シェル文字列マッチングの実装
I. はじめに
Bash Shellは、文字列やファイルを操作するためのコマンドを多数提供しています。Bash Shell は awk, expr, grep, sed などの文字列やファイル操作のための多くのコマンドと、ファイルのソート、マージ、分割のための一連のコマンドを提供します。 grep, sed, awk はより広範囲なので、個別にリストアップしています。
II. 文字列処理
1. exprコマンド
exprは、算術演算、比較演算、文字列演算、論理演算を可能にする汎用評価式を導き出します。
(1) 文字列の長さを計算する
文字列はstringという名前で、${#string}コマンドかexpr length $stringで文字列の長さを計算します。stringにスペースが含まれる場合は、二重引用符で囲む必要があります(expr lengthは引数が1つしか続かないので、スペースを含むstringは複数の引数として扱われます)。

(2) サブストリングマッチングインデックス
expr indexコマンドは、expr index $string $substring (部分文字列) という形式で、$substringに含まれる文字が文字列$stringに最初に出現したときにマッチし、マッチしなかった場合は0を返します。

"wo"は、oが7番目に出現していても、文字列stringの5番目に最初に出現しているものを返します。
(3)部分文字列のマッチングの長さ
expr match $string $substring, string の先頭の部分文字列にマッチします。マッチした部分文字列の長さを返し、先頭でマッチしない場合は0を返します。substringは文字列または正規表現です。

"world"は、文字列の中に現れるが、文字列の先頭には現れないので、0を返す。
(4) 部分文字列の抽出
Bash Shellには、部分文字列を抽出するためのコマンド#{...}とexprが用意されています。
ここで、#{...}には2つの形式があります。
フォーマット1:#{string:position}は、名前$stringを持つ文字列の$positionから、0マーカーから始まる部分文字列を描画します。
フォーマット2:#{string:position:length}は、$string文字列から$lengthの長さの部分文字列を$positionの位置から抽出することを示すために、$length変数を追加します。
(すべての部分文字列は、文字列の左側から数えて抽出されます)
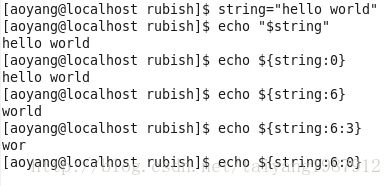
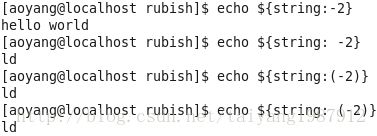
また、#{...}は、文字列の右側から数えて部分文字列を抽出する機能を提供します。
書式1:#{string: -position}、コロンと水平バーの間にスペースがある。
フォーマット2 #文字列:(位置)}。
expr substrは、#{...}とは異なるコマンド形式: expr substr $string $position $length で部分文字列を抽出することも可能です。大きな違いは、expr substr コマンドが 1 で始まることです。

次のコマンドは、正規表現を用いて部分文字列を抽出しますが、文字列の先頭または末尾にあるものだけを抽出します。
文字列の先頭の部分文字列を抽出します。書式1:expr match $string ' $substring '. フォーマット2:expr $string : ' $substring ', ここで、コロンの前後にスペースがあります。
文字列の末尾にある部分文字列を抽出します、フォーマット1:expr match $string '. * $substring '. フォーマット2:expr $string : '. * $substring '. * は、任意の文字の繰り返しを示します。
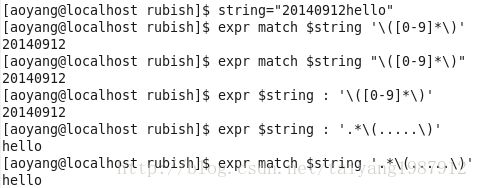
(5)部分文字列の削除
文字列の削除とは、元の文字列から対象となる部分文字列を削除することで、コマンドは${...}形式のみです。
文字列の先頭から部分文字列を削除するフォーマット 1: ${string#substring}, 先頭の部分文字列と一致する最短の部分文字列を削除する。フォーマット2: ${string##substring} で、先頭のsubstringにマッチする最も長いsubstringを削除します。ここで、substringは正規表現ではなく、ワイルドカードです。

