[解決済み] クラスタ数が未知の場合の教師なしクラスタリング
質問
3次元の大きなベクトル集合があります。私は、任意の特定のクラスタ内のすべてのベクトルが、互いの間のユークリッド距離が閾値よりも小さくなるように、ユークリッド距離に基づいてこれらをクラスタリングする必要がありますquot;T"。
クラスタがいくつ存在するのかわかりません。最終的には、そのユークリッド距離が空間内のどのベクトルとも "T" よりも小さくないため、どのクラスタにも属さない個々のベクトルが存在する可能性があるのです。
ここで使用すべき既存のアルゴリズム/アプローチは何でしょうか?
どのように解決するのか?
あなたは 階層型クラスタリング . これはかなり基本的なアプローチなので、たくさんの実装があります。例えば Python の scipy .
例えば以下のようなスクリプトをご覧ください。
import matplotlib.pyplot as plt
import numpy
import scipy.cluster.hierarchy as hcluster
# generate 3 clusters of each around 100 points and one orphan point
N=100
data = numpy.random.randn(3*N,2)
data[:N] += 5
data[-N:] += 10
data[-1:] -= 20
# clustering
thresh = 1.5
clusters = hcluster.fclusterdata(data, thresh, criterion="distance")
# plotting
plt.scatter(*numpy.transpose(data), c=clusters)
plt.axis("equal")
title = "threshold: %f, number of clusters: %d" % (thresh, len(set(clusters)))
plt.title(title)
plt.show()
とすると、次の画像のような結果になります。
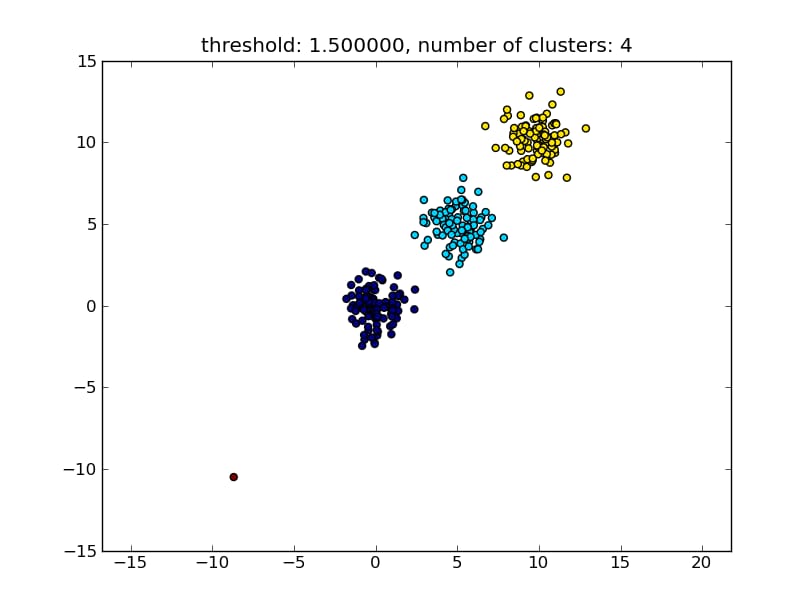
パラメータとして与えられるしきい値は、ポイント/クラスタが別のクラスタにマージされるかどうかを決定するための距離値です。また、使用する距離の指標を指定することもできます。
クラスタ内外の類似度を計算する方法には、最も近い点間の距離、最も遠い点間の距離、クラスタ中心までの距離など、様々な方法があることに注意してください。これらの手法のいくつかは scipys の階層型クラスタリングモジュール ( single/complete/average...リンク ). あなたの投稿によると、私はあなたが使いたいのは 完全な連結 .
