポインタからオブジェクトへの型を持っている必要があります。
-
[解決済み】'cout'は型名ではない
-
[解決済み】C++エラー:の初期化に一致するコンストラクタがありません。
-
[解決済み】Visual Studio 2013および2015でC++コンパイラーエラーC2280「削除された関数を参照しようとした」が発生する
-
[解決済み】C++の余分な資格エラー
-
[解決済み] gdbを使用してもデバッグシンボルが見つからない
-
[解決済み】システムが指定されたファイルを見つけられませんでした。
-
[解決済み】'std::cout'への未定義の参照