文字列の末尾から削除する場合、フォーマット1: ${string%substring}, 末尾の部分文字列に一致する最短の部分文字列を削除します。フォーマット2: ${string%%substring} は、末尾の部分文字列と一致する最も長い部分文字列を削除します。上のコマンドと異なるのは、#と% の間だけです。
(5) 部分文字列の置換
replace substringコマンドは、${...}が条件を満たす文字列の先頭や末尾など、任意の場所で部分文字列を置き換えることができるコマンドです。部分文字列は正規表現ではなく、ワイルドカードを使用します。
どこでも部分文字列の置き換えコマンドは、フォーマット1: ${string/substring/replacement} で、部分文字列にマッチする最初の部分文字列のみを置き換えます。フォーマット2: ${string//substring/replacement}, サブストリングにマッチするすべてのサブストリングを置き換えます。

先頭の部分文字列と一致する部分文字列を${string/#substring/replacement}の形式で置き換えます。
末尾の部分文字列に一致する部分文字列を、${string/%substring/replacement}の形式で置き換えます。

III. ファイルの並べ替え、結合、分割
テキスト処理コマンドには、sort, uniq, join, cut, paste, split, tr, tar があり、ファイルレコードのソート、カウント、マージ、抽出、ペースト、分割、フィルタ、圧縮、解凍を行い、これらと sed, awk で Linux テキスト処理の全コマンドとツールを構成している。
(1) ソートコマンド
sortコマンドは、入力ファイルを、改行で区切られた可変幅のフィールドからなる複数のレコードのストリームとして扱う、テキストのソートツールである。 sortコマンドのフォーマット: sort [option] [input file]
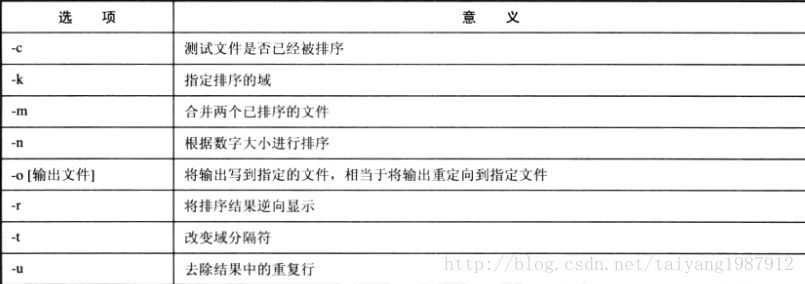
sort -t: test は、-t と ": " の間にスペースを入れません。セパレータに-tを指定しない場合、レコードの先頭と末尾にスペースがあっても無視されます。例えば、1フィールドの場合は (スペース):ルート:(スペース)、3フィールドの場合は -t: でコロンになります。
sortコマンドは、デフォルトでは最初のフィールドでソートされますが、-kオプションでソートするフィールドを指定することができます。例:sort -t: -k3 test.
sortコマンドの-nオプションは、アルファベット順ではなく、数値の大きさでソートを指定することができます。
sortコマンドの-rオプションは、ソート結果を逆順に表示するために使用します。例えば、-nオプションを使用して、小さいものから大きいものへと番号順にソートした後、結果を逆順に表示することができます。
sortコマンドの-uオプションは、ソート結果から重複した行を削除します。
sortコマンドの-oオプションとファイル名を指定すると、結果を別のファイルに保存します(sortはデフォルトでソート結果を画面に出力します)。
sortコマンドの-mオプションは、ソートされた2つのファイルを1つのソートされたファイルにマージします。mオプションは、順序のないファイルのマージには意味を持ちません。
sort と awk はどちらもファイルを別々のフィールドで扱うためのツールで、この 2 つの組み合わせはテキストブロックのソートに効果的です。
(2) uniqコマンド
uniqコマンドは、sort -uと同様にテキストファイルから重複行を削除するために使用しますが、sort -uコマンドは重複するレコードをすべて削除するのに対し、uniqコマンドで削除する重複行は他のテキスト行を挟まない連続した再帰的な行である必要があります。
uniqコマンドには3つのオプションがあります。

