[解決済み] boost::flat_map と map, unordered_map との性能比較
質問
キャッシュヒットによりメモリ局所性が性能を大きく向上させることは、プログラミングの常識です。最近知ったのですが
boost::flat_map
という、ベクトルベースのマップの実装を知りました。これは、典型的な
map
/
unordered_map
というように、性能の比較対象が見つからないのです。どのように比較し、どのようなユースケースが最適なのでしょうか?
ありがとうございます。
どのように解決するのですか?
最近、会社でいろいろなデータ構造のベンチマークを行ったので、一言書いておきます。正しくベンチマークを行うのは非常に複雑です。
ベンチマーク
Web 上では、よく設計されたベンチマークを見つけることは (たとえあったとしても) めったにありません。今日まで、私はジャーナリスト的な方法で行われた (かなり速く、何十もの変数をカーペットの下で一掃した) ベンチマークを見つけただけでした。
1)
キャッシュウォーミングアップを考慮する必要があります。
ベンチマークを実行しているほとんどの人は、タイマーの不一致を恐れています。したがって、彼らは自分のものを何千回も実行し、全体の時間を取る、彼らはちょうどすべての操作のために同じ千回を取るように注意して、そして、それを比較可能と見なします。
実際のところ、現実の世界では、キャッシュは暖かくなく、操作はおそらく一度だけ呼び出されるため、ほとんど意味がありません。したがって、RDTSC を使用してベンチマークを行い、1 回だけそれらを呼び出すものを時間指定する必要があります。 Intelは次のような論文を発表しています。 を記述しています。 RDTSC を使用する方法 (cpuid 命令を使用してパイプラインをフラッシュし、安定させるためにプログラムの最初に少なくとも 3 回呼び出す) を説明したペーパーを作成しました。
2) RDTSCの精度測定
こんなこともおすすめです。
u64 g_correctionFactor; // number of clocks to offset after each measurement to remove the overhead of the measurer itself.
u64 g_accuracy;
static u64 const errormeasure = ~((u64)0);
#ifdef _MSC_VER
#pragma intrinsic(__rdtsc)
inline u64 GetRDTSC()
{
int a[4];
__cpuid(a, 0x80000000); // flush OOO instruction pipeline
return __rdtsc();
}
inline void WarmupRDTSC()
{
int a[4];
__cpuid(a, 0x80000000); // warmup cpuid.
__cpuid(a, 0x80000000);
__cpuid(a, 0x80000000);
// measure the measurer overhead with the measurer (crazy he..)
u64 minDiff = LLONG_MAX;
u64 maxDiff = 0; // this is going to help calculate our PRECISION ERROR MARGIN
for (int i = 0; i < 80; ++i)
{
u64 tick1 = GetRDTSC();
u64 tick2 = GetRDTSC();
minDiff = std::min(minDiff, tick2 - tick1); // make many takes, take the smallest that ever come.
maxDiff = std::max(maxDiff, tick2 - tick1);
}
g_correctionFactor = minDiff;
printf("Correction factor %llu clocks\n", g_correctionFactor);
g_accuracy = maxDiff - minDiff;
printf("Measurement Accuracy (in clocks) : %llu\n", g_accuracy);
}
#endif
これは不一致測定器であり、時々-10**18(64ビットの最初の負の値)を得ることを避けるために、すべての測定値の最小値を取ります。
インラインアセンブリではなく、イントリンシックが使用されていることに注意してください。インライン アセンブリは現在ではほとんどサポートされていませんが、さらに悪いことに、コンパイラーは内部を静的に分析できないため、インライン アセンブリの周囲に完全な順序の障壁を作成し、これは現実世界のもののベンチマーク、特に 1 回だけものを呼び出すときの問題です。そのため、特に一度だけ何かを呼び出す場合、これは実世界のものをベンチマークする上で問題となります。したがって、コンパイラによる命令の自由な再順序付けを壊さないという点で、組み込みが適しているのです。
3) パラメータ
最後の問題は、人々は通常、シナリオのバリエーションが少なすぎることをテストします。 コンテナの性能は次のような影響を受けます。
- アロケータ
- 含まれる型のサイズ
- 含まれる型のコピー操作、割り当て操作、移動操作、構築操作の実装コスト。
- コンテナの要素数(問題の大きさ)
- 型が些細な3.-演算を持つ
- タイプはPODです。
ポイント1が重要なのは、コンテナは時々割り当てを行い、CRT "new"を使用して割り当てを行うか、プール割り当てやフリーリストなどのユーザー定義の操作を行うかが非常に重要であるためです。
( pt 1 に興味がある人のために。 gamedevの謎のスレッドに参加してください。 システム アロケータのパフォーマンスへの影響について )
ポイント 2 は、一部のコンテナ (たとえば A) がものをコピーする時間を失い、型が大きくなればなるほどオーバーヘッドが大きくなるためです。問題は、別のコンテナ B と比較した場合、A は小さな型では B に勝ち、大きな型では負ける可能性があるということです。
ポイント3は、コストに何らかの重み付けをする以外は、ポイント2と同じです。
ポイント 4 は、キャッシュの問題と混在するビッグ O の問題です。いくつかの悪い複雑さのコンテナーは、少数の型について低い複雑さのコンテナーよりも大きく上回ることができます (たとえば
map
vs.
