[解決済み] データフレームセルの中のリストを分割して表示する方法
2022-12-20 19:45:14
質問
リストを含むpandasセルを、それぞれの値の行に変えたいと思っています。
そこで、これを
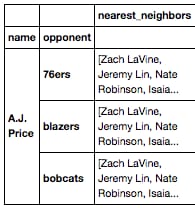
の値を解凍して積み重ねたいのであれば、このようにします。
nearest_neighbors
カラムの値を展開して積み重ね、各値が各
opponent
インデックスを作成する必要がありますが、どのようにすればよいのでしょうか?このような操作のためのpandasメソッドはありますか?
どのように解決するのですか?
以下のコードでは、まずインデックスをリセットして、行の繰り返しを容易にします。
外側のリストの各要素が目的のDataFrameの行で、内側のリストの各要素が列の1つであるリストのリストを作成します。 このネストされたリストは最終的に連結され、目的のDataFrameが作成されます。
を使っています。
lambda
の各要素に対して行を作成するために、リストの反復処理と一緒に関数を使用します。
nearest_neighbors
の各要素と関連する
name
と
opponent
.
最後に、このリストから新しいDataFrameを作成します(元のカラム名を使用し、インデックスを
name
と
opponent
).
df = (pd.DataFrame({'name': ['A.J. Price'] * 3,
'opponent': ['76ers', 'blazers', 'bobcats'],
'nearest_neighbors': [['Zach LaVine', 'Jeremy Lin', 'Nate Robinson', 'Isaia']] * 3})
.set_index(['name', 'opponent']))
>>> df
nearest_neighbors
name opponent
A.J. Price 76ers [Zach LaVine, Jeremy Lin, Nate Robinson, Isaia]
blazers [Zach LaVine, Jeremy Lin, Nate Robinson, Isaia]
bobcats [Zach LaVine, Jeremy Lin, Nate Robinson, Isaia]
df.reset_index(inplace=True)
rows = []
_ = df.apply(lambda row: [rows.append([row['name'], row['opponent'], nn])
for nn in row.nearest_neighbors], axis=1)
df_new = pd.DataFrame(rows, columns=df.columns).set_index(['name', 'opponent'])
>>> df_new
nearest_neighbors
name opponent
A.J. Price 76ers Zach LaVine
76ers Jeremy Lin
76ers Nate Robinson
76ers Isaia
blazers Zach LaVine
blazers Jeremy Lin
blazers Nate Robinson
blazers Isaia
bobcats Zach LaVine
bobcats Jeremy Lin
bobcats Nate Robinson
bobcats Isaia
EDIT JUNE 2017
別の方法として、次のような方法があります。
>>> (pd.melt(df.nearest_neighbors.apply(pd.Series).reset_index(),
id_vars=['name', 'opponent'],
value_name='nearest_neighbors')
.set_index(['name', 'opponent'])
.drop('variable', axis=1)
.dropna()
.sort_index()
)
関連
-
[解決済み] リストのリストからフラットなリストを作るには?
-
[解決済み] PandasでDataFrameの行を反復処理する方法
-
[解決済み] 列の値に基づいてDataFrameから行を選択するにはどうすればよいですか?
-
[解決済み] リストを均等な大きさの塊に分割するには?
-
[解決済み] pandasを使った "大量データ "ワークフロー【終了しました
-
[解決済み] オブジェクトの属性に基づいてオブジェクトのリストを並べ替えるには?
-
[解決済み] 空のPandas DataFrameを作成し、それを埋める?
-
[解決済み] pandas DataFrameの特定のセルに対して、インデックスを使用して値を設定する
-
[解決済み] データフレームのセルから値を取得するには?
-
[解決済み】pandasでカラムの種類を変更する
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み] pandas DataFrameのカラムを複数行にアンネスト(分解)する方法
-
[解決済み] Jupyterノートブックでenv変数を設定する方法
-
[解決済み] django.db.migrations.exceptions.InconsistentMigrationHistory
-
[解決済み] タプルのリストを複数のリストに変換するには?
-
[解決済み] Ctrl-CでPythonスクリプトを終了できない
-
[解決済み] PyQtアプリケーションのスレッド化。QtスレッドとPythonスレッドのどちらを使うか?
-
[解決済み] Celeryタスクのユニットテストはどのように行うのですか?
-
[解決済み] Pythonでファイルの読み込みと上書きをする
-
[解決済み] データクラスとtyping.NamedTupleの主な使用例
-
[解決済み] pipの依存性/必要条件をリストアップする方法はありますか?