uniq -c test, テキスト中の各行が何回繰り返されたかを表示します。
(3) joinコマンド
joinコマンドは、2つのファイルにあるレコードを結合するために使用されます。これは、2つのファイルのレコードのうち、共通のドメインを持つレコードを選択し、それらのレコードのすべてのドメインを1行に並べます(2つのファイルのすべてのドメインを含む)。たとえば、join -t: a.txt b.txtは、a.txtとb.txtのレコードのうち、共通のドメインを持つレコードを結合するものです。

joinコマンドの結果は、デフォルトではこれらの未結合レコードを表示しません。これらの未結合レコードを表示するには、-aおよび-vオプションを使用します。-a1および-v1はファイル1の未結合レコードを表示し、-a2および-v2はファイル2の未結合レコードを表示することを意味します。aと-vの違いは、-aは共通ドメインで行われた結合の結果と結合されていないレコードを表示し、-vは共通ドメインで結合されたレコードを表示しないことである。
joinコマンドは、デフォルトで、joinレコードの両方のファイルに含まれるすべてのドメインを順番に表示します。oオプションを使用すると、結果表示の形式が変更され、表示するドメインとその順序を指定できます。例: join -t: -o1.1 2.2 1.2 a.txt b.txt, ここで -o1.1 2.2 1.2 は、表示形式が最初のファイルの最初のドメイン、2番目のファイルの2番目のドメイン、最初のファイルの2番目のドメインをこの順で表示し、結果として3つのドメインを表示することを意味しています。
join -t: -i -1 3 -2 1 a.txt b.txt, ファイル1の3番目のドメインとファイル2の最初のドメインを結合します、-iは大文字小文字を無視します。
(4) カットコマンド
cutコマンドは、標準入力やテキストファイルからフィールドや行単位でテキストを抽出するために使用します。 cut [オプション]ファイルのcutのオプションは、次のとおりです。

cut -c1-5 a.txt, a.txtの1文字目から5文字目を抽出します。cには、n文字目を表す-cn、n文字目とm文字目を表す-cn,m、n文字目からm文字目を表す-cn-mという3つの表現があります。-cは文字単位でテキストを抽出するもので、ドメインセパレータを変更するために-dを使用する必要はありません、-fはドメイン単位でテキストを抽出するもので、ドメインセパレータを設定するために-dを使用する必要があります。また、-fはドメインの数や範囲を指定するために、3つの使い方ができます。
cut は、テキストファイルからコンテンツを抽出する柔軟性を備えています。デフォルトで標準出力に出力するか、ファイルリダイレクトを使用してコンテンツをファイルに保存します。
(5) 貼り付けコマンド
pasteコマンドは、テキスト・ファイルや標準出力の内容を新しいファイルに貼り付けるために使用します。異なるファイルのデータをまとめて新しいファイルに貼り付けることができます。 pasteコマンドの形式: paste [option] file1 file2, オプションは次のとおりです。
<イグ
paste FILE1 FILE2, FILE1 と FILE2 を、FILE1 を先に、FILE1 の内容をフィールド 1、FILE2 の内容をフィールド 2 として、レコードの各行に貼り付けます。ドメインセパレータpaste -d: FILE1 FILE2 は、-d で設定できます。
pasteコマンドは、デフォルトではファイルを列単位で貼り付けますが、-sオプションを付けると行単位で貼り付けることができます。
ls | paste -d" " - - -, "-" オプションは、標準入力からデータを読み込むときに機能します、 "-" は1回の標準入力データの読み込み、つまり標準入力データのフィールドを読むことを意味します、 - -は1行に4ファイル名を示します。
(6)スプリットコマンド
splitコマンドは,大きなファイルを小さなファイルに分割するために使います. splitは,ファイルの行数やバイト数に応じてファイルを分割したり,複数の小さなファイルに自動的に番号を付けて出力したりできます. splitコマンドの形式: splite [option] 分割する大きなファイル 小さなファイルを出力します.

