[解決済み] 2012年、なぜpythonのpandasマージはRのdata.tableマージより速かったのか?
質問
最近、私は パンダ によると、このライブラリは このベンチマーク は非常に高速なインメモリマージを実行します。 これは データテーブル パッケージで提供されています。
なぜ
pandas
よりもはるかに高速です。
data.table
? Python が R よりも本質的に速いという利点があるからでしょうか、それとも私が知らない何らかのトレードオフがあるのでしょうか? で内側joinと外側joinを実行する方法はありますか?
data.table
に頼ることなく
merge(X, Y, all=FALSE)
と
merge(X, Y, all=TRUE)
?
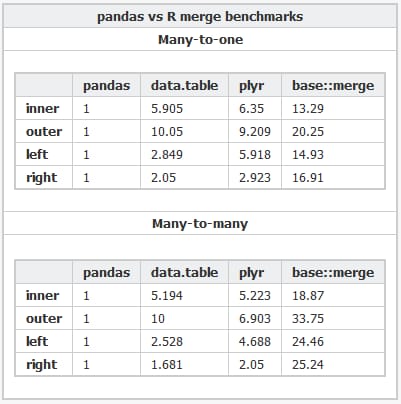
以下は Rコード と Pythonコード 様々なパッケージのベンチマークに使用されます。
どのように解決するのですか?
での既知の問題を発見したようです。
data.table
一意な文字列の数が多い場合 (
レベル
)が大きい。10,000.
はたして
Rprof()
は、通話に費やされた時間のほとんどを明らかにします。
sortedmatch(levels(i[[lc]]), levels(x[[rc]])
? これは、本当は結合そのもの(アルゴリズム)ではなく、その前段階です。
最近の取り組みでは、キーに文字列を使えるようにすることで、R自身のグローバルな文字列ハッシュテーブルとより密接に統合することで、この問題を解決することができるはずです。いくつかのベンチマーク結果は、すでに
test.data.table()
しかし、このコードはまだレベル間のマッチングを置き換えるためにフックアップされていません。
pandas のマージの速さは
data.table
通常の整数カラムの場合? それは、アルゴリズムそのものと要因の問題を切り分ける方法であるはずです。
また
data.table
は
時系列マージ
を念頭に置いています。それには2つの側面があります:i) マルチカラム
オーダーメイド
のようなキー (id,datetime) ii) 高速な優先結合 (
roll=TRUE
)、すなわち、最後の観測が繰り越される。
との比較は初めて見たので、確認に時間が必要です。
data.table
を提示した。
2012年7月リリース data.table v1.8.0からUPDATE。
- 内部関数 sortedmatch() を削除し、chmatch() に置き換えた。 型 'factor' の列で i レベルと x レベルをマッチングさせる場合。この この予備的なステップにより、(既知の)著しい速度低下が発生しました。 のレベルが大きい場合(例:>10,000)。で悪化しました。 このような4つの列を結合するテストは、Wes McKinneyによって実証されました。 (PythonパッケージPandasの作者)です。100万個の文字列をマッチングし、そのうち のうち60万個が一意である場合、例えば16秒から0.5秒に短縮されました。
また、そのリリースでは、:
-
文字列がキーに使用できるようになり、キーよりも優先されるようになりました。 data.table() と setkey() は、文字を強制的に変換しなくなりました。 係数になります。因数分解はまだサポートされています。FR#1493, FR#1224 を実装。 と(部分的に)FR#951を追加しました。
-
新しい関数 chmatch() と %chin% は、match() の高速版です。 および文字ベクトル用の %in% があります。Rの内部文字列キャッシュが を利用する(ハッシュテーブルを構築しない)。約4倍高速化 chmatchの例では、match()よりも優れています。
2013年9月現在、data.tableはv1.8.10がCRANにあり、v1.9.0に取り組んでいます。 ニュース はライブで更新されます。
しかし、元々書いたように、上記.
data.tableがあります。 時系列結合 を念頭に置いています。それには2つの側面があります:i) マルチカラム オーダーメイド (id,datetime)のようなキー ii) 高速な優先順位付け を結合する (roll=TRUE)、すなわち、最後の観測が繰り越される。
ですから、2つの文字列のPandas equi joinは、おそらくまだdata.tableより速いでしょう。2つのカラムを結合したものをハッシュしているようですが、data.tableは順序付き結合を念頭に置いているので、キーをハッシュしているわけではありません。data.tableにおけるquot;key"は文字通りソート順です(SQLにおけるクラスタ化インデックスに似ています;つまり、RAM上のデータの並び方です)。リストにあるのは、例えばセカンダリキーを追加することです。
要約すると、1万を超えるユニークな文字列を含むこの2文字列のテストによって明らかになった速度の差は、既知の問題が修正されたため、今ではそれほどひどくないはずです。
関連
-
[解決済み] データ型が理解できない
-
[解決済み】「OverflowError: Python int too large to convert to C long" on windows but not mac
-
[解決済み] Python 3で「1000000000000000 in range(1000000000000001)」はなぜ速いのですか?
-
[解決済み] なぜC++はPythonよりもstdinからの行の読み込みが遅いのですか?
-
[解決済み] Pythonのクラスはなぜオブジェクトを継承するのですか?
-
[解決済み] 既存のDataFrameに新しい列を追加する方法は?
-
[解決済み] なぜPythonのコードは関数の中でより速く実行されるのですか?
-
[解決済み] なぜ[]はlist()よりも速いのですか?
-
[解決済み】なぜPythonはこのJSONデータをパースできないのですか?[終了] PythonがこのJSONデータをパースできないのはなぜですか?
-
[解決済み】data.table vs dplyr:一方がうまくできない、またはうまくできないことを行うことができますか?
最新
-
nginxです。[emerg] 0.0.0.0:80 への bind() に失敗しました (98: アドレスは既に使用中です)
-
htmlページでギリシャ文字を使うには
-
ピュアhtml+cssでの要素読み込み効果
-
純粋なhtml + cssで五輪を実現するサンプルコード
-
ナビゲーションバー・ドロップダウンメニューのHTML+CSSサンプルコード
-
タイピング効果を実現するピュアhtml+css
-
htmlの選択ボックスのプレースホルダー作成に関する質問
-
html css3 伸縮しない 画像表示効果
-
トップナビゲーションバーメニュー作成用HTML+CSS
-
html+css 実装 サイバーパンク風ボタン
おすすめ
-
Python関数の高度な応用を解説
-
Python jiabaライブラリの使用方法について説明
-
PyQt5はユーザーログインGUIインターフェースとログイン後のジャンプを実装しています。
-
風力制御におけるKS原理を深く理解するためのpythonアルゴリズム
-
PythonでECDSAを実装する方法 知っていますか?
-
[解決済み】ImportError: sklearn.cross_validation という名前のモジュールがない。
-
[解決済み】「RuntimeError: dictionary changed size during iteration」エラーを回避する方法とは?
-
[解決済み] データ型が理解できない
-
[解決済み】「SyntaxError.Syntax」は何ですか?Missing parentheses in call to 'print'」はPythonでどういう意味ですか?
-
[解決済み】django インポートエラー - core.managementという名前のモジュールがない