vector
はキャッシュの局所性が良いからです。
map
はメモリを断片化するからです)。そして、ある交差点で、含まれる全体のサイズがメイン メモリに "リーク" し始め、キャッシュ ミスが発生するため、さらに漸近的複雑さが感じられ始めるため、負けることになります。
ポイント5は、コンパイラがコンパイル時に空や些細なものを省くことができるようになることです。コンテナはテンプレート化されており、各タイプは独自のパフォーマンスプロファイルを持っているため、これはいくつかの操作を大幅に最適化することができます。
ポイント6 ポイント5と同じで、PODはコピー構築は単に
memcpy
であること、そして、いくつかのコンテナでは、部分テンプレート特化、またはTの特徴に従ってアルゴリズムを選択するSFINAEを使用して、これらのケースのための特定の実装を持つことができます。
フラットマップについて
フラットマップは Loki AssocVector のようなソートされたベクターラッパーですが、C++11 で追加されたいくつかの近代化機能があり、単一の要素の挿入と削除を高速化するために移動セマンティクスを利用します。
これはまだ順序付きコンテナです。ほとんどの人は通常、順序付けの部分を必要としません。
unordered..
.
が必要かもしれないと考えたことはありますか?
flat_unorderedmap
のようなものが必要かもしれません。
google::sparse_map
のようなもので、オープン・アドレス・ハッシュ・マップです。
オープンアドレスハッシュマップの問題点は
rehash
の時に、すべてを新しい拡張された平らな土地にコピーしなければならないことです。一方、標準の非順序型マップは、ハッシュ インデックスを再作成するだけで、割り当てられたデータはそのまま残ります。もちろん、不利な点は、メモリが地獄のように断片化されることです。
オープン アドレス ハッシュ マップにおけるリハッシュの基準は、容量がバケット ベクターのサイズにロード ファクターを掛けたものを超えるときです。
典型的なロードファクターは
0.8
したがって、それを気にする必要があります。もし、ハッシュマップを埋める前にサイズを調整できるのであれば、常に
intended_filling * (1/0.8) + epsilon
これは、充填中に意図的にすべてをリハッシュおよび再コピーする必要がないことを保証するものです。
クローズド・アドレス・マップの利点は (
std::unordered..
) の利点は、これらのパラメータを気にする必要がないことです。
しかし
boost::flat_map
は順序付きベクトルです。したがって、それは常にlog(N)の漸近的複雑さを持ち、オープンアドレスハッシュマップ(償却済み定数時間)より劣ります。その点も考慮する必要があります。
ベンチマーク結果
これは、異なるマップを含むテストです (
int
キーと
__int64
/
somestruct
を値として)、そして
std::vector
.