split -2 a.txt final.txt, a.txt を2行ずつ切り、2行のレコードを1ファイルに分割する。split コマンドは、aa〜zzの番号で、異なる小さなファイルを区別するために final.txt の後に自動的に番号を追加する。
split -b100 a.txt, -b オプションはファイルをカットする際にファイルサイズのみを考慮し、記録の整合性は考慮しない。 split -C100 a.txt, a.txt を100B単位でカットする。-Cを押すと100Bというサイズに厳密に従わず、各行の整合性を維持しながらカットしようとします。
(7)trコマンド
trコマンドは,sedコマンドと同様に文字変換機能を実装しています. tr [options] buffer1 buffer2 < outputfileは,3つのオプションがあり,標準入力からのデータのみ読み込むことができます.

tr -d A-Z < a.txt からすべての大文字を削除します。
tr -d "[\n]" < a.txt, a.txt ファイル内の改行をすべて削除します。
tr -s "[\n]" < a.txt, 繰り返し行われる改行を1つの改行に圧縮します。
tr コマンドは、buffer1 と buffer2 を追加して、buffer1 を buffer2 に置き換えることもできます。 tr "[a-z]" "[A-Z]" < a.txt の小文字を大文字に置き換えます。
(8) tarコマンド
tarコマンドは、linuxのアーカイブコマンドで、linuxのシステムファイルの圧縮と解凍を可能にします。 tar [オプション] ファイル名またはディレクトリ名、tarの共通オプションは次のとおりです。

tar -cf a.tar *.txt, .txt で終わるすべてのファイルを zip パッケージ a.tar に入れます。-c は新しいパッケージを作るという意味で、-f は通常、必須のオプションです。
tar -tf a.tar: a.tar zipパッケージの内容を表示します。-tはパッケージの中身を一覧表示します。
tar -rf a.tar log*, logで始まるファイルをa.tarに追加します.また,-uオプションは-rオプションの完全な置き換えです.
非gzipパッケージの解凍方法:tar -xvf パッケージ名
gzip形式のアーカイブを解凍する:tar -zxvf アーカイブ名
IV. 概要
(1) 文字列処理、テキスト処理コマンドは、各種シェルスクリプトに多く含まれており、習熟しておく必要がある。
(2) sort, uniq, join, cut, paste, split, tr, tar と grep, sed, awk は、linux のテキスト処理用のコマンドとツールを構成しています。
(3) この記事はあくまでガイドであり、コマンドの詳細なオプションについては、対応するドキュメントを参照する必要があります。
シェル文字列マッチングに関する記事は以上です。シェル文字列照合についての詳細は、Scripting Houseの過去の記事を検索するか、以下の記事を引き続き閲覧してください。
関連
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
シェルバッチプロセスで存在するかどうかを判断する
-
シェルスクリプトとmy.cnfによるmysqlの追加・削除・設定
-
シェルスクリプト暗号化ツールshcの詳細説明
-
シェルスクリプトでの/dev/nullの使用方法まとめ
-
teeコマンドでシェルスクリプトのパイプラインをデバッグする方法
-
[解決済み】Bash スクリプトと /bin/bash^M: bad interpreter: そのようなファイルまたはディレクトリがない [重複] [重複
-
詳細な手順でフォーマットされたディスクを素早く作成するシェルスクリプト
-
シェルスクリプトのクイックスタート - 条件文とループ
-
シェルでのawk printの使い方を解説します
-
シェルスクリプトの実践 - whileループ文