なお、このアプローチでは、他のクラスタの類似性基準、つまり距離の閾値を満たさない場合は、小さな(1点の)クラスタも許容されます。
より良いパフォーマンスを発揮する他のアルゴリズムがあり、それは多くのデータポイントがある状況で関連するようになります。他の回答やコメントにあるように、DBSCAN アルゴリズムも見ておくとよいでしょう。
- https://en.wikipedia.org/wiki/DBSCAN
- http://scikit-learn.org/stable/auto_examples/cluster/plot_dbscan.html
- http://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html#sklearn.cluster.DBSCAN
これらのアルゴリズムや他のクラスタリングアルゴリズムの概要については、このデモページ(Pythonのscikit-learnライブラリ)もご覧ください。
画像はそちらからコピーしたものです。
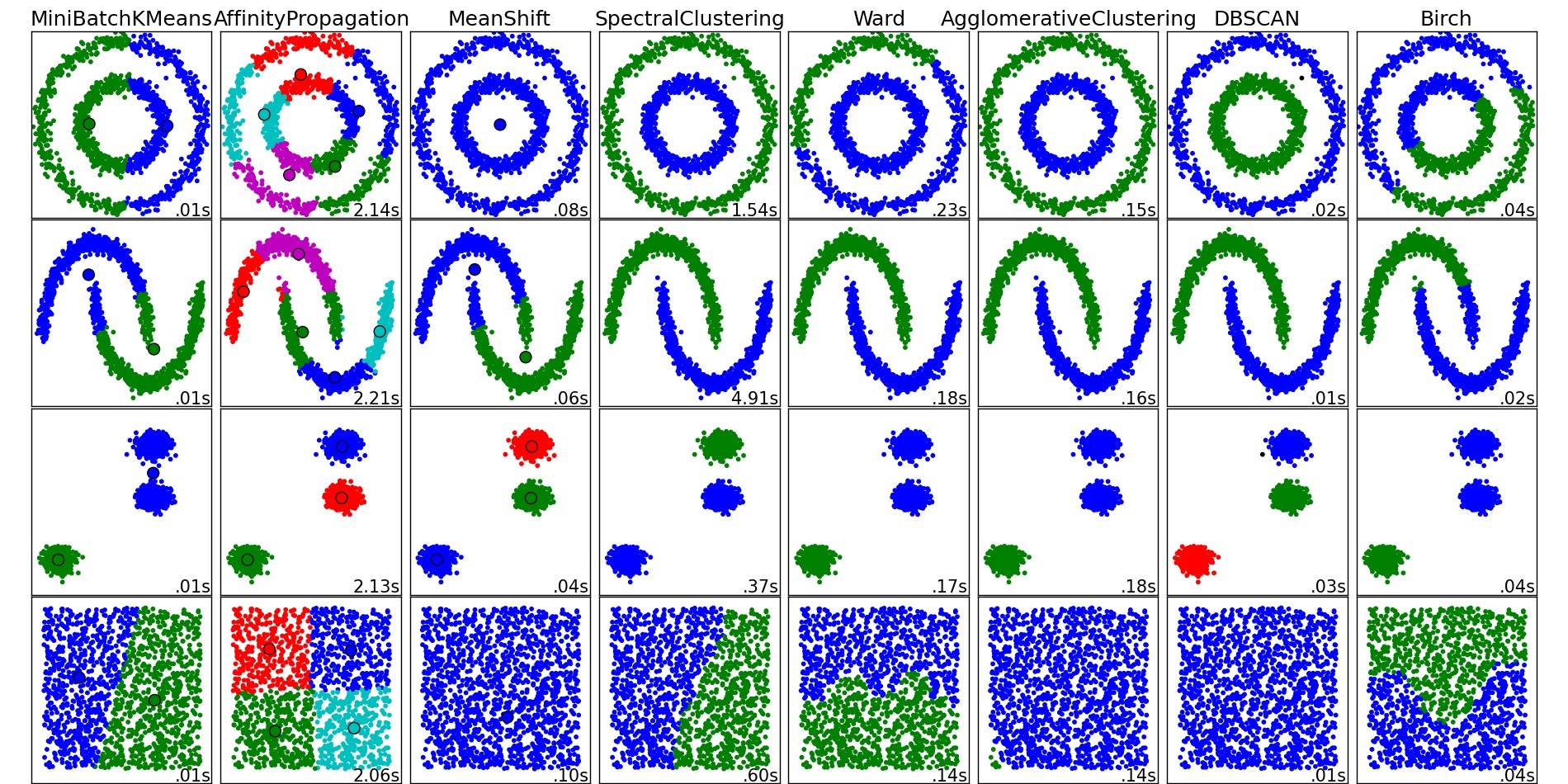
ご覧の通り、各アルゴリズムは考慮すべきクラスタの数と形状についていくつかの仮定をしています。それは、アルゴリズムによって課された暗黙の仮定であったり、パラメータ化によって指定された明示的な仮定であったりします。
関連
-
[解決済み】Quickselectの時間の複雑さを説明する
-
[解決済み】クイックソートとヒープソートの比較
-
[解決済み] 放物線を点の集合にフィットさせる最速の方法?
-
[解決済み] グラフの隣接リスト表現の空間複雑性
-
[解決済み] は、「減少しない」列が「増加する」のか?
-
[解決済み] 整数の平方根が整数であるかどうかを判断する最速の方法
-
[解決済み] 簡単な面接問題が難しくなった:1~100の数字が与えられたとき、ちょうどk個の数字が欠けていることを見つけなさい。
-
[解決済み] 地図上のA地点からB地点への道順を計算するアルゴリズムは?
-
[解決済み】画像処理。コカ・コーラ缶」認識のためのアルゴリズム改良
-
[解決済み] キャッシュの無効化 - 一般的な解決策はありますか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】決定木(比較ソートアルゴリズム)の葉の最短の深さ)
-
[解決済み] 素朴な」アルゴリズムとは何か、「閉じた」解とは何か?
-
[解決済み] 簡単:T(n)=T(n-1)+nを反復法で解く。
-
[解決済み] ラジアンを度数に変換する方法は?
-
[解決済み] log(n!)=Θ(n-log(n))でしょうか?
-
[解決済み] リストの並べ換えをすべて生成するアルゴリズム?
-
[解決済み] 検索語句の上位10位を見つけるアルゴリズム
-
[解決済み] 旧経度+nmから新経度、新緯度を算出する。
-
[解決済み] 学校の時間割を作成するアルゴリズム
-
[解決済み] アルゴリズムで見慣れない記号:∀は何を意味するのか?[クローズド]