テストされたタイプの情報です。
typeid=__int64 . sizeof=8 . ispod=yes
typeid=struct MediumTypePod . sizeof=184 . ispod=yes
挿入
EDITです。
私の以前の結果にはバグが含まれていました。実際に順序付き挿入をテストし、フラット マップに対して非常に高速な動作を示しました。
これらの結果は興味深いものなので、このページの後半に残しました。
これは正しいテストです。
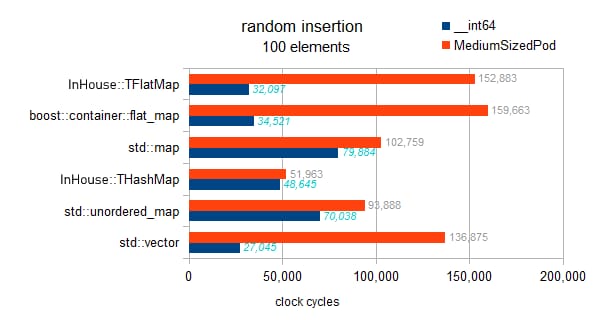
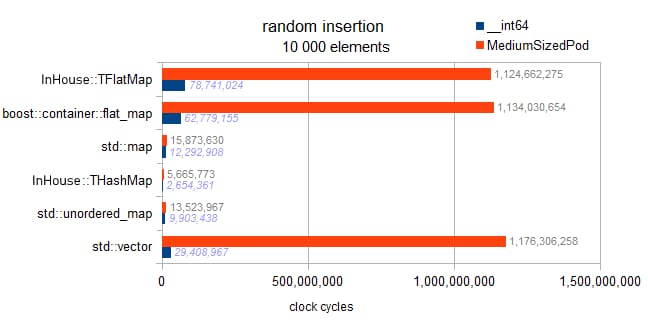
実装を確認したところ、ここのフラットマップには遅延ソートのようなものは実装されていません。各挿入がその場でソートされるため、このベンチマークは漸近的な傾向を示しています。
マップの O(N * log(N))
ハッシュマップ O(N)
ベクトルおよびフラットマップ O(N * N)
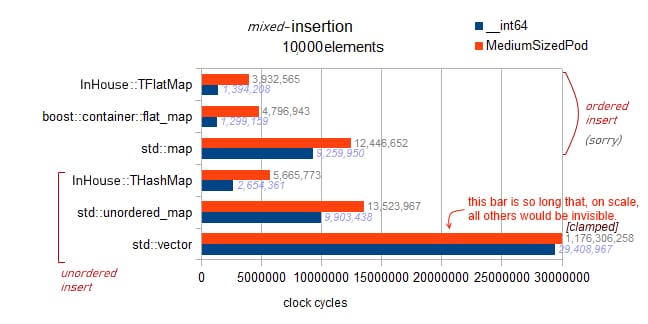
警告
: 以下、2つのテストは
std::map
と
flat_map
は
バギー
で、実際にテストするのは
順序付き挿入
をテストします(他のコンテナのランダム挿入と比較して。はい、紛らわしいですね、すみません)。
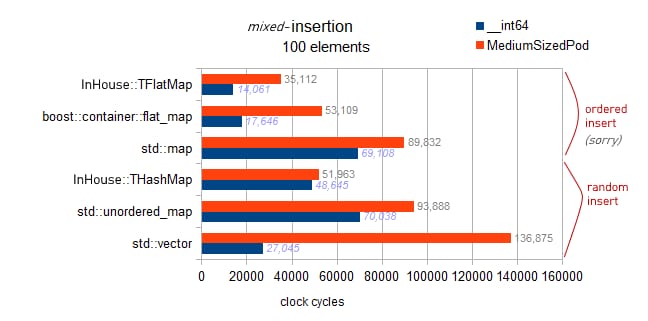
順序付き挿入、バック プッシュの結果、非常に高速であることがわかります。しかし、私のベンチマークの非チャートの結果から、これはバック挿入の絶対的な最適性に近いものではないとも言えます。10k要素では、事前予約されたベクターで完全な逆挿入の最適性が得られます。これは3百万サイクルになります。
flat_map
への順序付き挿入で 4.8M を観察します (したがって、最適の 160%)。
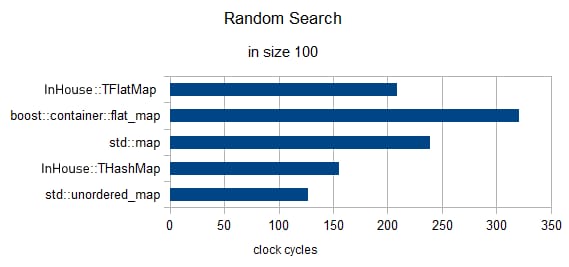
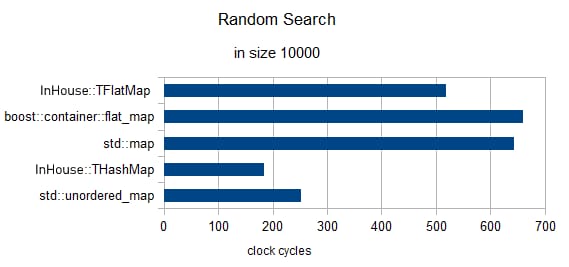
3要素のランダムサーチ(クロックは1に再正規化済み)
サイズ = 100
サイズ = 10000
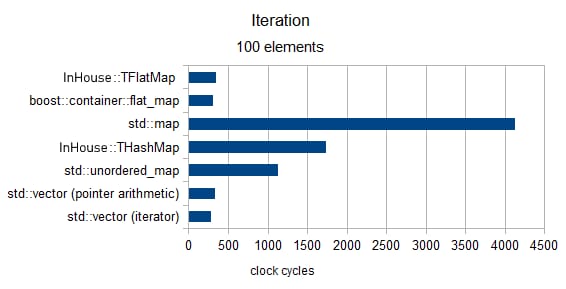
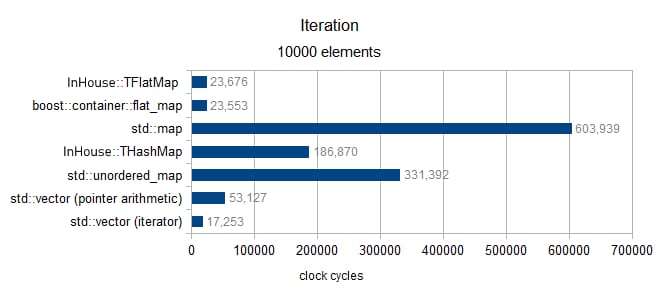
イテレーション
サイズ100以上(MediumPodタイプのみ)
サイズ10000以上(MediumPodタイプのみ)
最後の塩の粒
