float32とfloat64の本質的な違い(ディープラーニングへの型影響とpythonの活用)。
まず、ビットとバイトとは何か?
- bits:名前付きビット
- bytes:はバイト数
- 単純な数字で言うとMBとGの関係です! つまり8bits=1bytesで、単位の相互変換はこちら!
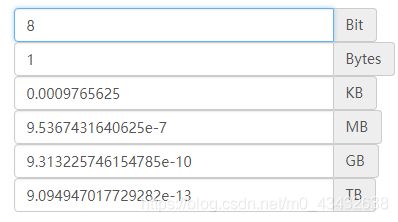
では、float32とfloat64の違いは何でしょうか?
- 桁数の違い
- 1つは、それぞれ32ビットと64ビットのメモリを占有し、4バイトまたは8バイトとなる
- ビット数が多いほど浮動小数点数の精度は高くなる
ディープラーニングの計算効率に影響を与えるか?
float64はfloat32の2倍、float16の4倍のメモリを消費します。例えば、CIFAR10データセットでは、float64で表現すると60,000*32*3*8/1024*3=1.4Gかかり、データセットをメモリに転送するだけで1.4Gかかるのに対し、float32であれば、わずか0.4Gで済みます。 7G、float16を使用する場合は、0.35G程度を必要とし、メモリの量を占有し、システムの動作効率に深刻な影響を与える。
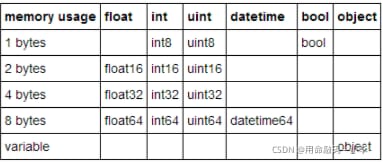
Pandasのデータ型別メモリ消費量テーブル
Pythonはnumpyを使用してデータ型をfloat32に設定する
import numpy as np
data = np.array([1,2,3,4,5,6,7,8,9],dtype='float32')
float32と64のメモリフットプリントのpandas解析
pandasが高速なのは、データをメモリにロードして処理するためです。ここでは、pandasを使ってデータを別々にロードすることで、同じデータが異なるデータ型に対してどのようにメモリを消費するのかを見てみましょう〜。
import pandas as pd
data = pd.DataFrame([1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9], dtype="float64")
data1 = pd.DataFrame([1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9], dtype="float32")
print(data.info(memory_usage=True))
print(data1.info(memory_usage=True))
結果は次のように出力されます。あとは、どれだけのメモリを使用しているかを確認するだけです。 float64のデータは192byte、float32のデータは160byteを消費します。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8件、0~7
データ列(合計1列)。
# 列の非NULL数 D型
--- ------ -------------- -----
0 0 8 非NULL float64
dtypes: float64(1)
メモリ使用量 192.0 bytes -----------------> メモリ使用量サイズ
なし
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8件、0~7
データ列(合計1列)。
# 列の非NULL数 D型
--- ------ -------------- -----
0 0 8 非Nullのfloat32
dtypes: float32(1)
メモリ使用量 160.0 bytes ----------------->メモリ使用量サイズ
なし
関連
-
チェックされていないruntime.lastError: 接続を確立できませんでした。受信側が存在しません。
-
Abort trap: 6エラーに対するPythonの解決策
-
ValueError: 入力配列を形状 (22500,3) から形状 (1) にブロードキャストできなかった。
-
SyntaxError: 構文が無効です。
-
SyntaxError: 構文が無効です。
-
ModuleNotFoundError: django という名前のモジュールがない 問題1解決済み
-
python で word, excel, csv, json ファイルの読み書きをする。
-
TypeError: 'str' と 'int' のインスタンスの間で '<' はサポートされていません。
-
Solve UnicodeDecodeError: 'ascii' codec can't decode byte 0xba in position 31: ordinal not in range(128)
-
Pythonです。AttributeError: module 'numpy' has no attribute 'dtype' 問題が解決されました。
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Ubuntu pip AttributeError: 'module' オブジェクトに '_main' 属性がない。
-
移動平均のPython実装
-
Python OSError: [Errno 22] 無効な引数: solution
-
[コード】pygame 学習
-
[Pythonノート】spyderのClearコマンド
-
Python による pyserial 経由でのシリアルポートの読み取りと書き込み
-
ValueErrorです。変数 `x` と `y` のどちらも数値でないように見えます。
-
Python で実行 TypeError: + でサポートされていないオペランド型: 'float' および 'str'.
-
Python ネットワークリクエストのエラー "ConnectionRefusedError: [WinError 10061] ターゲットコンピュータがアクティブに拒否したため接続できません"
-
Pythonのselfの使い方を詳しく、または常にプロンプトを表示します。TypeError: add() missing 1 required positional argument: 'self' 問題は解決されました。