結局、"Benchmarking §3 Pt1" (the system allocator)に戻ってきたいと思いました。最近の実験で、私は以下のようなパフォーマンス周りをやっています。
というオープンアドレスのハッシュマップを開発しました。
のパフォーマンスに関して行っている最近の実験では、Windows 7 と Windows 8 の間で 3000% 以上のパフォーマンスの差があることを測定しました。
std::unordered_map
のユースケース (
ここで説明した
).
このため、上記の結果について読者に警告したいと思います (これらは Win7 で作成されました)。
関連
-
[解決済み】致命的なエラー LNK1169: ゲームプログラミングで1つ以上の多重定義されたシンボルが発見された
-
[解決済み】文字列関数で'char const*'のインスタンスを投げた後に呼び出されるterminate [閉店].
-
[解決済み] 既に.objで定義されている-二重包含はない
-
[解決済み】Visual C++で "Debug Assertion failed "の原因となる行を見つける。
-
[解決済み】エラー:不完全な型へのメンバーアクセス:前方宣言の
-
[解決済み】浮動小数点数の乱数生成
-
[解決済み】std::cin.getline( ) vs. std::cin
-
[解決済み】演算子のオーバーロード C++; <<操作のパラメータが多すぎる
-
[解決済み] 些細なキーの場合、unordered_mapよりもmapを使用する利点はありますか?
-
[解決済み] Rubyのmapとcollectの違い?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
[解決済み】coutはstdのメンバではない
-
[解決済み】LLVMで暗黙のうちに削除されたコピーコンストラクタの呼び出し
-
[解決済み】非静的メンバ関数への参照を呼び出す必要がある
-
[解決済み】テンプレートの引数1が無効です(Code::Blocks Win Vista) - テンプレートは使いません。
-
[解決済み】デバッグアサーションに失敗しました。C++のベクトル添え字が範囲外
-
[解決済み】「std::operator」で「operator<<」にマッチするものがない。
-
[解決済み】リンカーエラーです。"リンカ入力ファイルはリンクが行われていないため未使用"、そのファイル内の関数への未定義参照
-
[解決済み] 非静的データメンバの無効な使用
-
[解決済み】演算子のオーバーロード C++; <<操作のパラメータが多すぎる
-
[解決済み】変数やフィールドがvoid宣言されている